文章目录
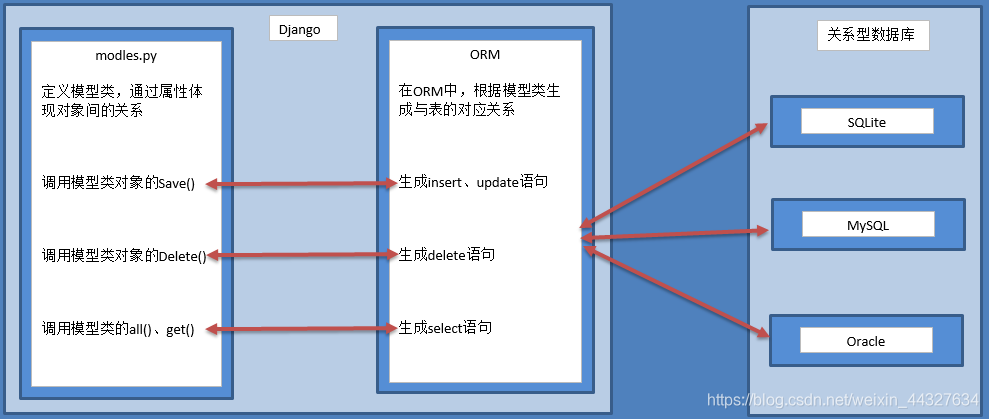
一、ORM框架
O是object,也就类对象的意思,R是relation,翻译成中文是关系,也就是关系数据库中数据表的意思,M是mapping,是映射的意思。在ORM框架中,它帮我们把类和数据表进行了一个映射,可以让我们通过类和类对象就能操作它所对应的表格中的数据。ORM框架还有一个功能,它可以根据我们设计的类自动帮我们生成数据库中的表格,省去了我们自己建表的过程。
django中内嵌了ORM框架,不需要直接面向数据库编程,而是定义模型类,通过模型类和对象完成数据表的增删改查操作。
使用django进行数据库开发的步骤如下:
1.配置数据库连接信息
2.在models.py中定义模型类
3.迁移
4.通过类和对象完成数据增删改查操作
ORM作用: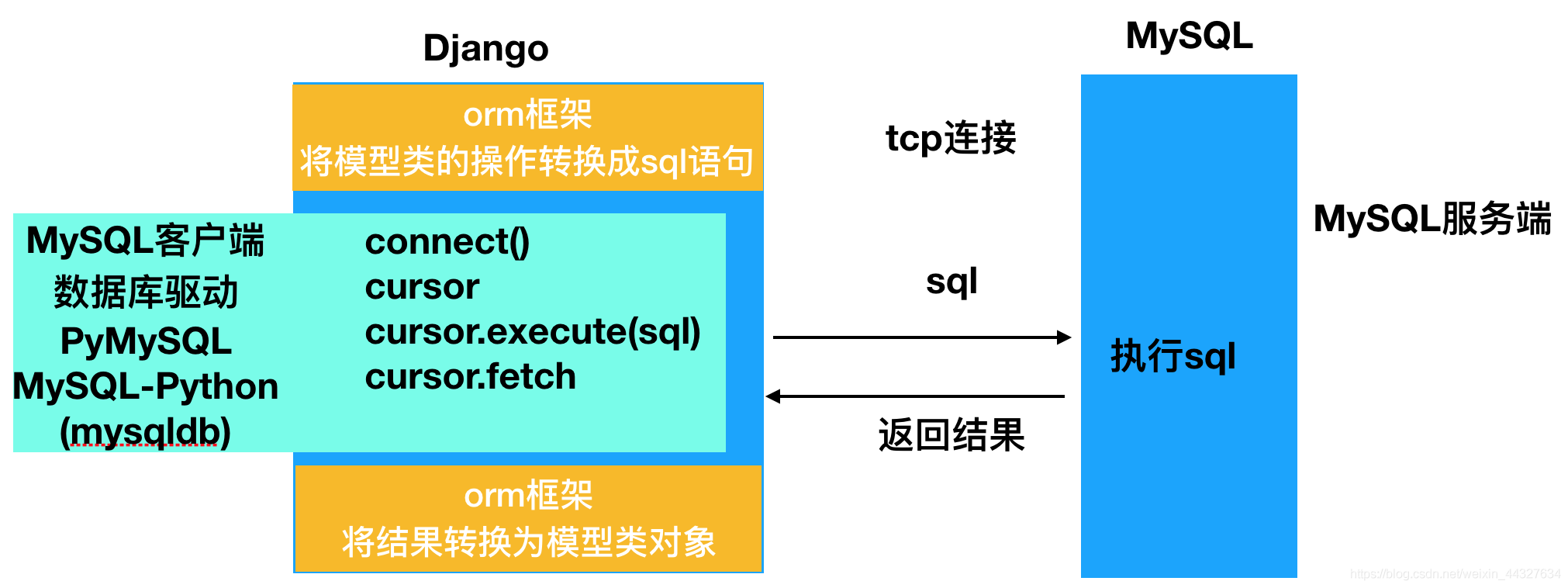
二、 数据库配置
在settings.py中保存了数据库的连接配置信息,Django默认初始配置使用sqlite数据库。
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}我们这里用mysql数据库配置,上面的配置后面还需要修改:
