如果不想看文字的,可以在我bilibili上看录制的视频教程:
本教程所涉及的代码可自行在我的github上下载:
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
在pytorch_classification模块下的train_multi_GPU文件夹中。
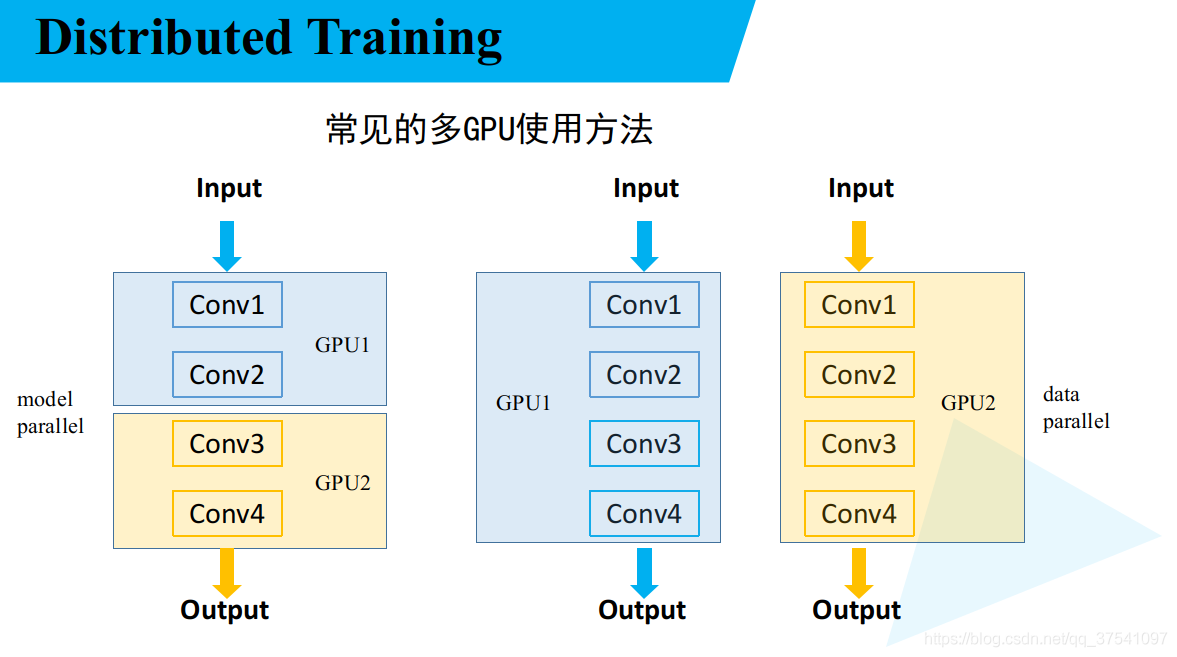
常见多GPU使用方法
在训练模型中,为了加速训练过程,往往会使用多块GPU设备进行并行训练(甚至多机多卡的情况)。如下图所示,常见的多GPU的使用方法有以下两种(但不局限于以下方法):
model parallel,当模型很大,单块GPU的显存不足以放下整个模型时,通常会将模型分成多个部分,每个部分放到不同的GUP设备中(下图左侧),这样就能将原本跑不了的模型利用多块GPU跑起来。但这种情况,一般不能加速模型的训练。data parallel,当模型不是很大可以放入单块GPU时,可以将模型复制到多块GPU上,进行并行加速训练(下图右侧)。这种情况更常见,本文也是以data parallel来进行讲解。
下图展示了使用多块GPU并行加速的训练时间对比。测试环境,Pytorch1.7,CUDA10.1,Model: ResNet34,DataSet: flower_photos,BatchSize: 16,GPU: Tesla V100。通过左侧的柱状图可以看出,使用多GPU的加速并不是简单的线性倍增关系,因为多GPU并行训练时会涉及多GPU之间的通信。
多GPU并行训练过程中需要注意的事项
以下说的注意事项,虽然Pytorch框架已为我们实现了,但是我们需要知道有这些工作。
- 数据如何分配至各设备当中。使用多GPU并行训练时,通常每个GPU只负责整个数据集中的某一部分。
- 误差梯度如何在不同的设备之间进行通信。每次多块GPU设备正向传播一批数据后,在误差反向传播时每个GPU设备都会计算出针对各输入数据在各参数的误差梯度(
Gradient如下图右侧所示),此时不要急着去更新各参数,而是先去对各设备上各参数的误差梯度求均值(可理解为融合各设备上学习的知识),然后再去更新各设备上参数。
- BatchNormalization如何在不同设备间同步。关于BN理论知识不在本文介绍范围内,如果不了解的可以查看我之前写的一篇文章,Batch Normalization理论详解。如果不考虑多设备之间的BN通信的话,每个设备只去计算每个BN层针对该设备输入数据的均值和方差。假如每个设备的
batch_size为2,则每个BN层计算的均值和方差只是针对2个样本的。之前在讲BN理论时有说过,一般batch_size设置越大效果越好,那么如果我们在计算BN层的均值和方差时能够同步多块GPU上的统计信息,那batch_size不就相当于倍增了?确实如此,在Pytorch中也有提供具有同步BN的方法SyncBatchNorm。当GPU显存有限,每个设备上的batch_size设置很小时,通过使用具有同步功能的BN层时是能够提升模型最终的mAP的,但如果每个设备上的batch_size设置的已经很大了,那么个人感觉同步的BN就没太大作用了。注意:如果使用具有同步功能的BN,会降低模型的训练速度,因为在每个BN层处都需要去同步参数,所以会更耗时。
下图展示了使用单GPU训练,多GPU训练(使用SyncBatchNorm和不使用SyncBatchNorm)的训练曲线。通过以下曲线可以看出,使用多GPU训练(不使用SyncBatchNorm)和单GPU的训练结果是差不多的(但多GPU训练更快)。但使用了SyncBatchNorm比不使用SyncBatchNorm能达到的最好mAP要高一点。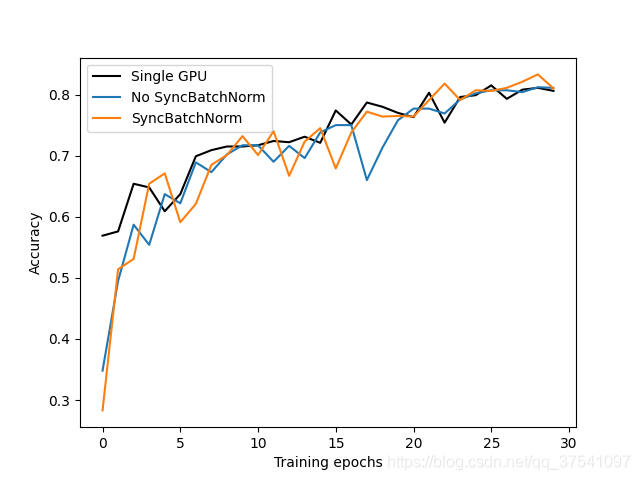
Pytorch中提供的两种多GPU训练方法
在Pytorch当中,提供了两种多GPU的训练方法,一种是DataParallel一种是DistributedDataParallel,前者是官方较早提供的一种方法,后者是现在官方比较推荐的一种方法。本文也主要是讲DistributedDataParallel。下图是我从官方教程中截取的一段对比这两种方法的文献。
首先DataParallel是单进程多线程的方法,并且仅能工作在单机多卡的情况。而DistributedDataParallel方法是多进程,多线程的,并且适用与单机多卡和多机多卡的情况。即使在在单机多卡的情况下DistributedDataParallell也比DataParallel的速度更快。
