前言:
博主使用的显卡配置为:2*RTX 2080Ti,最近在训练的时候,监控显卡的资源使用情况发现,
虽然同是使用了两张显卡,但是每张显卡的使用率很不稳定,貌似是交替使用,这种情况下训练的速度是很慢的,为了解决
下面是解决这个问题的一些过程。
1. CPU和内存的使用情况
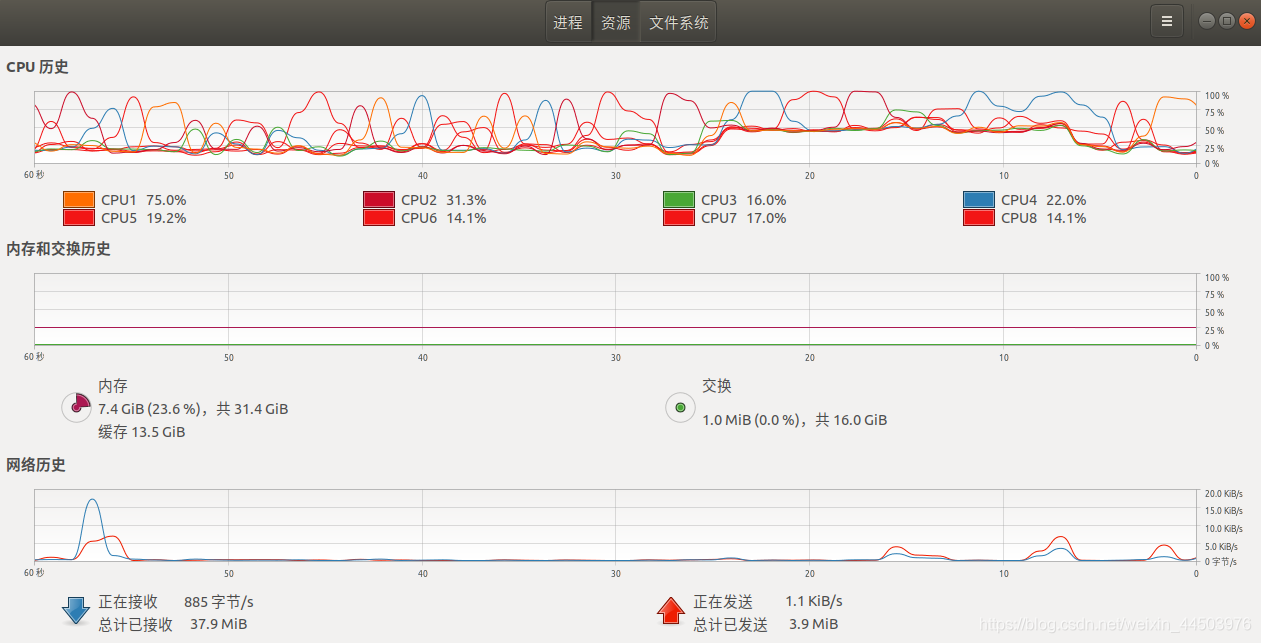
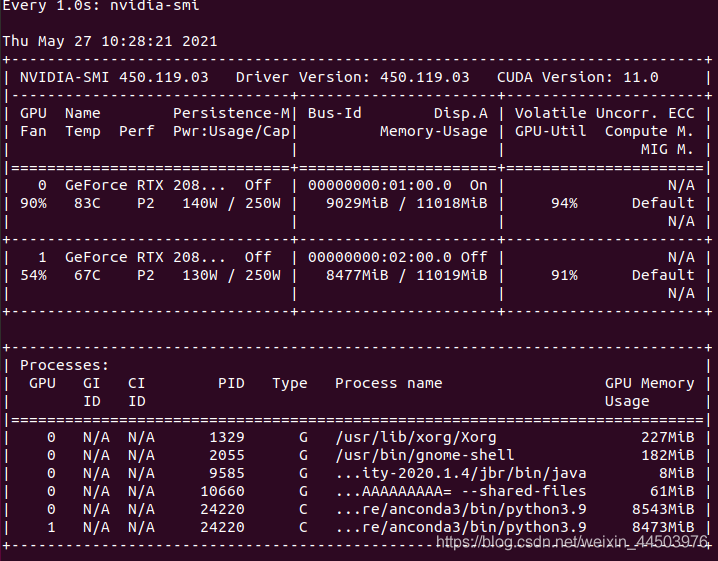
2. 用linux命令查看显卡资源的使用情况
watch -n 1 nvidia-smi
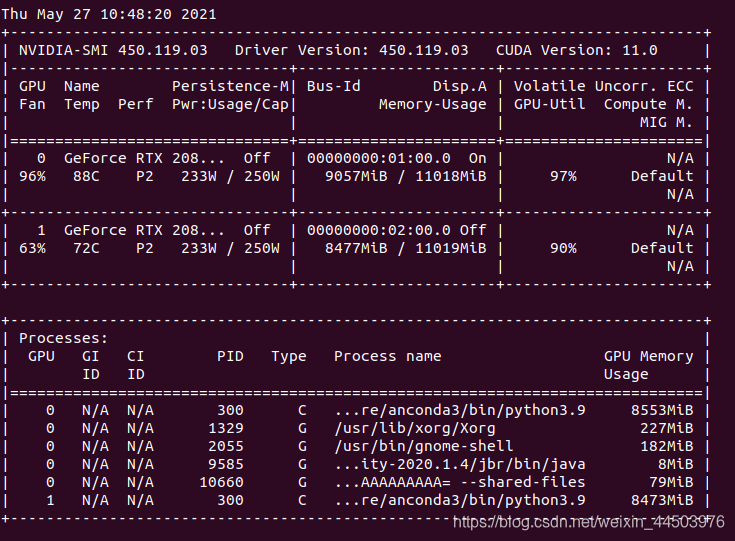
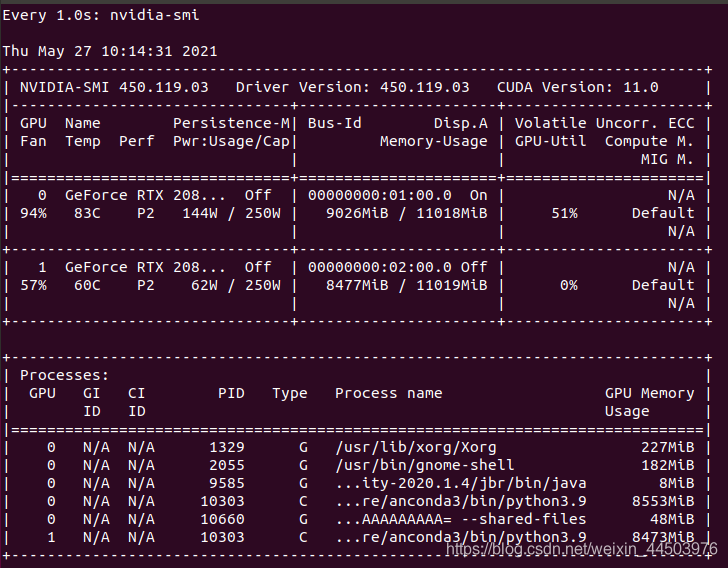
模型执行预测阶段 使用显卡0,但是也只有51%的使用率。
模型在训练阶段,同时使用两张显卡,发现里利用率也不高,我截取的最高的也就60%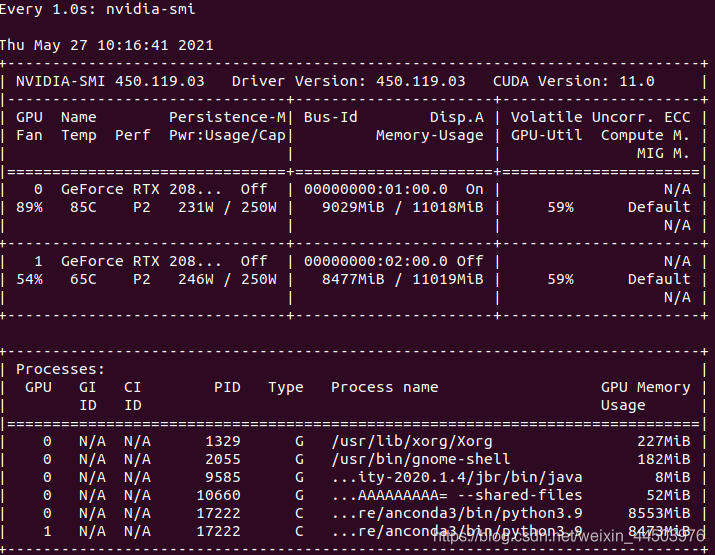
3. 在pytorch的文档中找到了解决办法
data.DataLoader(dataset: Dataset[T_co],batch_size: Optional[int] = 1,shuffle: bool = False, sampler: Optional[Sampler[int]] = None, batch_sampler: Optional[Sampler[Sequence[int]]] = None,num_workers: int = 0, collate_fn: _collate_fn_t = None,pin_memory: bool = False, drop_last: bool = False, timeout: float = 0, worker_init_fn: _worker_init_fn_t = None, multiprocessing_context=None, generator=None, *, prefetch_factor: int = 2, persistent_workers: bool = False)
上面是该类的输入参数,经常使用的用红色标出,与本文相关的设置用紫色标出,下面是该类的描述文件:
class DataLoader(Generic[T_co]):
r"""
Data loader. Combines a dataset and a sampler, and provides an iterable over
the given dataset.