1.使用MySQL数据库首先需要安装驱动程序
pip install PyMySQL2.在Django的工程同名子目录的__init__.py文件中添加如下语句
from pymysql import install_as_MySQLdb
install_as_MySQLdb()作用是让Django的ORM能以mysqldb的方式来调用PyMySQL。
3.在settings.py中修改DATABASES配置信息
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'HOST': '127.0.0.1', # 数据库主机
'PORT': 3306, # 数据库端口
'USER': 'root', # 数据库用户名
'PASSWORD': 'mysql', # 数据库用户密码
'NAME': 'django_demo' # 数据库名字
}
}4.在MySQL中创建数据库
create database django_demo default charset=utf8;到这里就算配置好数据库了,可以试着运行测试一下,因django版本的不同,如果报decode错误,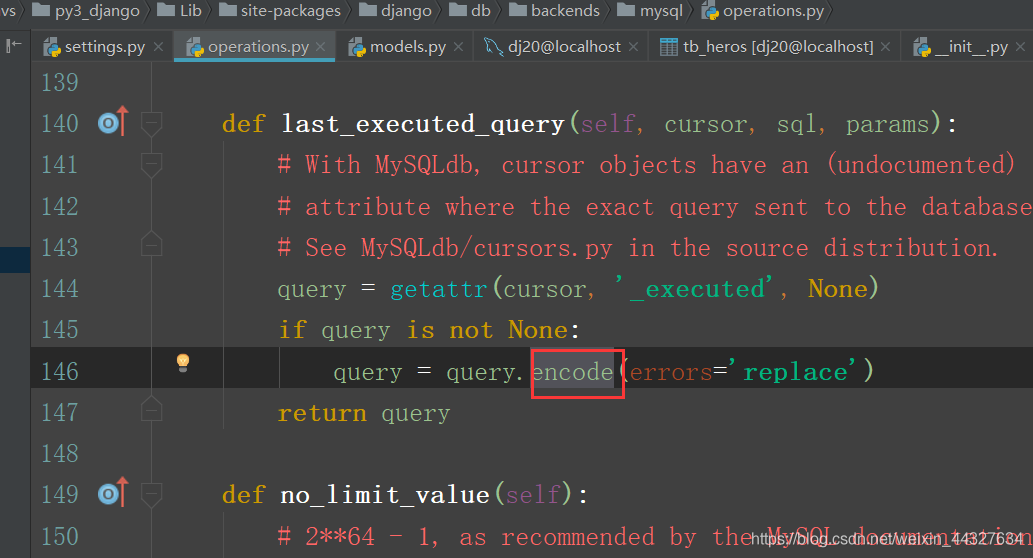