本文只介绍单机多卡的情况。

Pytorch中多GPU常用启动方式
在Pytorch中使用多GPU的常用启动方式一种是torch.distributed.launch一种是torch.multiprocessing模块。这两种方式各有各的好处,在我使用过程中,感觉torch.distributed.launch启动方式更方便,而且我看官方提供的多GPU训练FasterRCNN源码就是使用的torch.distributed.launch方法,所以我个人也比较喜欢这个方法。但在官方的教程中主要还是使用的torch.multiprocessing方法,官方说这种方法具有更好的控制和灵活性。在自己使用体验过程中确实和官方说的一样。
这里提醒下要使用torch.distributed.launch启动方式的小伙伴。训练过程中如果你强行终止的程序,在开启下次训练前建议你通过nvidia-smi指令看下你GPU的显存是否全部释放了,如果没有全部释放,需要手动杀下进程。在我使用过程中发现强行终止程序有小概率出现进程假死的情况,占用的GPU的资源并没有及时释放,如果在下次训练前没有及时释放,会影响你的训练,或者直接提示通信端口被占用,无法启动的情况。
在我提供的代码中,分别提供了对应这两种方式的训练脚本。torch.distributed.launch对应的是train_multi_gpu_using_launch.py脚本,torch.multiprocessing对应的是train_multi_gpu_using_spawn.py脚本。
train_multi_gpu_using_launch.py脚本讲解
该代码是在之前所讲的知识基础上进行扩展的,其中涉及resnet模型的搭建以及自定义数据集,这里就不在赘述,如果需要了解的可以看下我之前的视频:
这里只是针对其中我个人觉得比较重要的地方说一下,如果想看整个代码的详细讲解,可以去看下本文开头提供的视频链接。
- 首先说下
init_distributed_mode函数,该函数是用来初始化各进程的:
definit_distributed_mode(args):if'RANK'in os.environand'WORLD_SIZE'in os.environ:
args.rank=int(os.environ["RANK"])
args.world_size=int(os.environ['WORLD_SIZE'])
args.gpu=int(os.environ['LOCAL_RANK'])else:print('Not using distributed mode')
args.distributed=Falsereturn
args.distributed=True
torch.cuda.set_device(args.gpu)
args.dist_backend='nccl'# 通信后端,nvidia GPU推荐使用NCCLprint('| distributed init (rank {}): {}'.format(
args.rank, args.dist_url), flush=True)
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
dist.barrier()在使用torch.distributed.launch --use_env指令启动时,会自动在python的os.environ中写入RANK、WORLD_SIZE、LOCAL_RANK信息。
- 在单机多卡的情况下,
WORLD_SIZE代表着使用进程数量(一个进程对应一块GPU),这里RANK和LOCAL_RANK这里的数值是一样的,代表着WORLD_SIZE中的第几个进程(GPU)。 - 在多机多卡的情况下,
WORLD_SIZE代表着所有机器中总进程数(一个进程对应一块GPU),RANK代表着是在WORLD_SIZE中的哪一个进程,LOCAL_RANK代表着当前机器上的第几个进程(GPU)。
所以在init_distributed_mode函数中会读取os.environ中的参数RANK、WORLD_SIZE、LOCAL_RANK信息。通过读取这些信息,就知道了自己是第几个线程,应该使用哪块GPU设备。通过torch.cuda.set_device()方法设置当前使用的GPU设备。然后使用dist.init_process_group()方法去初始化进程组,其中backend为通信后端,如果使用的是Nvidia的GPU建议使用NCCL;init_method为初始化方法,这里直接使用默认的env://当然也支持TCP或者指像某一共享文件;world_size这里就是该进程组的进程数(一个进程负责一块GPU设备);rank这里就是进程组中的第几个进程。
