用python拟合对数正态分布使用的是scipy.stats.lognorm这个包,这个包的使用看官方文档就行,但是其中有一个很迷的地方,网上也有人提到了这个很迷的地方:关于scipy对数正态分布的误区,然后Stack Overflow里也有人给出了解释Stack Overflow大佬的解释说明,,其实Stack Overflow和官网都有解释,可能是我的英语还是太差了吧,导致始终觉得需要看好久才能理解,所以这里来记录下这个漏洞以及我给出的例子。官网链接还是必须的,不管其他人写的多清楚,看下官网总没错。
Stack Overflow中的解释说明:
1. 参数的解释
下图是官网的说明,首先对数正态分布的概率密度函数就看下面的就行了。要调用这个包的概率密度函数的参数主要是有如下几个lognorm.pdf(x, s, loc, scale),下面就说明下各个参数的含义:
x也就是自变量,是一个list或series啥的都可以,返回的是每个x处的对数正态分布的概率密度函数。s是形状参数,loc是一个参数,你的数据都会被加上loc,以便使得0成为数据范围的下确界,对方差没有影响。因为对数正态分布嘛,取了对数的,一般都是(0,无穷)。scale类似于标准差,但不是。听我下面的说明。
我们假设一个一维的数组x,这个一维的数组x的分布是对数正态分布。那么要得到这个一维数组x的概率密度函数就可以使用lognorm.pdf(x, s, loc, scale),其中的x可以输入该数组,也可以输入一个自己设置的,比如x1=np.linspace(0,3,200),因为这个是参数估计,所以只要得到参数值,其实就已经确定分布了,这个x就没用了,任何一个一维数组都可以给出对应位置的概率密度值。那么如何根据x得到lognorm.pdf(x, s, loc, scale)中的参数呢?下面一个一个参数来说明:
- s:s=np.std(np.log(x)),也就是先对x求log,得到正态分布的数组,然后对这个正态分布的数组求标准差,这个标准差就是s。
- loc设置为0就可以,用默认值就行,不用去设置。如果源数据有偏移可以设置下loc。这个参数我简单尝试试验了下,但不确定,若有问题,大佬可以指正,谢谢。
- scale:scale=math.exp(np.mean(np.log(x))),也就是说先对x求log,得到正态分布的一维数组,然后对正态分布的x求均值,然后exp(得到的均值)就是scale了。
这里贴上Stack Overflow上的一个例子。
import mathfrom scipyimport stats# standard deviation of normal distribution
sigma=0.859455801705594# mean of normal distribution
mu=0.418749176686875# hopefully, total is the value where you need the cdf
total=37
frozen_lognorm= stats.lognorm(s=sigma, scale=math.exp(mu))
frozen_lognorm.cdf(total)# use whatever function and value you need here下面有个老兄也吐槽scipy的这个参数非人类,哈哈,贴上给大家一乐。
2. 我写的例子,证明上述说明
为了方便我就放图了,反正也很简单,大家看看就完了,我感觉也不必去自己跑了。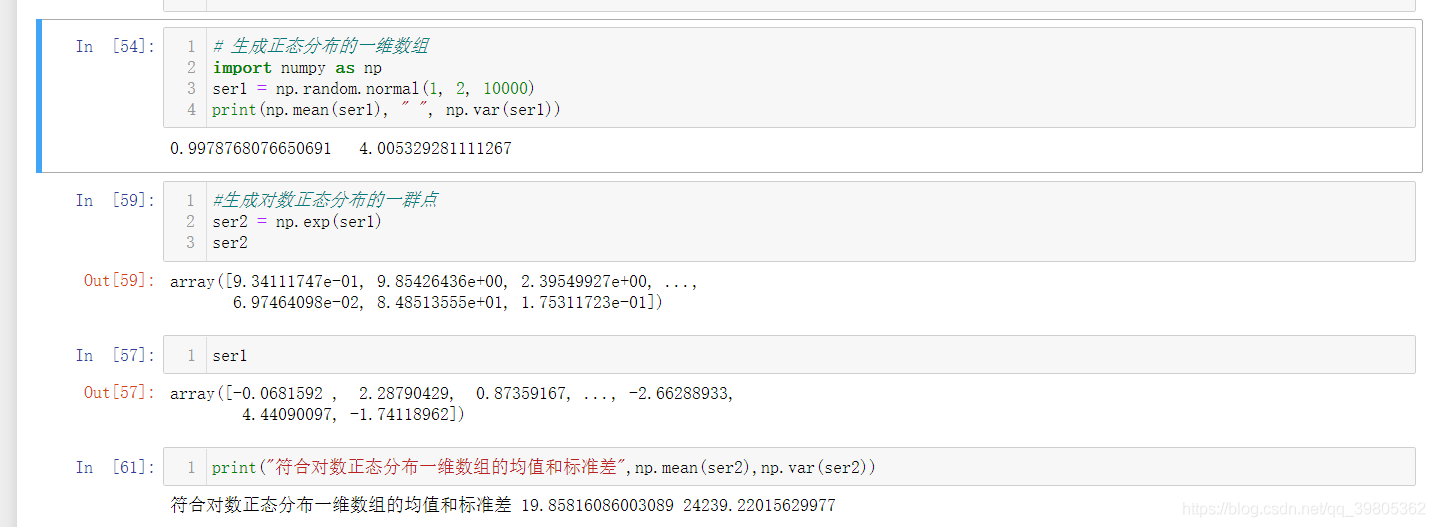

代码如下:
# 生成正态分布的一维数组import numpyas np
ser1= np.random.normal(1,2,10000)print(np.mean(ser1)," ", np.var(ser1))#生成对数正态分布的一群点
ser2= np.exp(ser1)print(ser2)print(ser1)print("符合对数正态分布一维数组的均值和标准差",np.mean(ser2),np.var(ser2))# 验证对数正态分布的均值和方差
mu= math.exp(1+2)
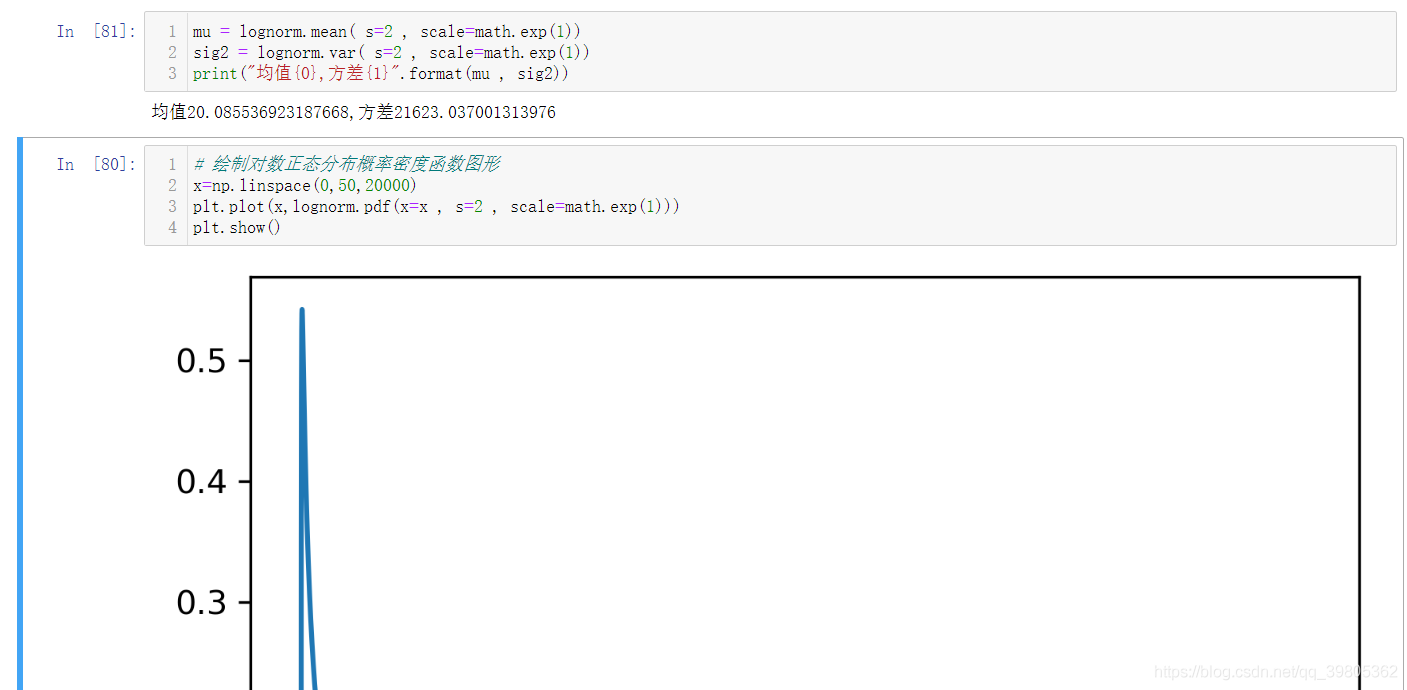
sig2=(math.exp(4)-1)*math.exp(2*1+4)print("均值{0},方差{1}".format(mu, sig2))### 验证成功,方差因为比较大,有一定差异,但是相对误差还是不大的。### 使用lognorm这个函数取输出理论的均值和标准差,### 可以看到和我们计算出的理论值完全一样。### 这既证明理论值是正确的,也证明我们对这个函数的参数的说明是正确的。
mu= lognorm.mean( s=2, scale=math.exp(1))