进入那一行底层代码把decode改成encode就可以了。
三、定义模型类
模型类被定义在"应用/models.py"文件中。
模型类必须继承自Model类,位于包django.db.models中。
接下来首先以"图书-英雄"管理为例进行演示。
1. 定义
创建应用books,在models.py 文件中定义模型类。
from django.db import models
# Create your models here.
class BookInfo(models.Model):
btitle = models.CharField(max_length=20, verbose_name='名称')
bpub_date = models.DateField(verbose_name='发布日期')
bread = models.IntegerField(default=0, verbose_name='阅读量')
bcomment = models.IntegerField(default=0, verbose_name='评论量')
is_delete = models.BooleanField(default=False, verbose_name='逻辑删除')
class Meta:
db_table = 'tb_books' # 指明数据库表名
verbose_name = '图书' # 在admin站点中显示的名称
verbose_name_plural = verbose_name # 显示的复数名称
def __str__(self):
"""定义每个数据对象的显示信息"""
return self.btitle
#定义英雄模型类HeroInfo
class HeroInfo(models.Model):
GENDER_CHOICES = (
(0, 'male'),
(1, 'female')
)
hname = models.CharField(max_length=20, verbose_name='名称')
hgender = models.SmallIntegerField(choices=GENDER_CHOICES, default=0, verbose_name='性别')
hcomment = models.CharField(max_length=200, null=True, verbose_name='描述信息')
hbook = models.ForeignKey(BookInfo, on_delete=models.CASCADE, verbose_name='图书') # 外键
is_delete = models.BooleanField(default=False, verbose_name='逻辑删除')