- 代码中有很多rank判断,例如:
if rank==0:# 在第一个进程中打印信息,并实例化tensorboardprint(args)print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer= SummaryWriter()if os.path.exists("./weights")isFalse:
os.makedirs("./weights")这些判断的作用是将一些读写操作全部放到第一个进程中(即rank=0)进行处理,防止在不同进程中进行反复操作引发一些问题。
- 接着说下
torch.utils.data.distributed.DistributedSampler方法的作用,前面有提到过多GPU训练时需要将数据分配到各GPU上,这里的DistributedSampler就是干这件事的。有兴趣的可以去看下源码,代码很少理解起来也不困难。下面这幅图是我个人理解的划分数据集流程:
首先对数据集进行顺序的打乱,然后根据GPU的数量对数据进行补充。假设数据集里有11个样本,一共使用2块GPU设备,那么11 / 2向上取整是6再乘以GPU的数量等于12那么还差一个样本,我们就将打乱顺序后的数据的第一个样本复制一份补充到数据集最后正好就12个样本了。最后将数据交叉间隔着分配给给个GPU设备,这样就将整个数据集分配到各GPU上了,各使用各自分配的数据互不干扰。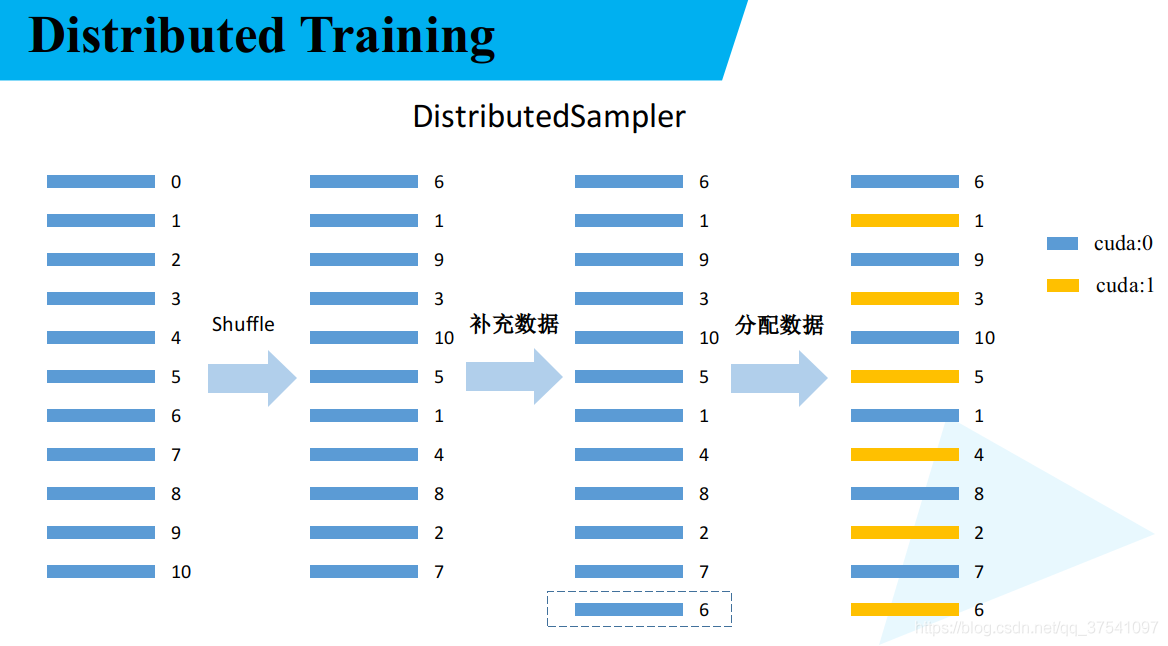
- 接着说下
torch.utils.data.BatchSampler方法的作用,该方法就是将torch.utils.data.distributed.DistributedSampler方法分配好的数据组合成一个个batch。如下图所示,假设batch_size等于2,按照分配好的数据以及给定的batch_size将数据组合一组一组的。在后面的torch.utils.data.DataLoader中我们能够通过指定batch_sampler这个参数,每次取batch_size个数据时就从torch.utils.data.BatchSampler组合好的一组组数据中去取。

- 接着说下如何将模型中的普通BN层转为具有同步功能的BN层,其实也很简单,只要通过下面这行代码Pytorch就会自动将模型中的所有BN层转为
SyncBatchNorm,需要注意的是使用SyncBatchNorm后会降低训练速度。
# 使用SyncBatchNorm后训练会更耗时
model= torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)- 接着说本文的主角
torch.nn.parallel.DistributedDataParallel,通过该方法会将普通的模型转为DDP模型,转为DDP模型后在误差反向传播时会自动对每块GPU设备上的参数梯度求平均。
# 转为DDP模型
model= torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])- 最后说下如何对多块GPU上数据求平均(例如loss),主要通过下面这个方法,注意这里输入的value必须是一个tensor,通过
dist.all_reduce方法会在所有GPU设备上求得该值的和,然后将该值除以world_size就得到了该值在所有设备上的均值了。注意,这里对多个设备上的loss求平均不是为了backward,仅仅是查看做个记录。这里有很多人误认为,在使用多GPU时需要先求平均损失然后在反向传播,其实不是的。应该是每个GPU设备计算出各批次数据的损失后,通过backward方法计算出各参数的损失梯度,然后DDP会自动帮我们在多个GPU设备上对各参数的损失梯度求平均,最后通过optimizer.step()去更新各参数。
defreduce_value(value, average=True):
world_size= get_world_size()if world_size<2:# 单GPU的情况return valuewith torch.no_grad():
