计算机中,任何的文字都是以指定的编码方式存在的,在 Java 程序的开发中最常见的是ISO8859-1、GBK/GB2312、Unicode、UTF 编码。
Java 中常见编码说明如下:
- ISO8859-1:属于单字节编码,最多只能表示 0~255 的字符范围。
- GBK/GB2312:中文的国标编码,用来表示汉字,属于双字节编码。GBK 可以表示简体中文和繁体中文,而 GB2312只能表示简体中文。GBK 兼容 GB2312。
- Unicode:是一种编码规范,是为解决全球字符通用编码而设计的。UTF-8 和 UTF-16 是这种规范的一种实现,此编码不兼容ISO8859-1 编码。Java 内部采用此编码。
- UTF:UTF 编码兼容了 ISO8859-1 编码,同时也可以用来表示所有的语言字符,不过 UTF 编码是不定长编码,每一个字符的长度为1~6 个字节不等。一般在中文网页中使用此编码,可以节省空间。
在程序中如果处理不好字符编码,就有可能出现乱码问题。例如现在本机的默认编码是 GBK,但在程序中使用了 ISO8859-1 编码,则就会出现字符的乱码问题。就像两个人交谈,一个人说中文,另外一个人说英语,语言不同就无法沟通。为了避免产生乱码,程序编码应与本地的默认编码保持一致。
本地的默认编码可以使用 System 类查看。Java 中 System 类可以取得与系统有关的信息,所以直接使用此类可以找到系统的默认编码。方法如下所示:
publicstatic PropertiesgetProperty()使用上述方法可以查看 JVM 的默认编码,代码如下:
publicstaticvoidmain(String[] args){// 获取当前系统编码
System.out.println("系统默认编码:"+ System.getProperty("file.encoding"));}运行结果如下:
系统默认编码:GBK可以看出,现在操作系统的默认编码是 GBK。
下面通过一个示例讲解乱码的产生。现在本地的默认编码是 GBK,下面通过 ISO8859-1 编码对文字进行编码转换。如果要实现编码的转换可以使用 String 类中的getBytes(String charset) 方法,此方法可以设置指定的编码,该方法的格式如下:
publicbyte[]getBytes(String charset);示例代码如下:
import java.io.File;import java.io.FileOutputStream;import java.io.OutputStream;publicclassTest{publicstaticvoidmain(String[] args){
File f=newFile("C:"+File.separator+"test.txt");try{//实例化输出流
OutputStream out=newFileOutputStream(f);//指定ISO8859-1编码byte[] b="秀儿,我是你爸爸!".getBytes("ISO8859-1");//保存转码之后的数据
out.write(b);//关闭输出流
out.close();}catch(Exception e){
e.printStackTrace();}}}运行结果如下: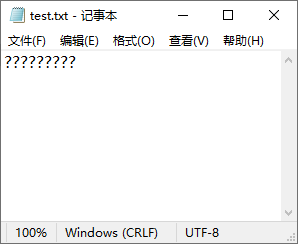
可以发现,因为编码不一致,所以在保存时出现了乱码。在 Java 的开发中,乱码是一个比较常见的问题,乱码的产生就有一个原因,即输出内容的编码与接收内容的编码不一致。