class Meta:
db_table = 'tb_heros'
verbose_name = '英雄'
verbose_name_plural = verbose_name
def __str__(self):
return self.hname1) 数据库表名
模型类如果未指明表名,Django默认以 小写app应用名_小写模型类名 为数据库表名。
可通过db_table 指明数据库表名。
2) 关于主键
django会为表创建自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后django不会再创建自动增长的主键列。
默认创建的主键列属性为id,可以使用pk代替,pk全拼为primary key。
3) 属性命名限制
不能是python的保留关键字。
不允许使用连续的下划线,这是由django的查询方式决定的。
定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:
属性=models.字段类型(选项)
4)字段类型
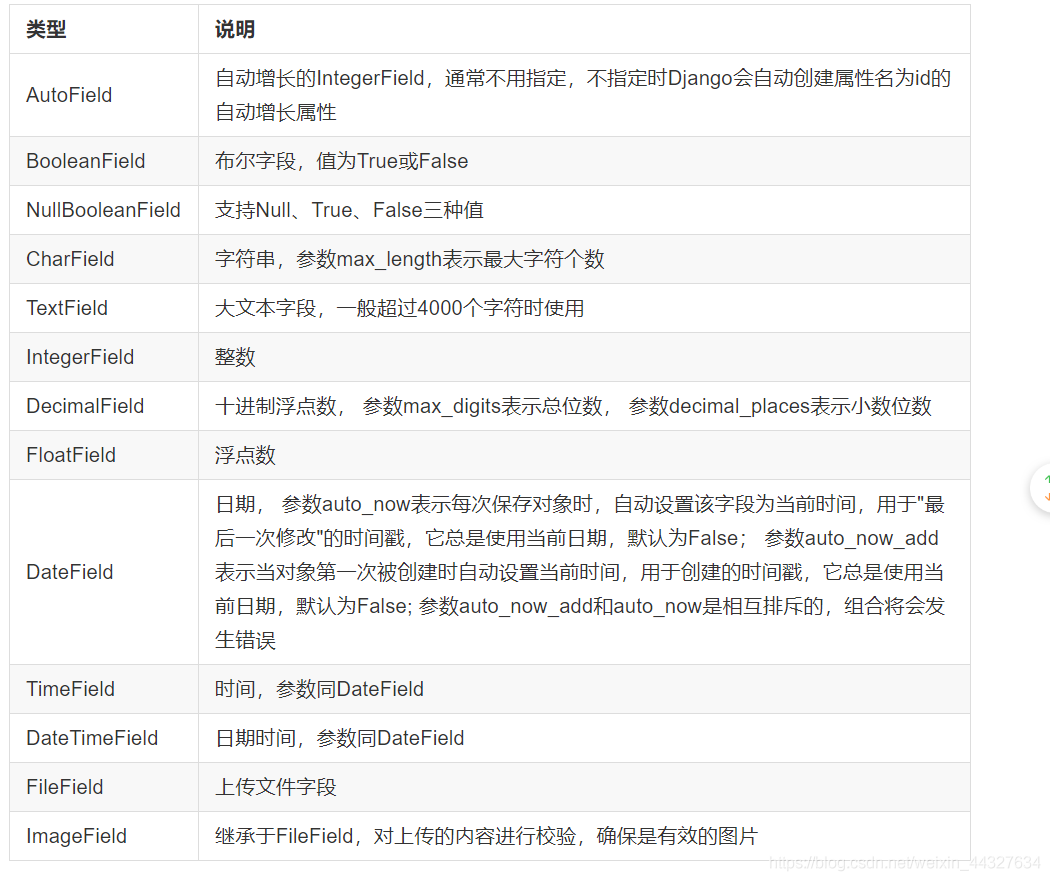
5) 选项

6) 外键
在设置外键时,需要通过on_delete选项指明主表删除数据时,对于外键引用表数据如何处理,在django.db.models中包含了可选常量:
CASCADE 级联,删除主表数据时连通一起删除外键表中数据
PROTECT 保护,通过抛出ProtectedError异常,来阻止删除主表中被外键应用的数据
SET_NULL 设置为NULL,仅在该字段null=True允许为null时可用
SET_DEFAULT 设置为默认值,仅在该字段设置了默认值时可用
SET() 设置为特定值或者调用特定方法,如
from django.conf import settings
from django.contrib.auth import get_user_model
from django.db import models
def get_sentinel_user():
return get_user_model().objects.get_or_create(username='deleted')[0]
class MyModel(models.Model):
user = models.ForeignKey(
settings.AUTH_USER_MODEL,
on_delete=models.SET(get_sentinel_user),
)DO_NOTHING 不做任何操作,如果数据库前置指明级联性,此选项会抛出IntegrityError异常