dist.all_reduce(value)if average:
value/= world_sizereturn valueAll-Reduce操作如下如所示: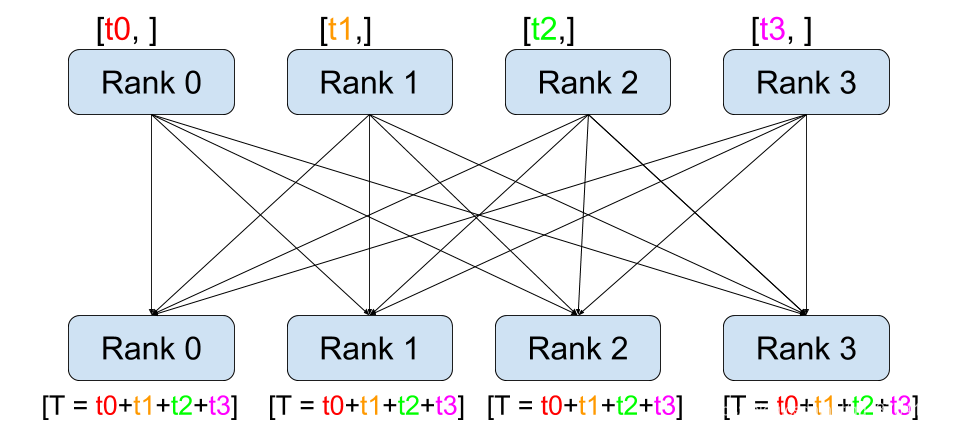
最后给出该脚本的所有代码,为了方便大家理解,里面我已经做了大量注释。如果要跑该脚本需要克隆整个项目,因为该脚本还引入了其他函数(例如模型,自定义数据集部分等)。
import osimport mathimport tempfileimport argparseimport torchimport torch.optimas optimimport torch.optim.lr_scheduleras lr_schedulerfrom torch.utils.tensorboardimport SummaryWriterfrom torchvisionimport transformsfrom modelimport resnet34from my_datasetimport MyDataSetfrom utilsimport read_split_data, plot_data_loader_imagefrom multi_train_utils.distributed_utilsimport init_distributed_mode, dist, cleanupfrom multi_train_utils.train_eval_utilsimport train_one_epoch, evaluatedefmain(args):if torch.cuda.is_available()isFalse:raise EnvironmentError("not find GPU device for training.")# 初始化各进程环境
init_distributed_mode(args=args)
rank= args.rank
device= torch.device(args.device)
batch_size= args.batch_size
num_classes= args.num_classes
weights_path= args.weights
args.lr*= args.world_size# 学习率要根据并行GPU的数量进行倍增if rank==0:# 在第一个进程中打印信息,并实例化tensorboardprint(args)print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer= SummaryWriter()if os.path.exists("./weights")isFalse:
os.makedirs("./weights")
train_images_path, train_images_label, val_images_path, val_images_label= read_split_data(args.data_path)
data_transform={"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])}# 实例化训练数据集
train_data_set= MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])# 实例化验证数据集
val_data_set= MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])# 给每个rank对应的进程分配训练的样本索引
train_sampler= torch.utils.data.distributed.DistributedSampler(train_data_set)
val_sampler= torch.utils.data.distributed.DistributedSampler(val_data_set)# 将样本索引每batch_size个元素组成一个list
train_batch_sampler= torch.utils.data.BatchSampler(
train_sampler, batch_size, drop_last=True)