sig2= lognorm.var( s=2, scale=math.exp(1))print("均值{0},方差{1}".format(mu, sig2))# 绘制对数正态分布概率密度函数图形
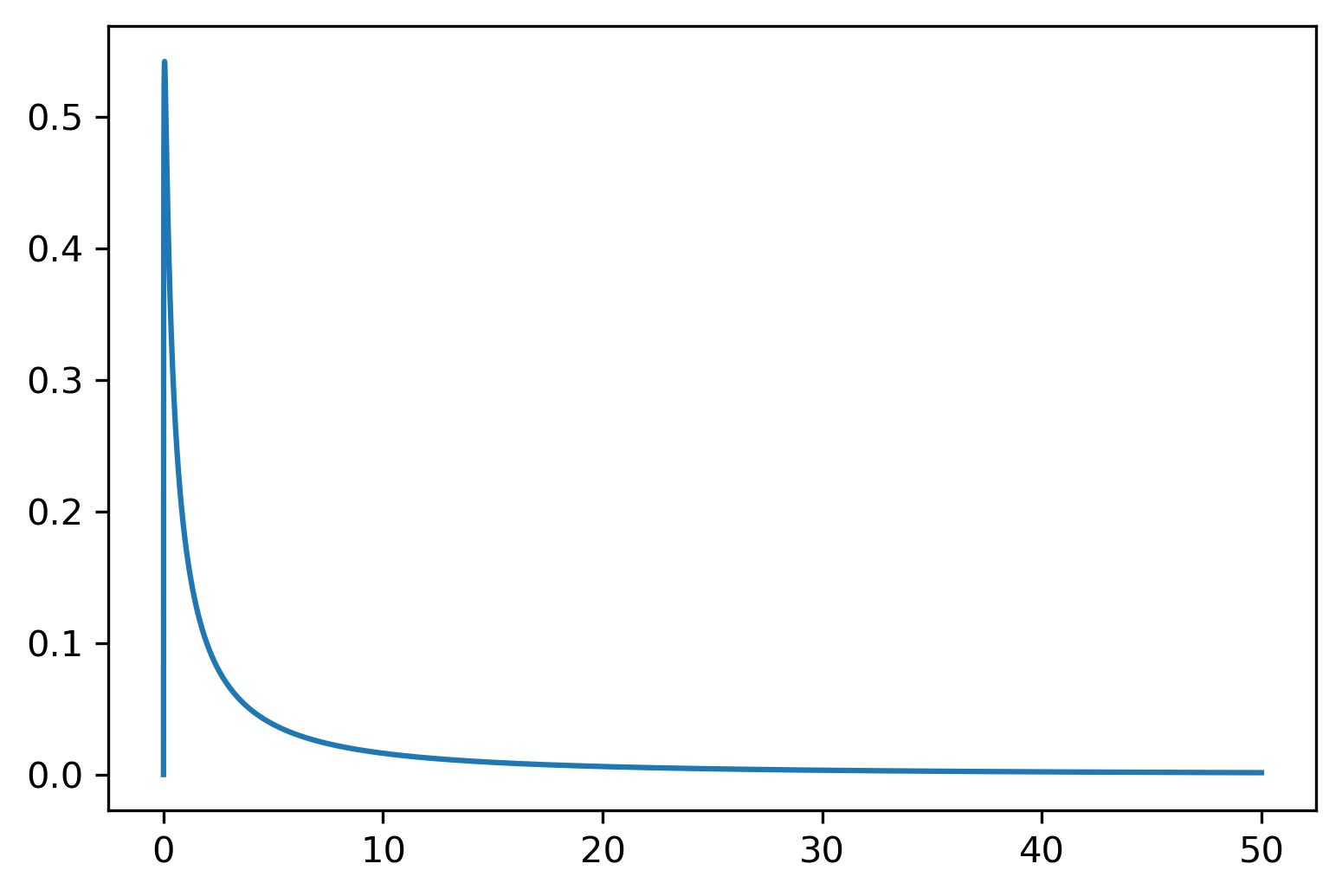
x=np.linspace(0,50,20000)
plt.plot(x,lognorm.pdf(x=x, s=2, scale=math.exp(1)))
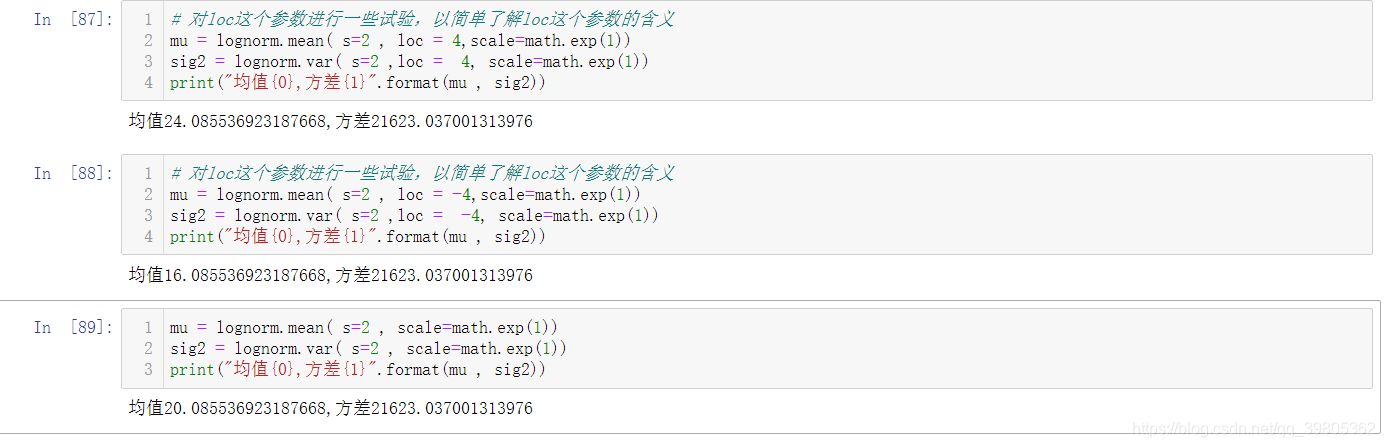
plt.show()# 对loc这个参数进行一些试验,以简单了解loc这个参数的含义
mu= lognorm.mean( s=2, loc=4,scale=math.exp(1))
sig2= lognorm.var( s=2,loc=4, scale=math.exp(1))print("均值{0},方差{1}".format(mu, sig2))# 对loc这个参数进行一些试验,以简单了解loc这个参数的含义
mu= lognorm.mean( s=2, loc=-4,scale=math.exp(1))
sig2= lognorm.var( s=2,loc=-4, scale=math.exp(1))print("均值{0},方差{1}".format(mu, sig2))
mu= lognorm.mean( s=2, scale=math.exp(1))
sig2= lognorm.var( s=2, scale=math.exp(1))print("均值{0},方差{1}".format(mu, sig2))结束啦