2. 迁移
将模型类同步到数据库中。
1)生成迁移文件
python manage.py makemigrations2)同步到数据库中
python manage.py migrate3 .添加测试数据
表tb_books:
insert into tb_books(btitle,bpub_date,bread,bcomment,is_delete) values
('射雕英雄传','1980-5-1',12,34,0),
('天龙八部','1986-7-24',36,40,0),
('笑傲江湖','1995-12-24',20,80,0),
('雪山飞狐','1987-11-11',58,24,0);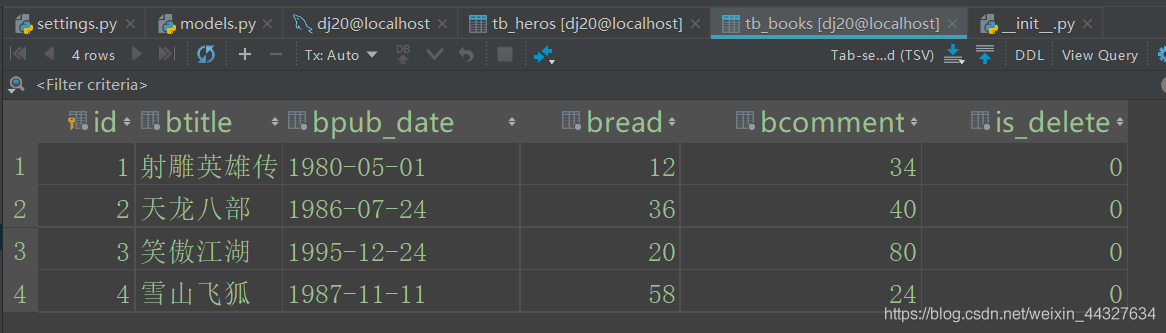
表tb_heros:
insert into tb_heros(hname,hgender,hbook_id,hcomment,is_delete) values
('郭靖',1,1,'降龙十八掌',0),
('黄蓉',0,1,'打狗棍法',0),
('黄药师',1,1,'弹指神通',0),
('欧阳锋',1,1,'蛤蟆功',0),
('梅超风',0,1,'九阴白骨爪',0),
('乔峰',1,2,'降龙十八掌',0),
('段誉',1,2,'六脉神剑',0),
('虚竹',1,2,'天山六阳掌',0),
('王语嫣',0,2,'神仙姐姐',0),
('令狐冲',1,3,'独孤九剑',0),
('任盈盈',0,3,'弹琴',0),
('岳不群',1,3,'华山剑法',0),
('东方不败',0,3,'葵花宝典',0),
('胡斐',1,4,'胡家刀法',0),
('苗若兰',0,4,'黄衣',0),
('程灵素',0,4,'医术',0),
('袁紫衣',0,4,'六合拳',0);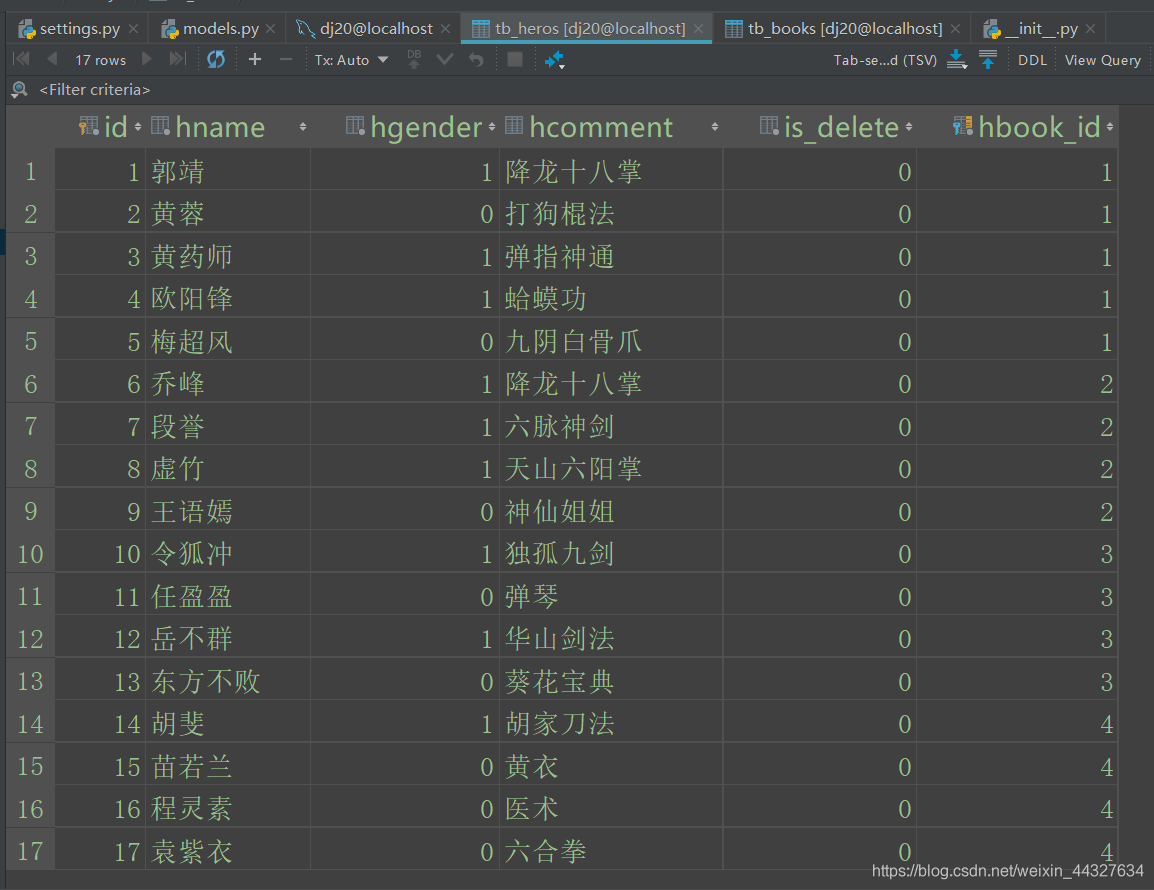
四、使用shell操作数据库—增、删、改、查
Django的manage工具提供了shell命令,帮助我们配置好当前工程的运行环境(如连接好数据库等),以便可以直接在终端中执行测试python语句。
通过如下命令进入shell
python manage.py shell导入两个模型类,以便后续使用
from books.models import BookInfo, HeroInfo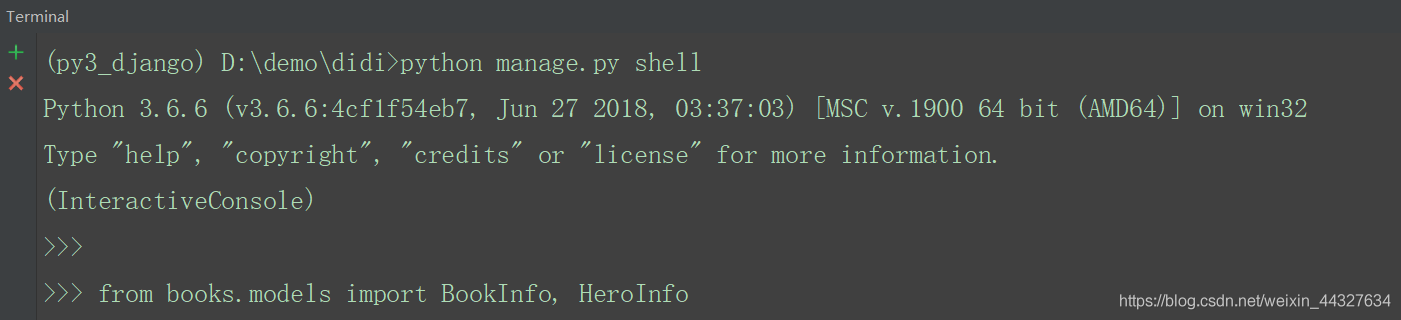
1 增加
增加数据有两种方法:
1)save
通过创建模型类对象,执行对象的save()方法保存到数据库中。
注意:不执行save()方法不会保存到数据库!