nw=min([os.cpu_count(), batch_sizeif batch_size>1else0,8])# number of workersif rank==0:print('Using {} dataloader workers every process'.format(nw))
train_loader= torch.utils.data.DataLoader(train_data_set,
batch_sampler=train_batch_sampler,
pin_memory=True,
num_workers=nw,
collate_fn=train_data_set.collate_fn)
val_loader= torch.utils.data.DataLoader(val_data_set,
batch_size=batch_size,
sampler=val_sampler,
pin_memory=True,
num_workers=nw,
collate_fn=val_data_set.collate_fn)# 实例化模型
model= resnet34(num_classes=num_classes).to(device)# 如果存在预训练权重则载入if os.path.exists(weights_path):
weights_dict= torch.load(weights_path, map_location=device)
load_weights_dict={k: vfor k, vin weights_dict.items()if model.state_dict()[k].numel()== v.numel()}
model.load_state_dict(load_weights_dict, strict=False)else:
checkpoint_path= os.path.join(tempfile.gettempdir(),"initial_weights.pt")# 如果不存在预训练权重,需要将第一个进程中的权重保存,然后其他进程载入,保持初始化权重一致if rank==0:
torch.save(model.state_dict(), checkpoint_path)
dist.barrier()# 这里注意,一定要指定map_location参数,否则会导致第一块GPU占用更多资源
model.load_state_dict(torch.load(checkpoint_path, map_location=device))# 是否冻结权重if args.freeze_layers:for name, parain model.named_parameters():# 除最后的全连接层外,其他权重全部冻结if"fc"notin name:
para.requires_grad_(False)else:# 只有训练带有BN结构的网络时使用SyncBatchNorm采用意义if args.syncBN:# 使用SyncBatchNorm后训练会更耗时
model= torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)# 转为DDP模型
model= torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])# optimizer
pg=[pfor pin model.parameters()if p.requires_grad]
optimizer= optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=0.005)# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf=lambda x:((1+ math.cos(x* math.pi/ args.epochs))/2)*(1- args.lrf)+ args.lrf# cosine
scheduler= lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)for epochinrange(args.epochs):
train_sampler.set_epoch(epoch)
mean_loss= train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
scheduler.step()
sum_num= evaluate(model=model,
