时间: 2022年4月1日
内容:学习MM Segmentation
MM Segmentation 介绍和理解
MM Segmentation 利用注册器和配置文件,实现了 可拓展性 和 易用性。
它是一个封装了许多语义分割深度神经网络的框架,下载好之后是一个project,放入自己的数据集,或者利用官网(链接在下方)并选择深度神经网络,就可以实现各种语义分割模型。
注册器:Dataset、Pipeline、(数据预处理流程)、Model在定义的过程中都使用注册器。字典保存了已定义的模型、数据集等,字典的键为类名,值为对应的类。
若要添加新的类,只要在定义类时使用注册器类,就能自动将新类添加到字典中。
配置文件:用户可以通过配置文件,修改或添加数据集、预处理流程、网络模型和训练流程。
下面按照我的理解进行简单的介绍:
配置文件的路径在mmsegmentation/config/_base_中,里面有四个文件/文件夹:
其中,
datasets里面是可用的数据集格式,在所用的数据集对应的文件中修改配置;
models里面是可用的深度网络模型;
schedules里面是训练的配置,分为20k 40k 60k等,对应具体的深度神经网络模型;
default_runtime.py是默认运行时间。
额外说一下,config/xxxmodel/xxx_xxx.py和config/base/models/xxx.py
前者是以要用的具体的网络文件命名的,里面配置要用到的文件;
后者是具体的执行文件,显然,在前者里面要调用后者,并调用一些数据集等文件,以deeplabv3为例:
deeplabv3_r50-d8_512x512_20k_voc12aug.py :
_base_ = [
'../_base_/models/deeplabv3_r50-d8.py',
'../_base_/datasets/pascal_voc12.py', '../_base_/default_runtime.py',
'../_base_/schedules/schedule_20k.py'
]
model = dict(
decode_head=dict(num_classes=5), auxiliary_head=dict(num_classes=5))deeplabv3_r50_d8.py:
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='ASPPHead',
in_channels=2048,
in_index=3,
channels=512,
dilations=(1, 12, 24, 36),
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))整体的文件框架如下: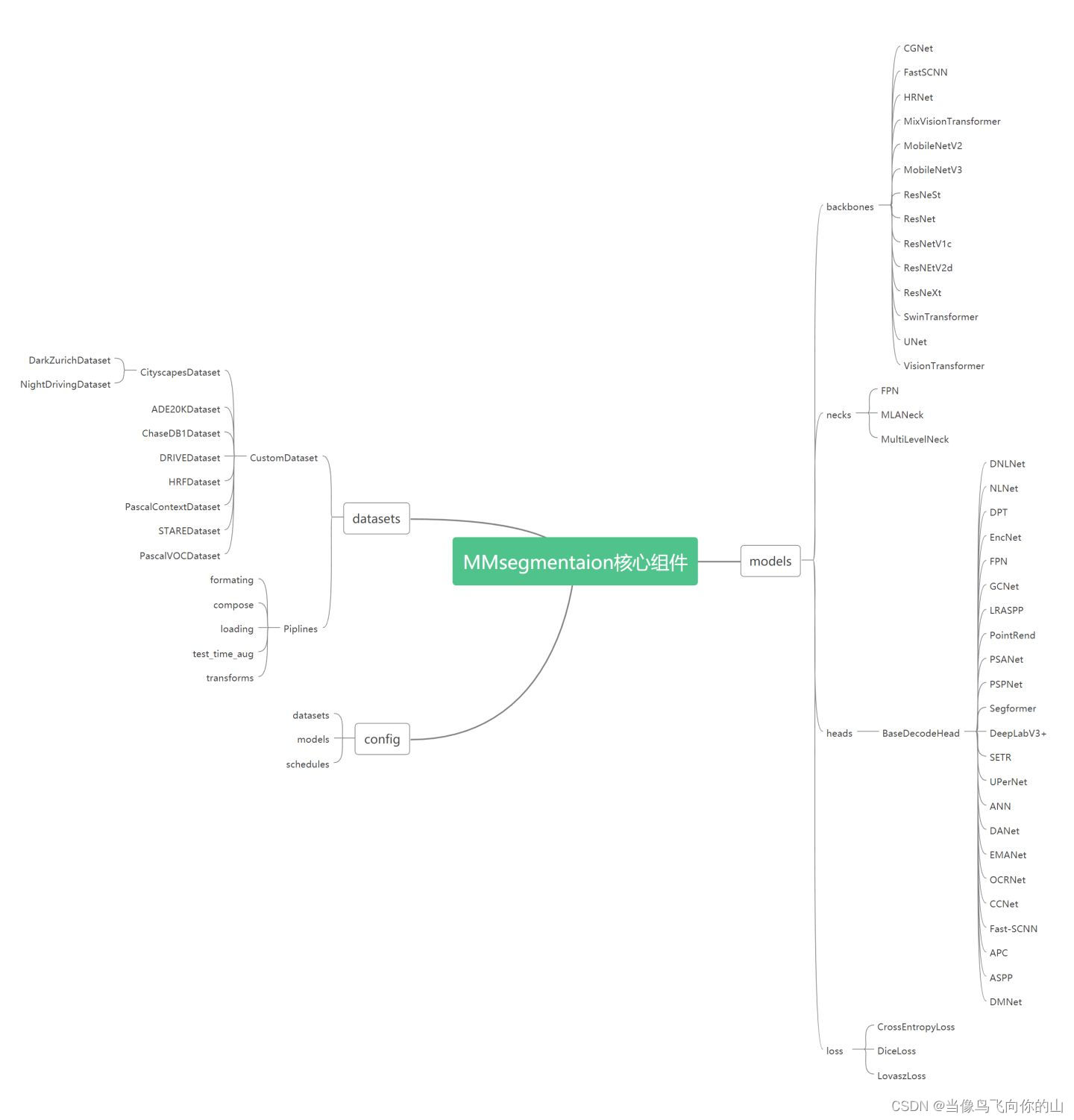
具体使用:(用下面的方法我没跑通,下一篇讲mmsegmentation的训练)
https://zhuanlan.zhihu.com/p/393070556
额外:
labelme仓库:
https://gitcode.net/mirrors/wkentaro/labelme?utm_source=csdn_github_accelerator
安装:
pytorch,如果你也是服务器上,可以参考我的上一篇文章:
https://blog.csdn.net/qq_43507388/article/details/123870298
mmsegmentation仓库 及 安装指南:
https://github.com/open-mmlab/mmcv#installation
安装建议按照官网的教程,不建议参考网上的博客,这是官网:
https://mmsegmentation.readthedocs.io/en/latest/get_started.html#installation
详细的步骤我就不搬过来了。
假设已经装好了pytorch和torchvision和cuda,依次执行如下命令(来自官网):
conda create -n open-mmlab python=3.10 -y
conda activate open-mmlab
conda install pytorch=1.11.0 torchvision cudatoolkit=11.3 -c pytorch
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
git clone https://github.com/open-mmlab/mmsegmentation.git
cd mmsegmentation
pip install -e . # or "python setup.py develop"
mkdir data
ln -s $DATA_ROOT datapython pytorch cuda 注意要换成你的版本,最后两行是建立data文件夹和数据集软链接。
我的血泪史,跑不起来应该是代码不对,不要轻易重装,不然时间都花在重装上了。
参考:
https://blog.csdn.net/jiaoyangwm/article/details/114373269
https://blog.csdn.net/qq_20549061/article/details/107871736