The :class:`~torch.utils.data.DataLoader` supports both map-style and
iterable-style datasets with single- or multi-process loading, customizing
loading order and optional automatic batching (collation) and memory pinning.
See :py:mod:`torch.utils.data` documentation page for more details.
Args:
dataset (Dataset): dataset from which to load the data.
batch_size (int, optional): how many samples per batch to load
(default: ``1``).
shuffle (bool, optional): set to ``True`` to have the data reshuffled
at every epoch (default: ``False``).
sampler (Sampler or Iterable, optional): defines the strategy to draw
samples from the dataset. Can be any ``Iterable`` with ``__len__``
implemented. If specified, :attr:`shuffle` must not be specified.
batch_sampler (Sampler or Iterable, optional): like :attr:`sampler`, but
returns a batch of indices at a time. Mutually exclusive with
:attr:`batch_size`, :attr:`shuffle`, :attr:`sampler`,
and :attr:`drop_last`.
num_workers (int, optional): how many subprocesses to use for data
loading. ``0`` means that the data will be loaded in the main process.
(default: ``0``)
collate_fn (callable, optional): merges a list of samples to form a
mini-batch of Tensor(s). Used when using batched loading from a
map-style dataset.
pin_memory (bool, optional): If ``True``, the data loader will copy Tensors
into CUDA pinned memory before returning them. If your data elements
are a custom type, or your :attr:`collate_fn` returns a batch that is a custom type,
see the example below.
drop_last (bool, optional): set to ``True`` to drop the last incomplete batch,
if the dataset size is not divisible by the batch size. If ``False`` and
the size of dataset is not divisible by the batch size, then the last batch
will be smaller. (default: ``False``)
timeout (numeric, optional): if positive, the timeout value for collecting a batch
from workers. Should always be non-negative. (default: ``0``)
worker_init_fn (callable, optional): If not ``None``, this will be called on each
worker subprocess with the worker id (an int in ``[0, num_workers - 1]``) as
input, after seeding and before data loading. (default: ``None``)
prefetch_factor (int, optional, keyword-only arg): Number of samples loaded
in advance by each worker. ``2`` means there will be a total of
2 * num_workers samples prefetched across all workers. (default: ``2``)
persistent_workers (bool, optional): If ``True``, the data loader will not shutdown
the worker processes after a dataset has been consumed once. This allows to
maintain the workers `Dataset` instances alive. (default: ``False``)
.. warning:: If the ``spawn`` start method is used, :attr:`worker_init_fn`
cannot be an unpicklable object, e.g., a lambda function. See
:ref:`multiprocessing-best-practices` on more details related
to multiprocessing in PyTorch.
.. warning:: ``len(dataloader)`` heuristic is based on the length of the sampler used.
When :attr:`dataset` is an :class:`~torch.utils.data.IterableDataset`,
it instead returns an estimate based on ``len(dataset) / batch_size``, with proper
rounding depending on :attr:`drop_last`, regardless of multi-process loading
configurations. This represents the best guess PyTorch can make because PyTorch
trusts user :attr:`dataset` code in correctly handling multi-process
loading to avoid duplicate data.
However, if sharding results in multiple workers having incomplete last batches,
this estimate can still be inaccurate, because (1) an otherwise complete batch can
be broken into multiple ones and (2) more than one batch worth of samples can be
dropped when :attr:`drop_last` is set. Unfortunately, PyTorch can not detect such
cases in general.
See `Dataset Types`_ for more details on these two types of datasets and how
:class:`~torch.utils.data.IterableDataset` interacts with
`Multi-process data loading`_.
.. warning:: See :ref:`reproducibility`, and :ref:`dataloader-workers-random-seed`, and
:ref:`data-loading-randomness` notes for random seed related questions.
"""发现如下连个参数很关键:
num_workers (int, optional): how many subprocesses to use for data
loading. ``0`` means that the data will be loaded in the main process.
(default: ``0``)pin_memory (bool, optional): If ``True``, the data loader will copy Tensors
into CUDA pinned memory before returning them. If your data elements
are a custom type, or your :attr:`collate_fn` returns a batch that is a custom type,
see the example below.把num_workers = 4,pin_memory = True,发现效率就上来啦!!!
只开 num_workers
开 num_workers 和 pin_memory