data_loader=val_loader,
device=device)
acc= sum_num/ val_sampler.total_sizeif rank==0:print("[epoch {}] accuracy: {}".format(epoch,round(acc,3)))
tags=["loss","accuracy","learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(),"./weights/model-{}.pth".format(epoch))# 删除临时缓存文件if rank==0:if os.path.exists(checkpoint_path)isTrue:
os.remove(checkpoint_path)
cleanup()if __name__=='__main__':
parser= argparse.ArgumentParser()
parser.add_argument('--num_classes',type=int, default=5)
parser.add_argument('--epochs',type=int, default=30)
parser.add_argument('--batch-size',type=int, default=16)
parser.add_argument('--lr',type=float, default=0.001)
parser.add_argument('--lrf',type=float, default=0.1)# 是否启用SyncBatchNorm
parser.add_argument('--syncBN',type=bool, default=True)# 数据集所在根目录# http://download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path',type=str, default="/home/wz/data_set/flower_data/flower_photos")# resnet34 官方权重下载地址# https://download.pytorch.org/models/resnet34-333f7ec4.pth
parser.add_argument('--weights',type=str, default='resNet34.pth',help='initial weights path')
parser.add_argument('--freeze-layers',type=bool, default=False)# 不要改该参数,系统会自动分配
parser.add_argument('--device', default='cuda',help='device id (i.e. 0 or 0,1 or cpu)')# 开启的进程数(注意不是线程),不用设置该参数,会根据nproc_per_node自动设置
parser.add_argument('--world-size', default=4,type=int,help='number of distributed processes')
parser.add_argument('--dist-url', default='env://',help='url used to set up distributed training')
opt= parser.parse_args()
main(opt)使用该脚本是需要在终端通过torch.distributed.launch方法启动的。具体启动指令如下:
python -m torch.distributed.launch --nproc_per_node=8 --use_env train_multi_gpu_using_launch.py在单机多卡情况下,nproc_per_node参数可理解为使用几块GPU设备,使用几块GPU,torch.distributed.launch就会启动多少个进程。如果需要指定使用哪几块GPU可使用以下指令,例如使用第1块和第4块GPU进行训练。
CUDA_VISIBLE_DEVICES=0,3 python -m torch.distributed.launch --nproc_per_node=2 --use_env train_multi_gpu_using_launch.py