摘要:语言模型往往被用于文字识别的后处理阶段,本文将语言模型的先验信息和文字的视觉特征进行交互和增强,从而进一步提升文字识别的性能。
本文分享自华为云社区《Multi-Model Text Recognition Network》,作者:谷雨润一麦 。

语言模型经常被用于文字识别的后处理阶段,用来优化识别结果。但该先验信息是独立作用于识别器的输出,所以之前的方法并没有充分利用该信息。本文提出MATRN,对语义特征和视觉特征之间进行跨模态的特征增强,从而提高识别性能。
方法
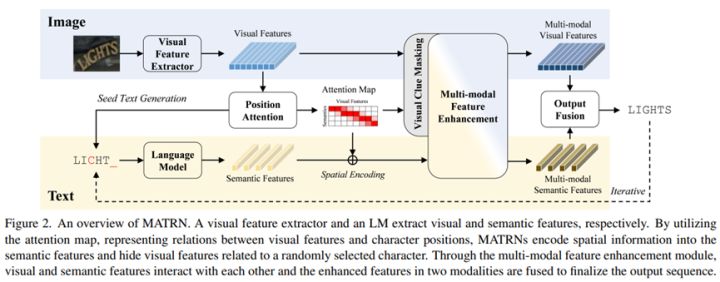
方法的流程图如上图所示,首先图片通过视觉提取器和位置注意力模块得到初步的文字识别结果。然后将该识别结果通过一个预训练好的语言模型,得到文字的语义特征。

接着通过上图左所示的模块,利用transformer进行视觉特征和语义特征的特征增强。最后利用如下公式,将视觉特征和语义特征进行特征融合,并进行最终的分类。
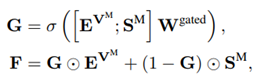
值得注意的是,有感于自监督的方法,本文也提出了一种在视觉特征图上加掩码的方法。具体来说,利用位置注意力模块中的注意力相应图,随机选择某个时刻的注意力权重作为掩码,mask掉一部分视觉特征。
实验结果
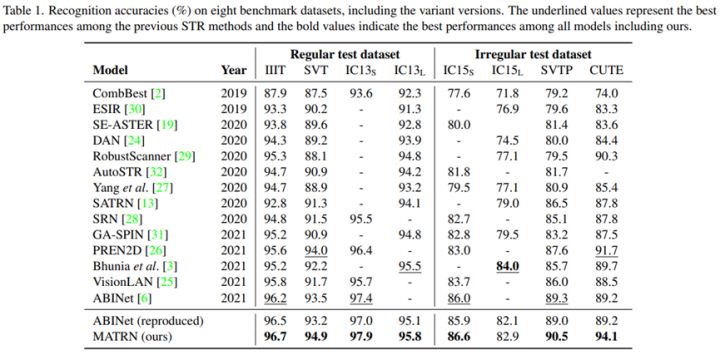
从实验结果可以看出来,该方法在比较困难的不规则图像中有较大提升。这说明当模型很难从视觉上进行识别的时候,文字之间的语义特征有助于识别。