添加书籍:
>>> from datetime import date
>>> book = BookInfo(btitle='西游记', bpub_date=date(1988,1,1),bread=10, bcomment=10)
>>> book.save()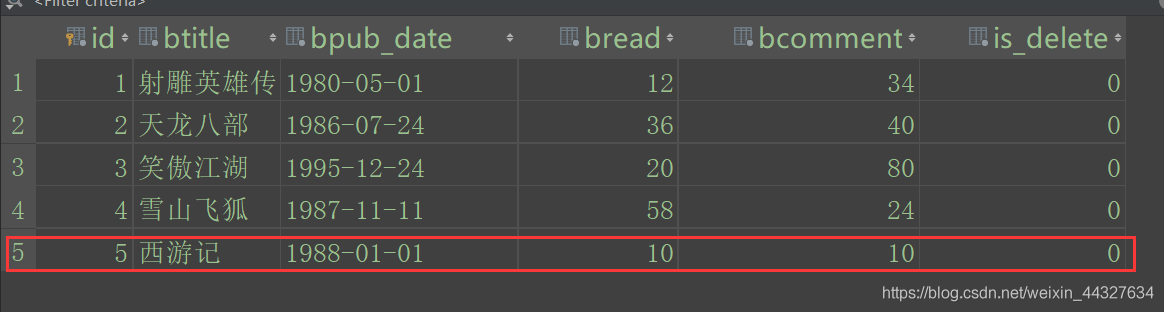
添加英雄:
>>> hero = HeroInfo(hname='孙悟空',hgender=0,hbook=book)
>>> hero.save()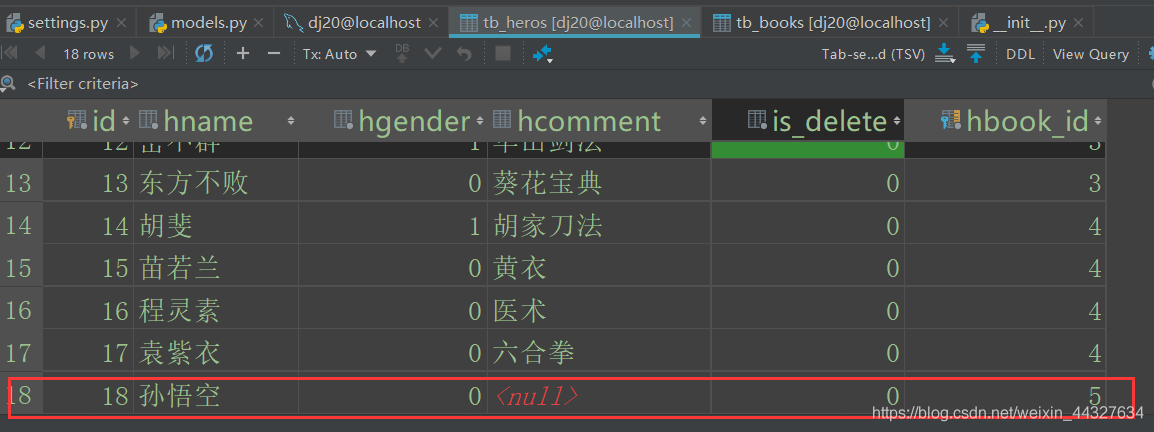
2)create
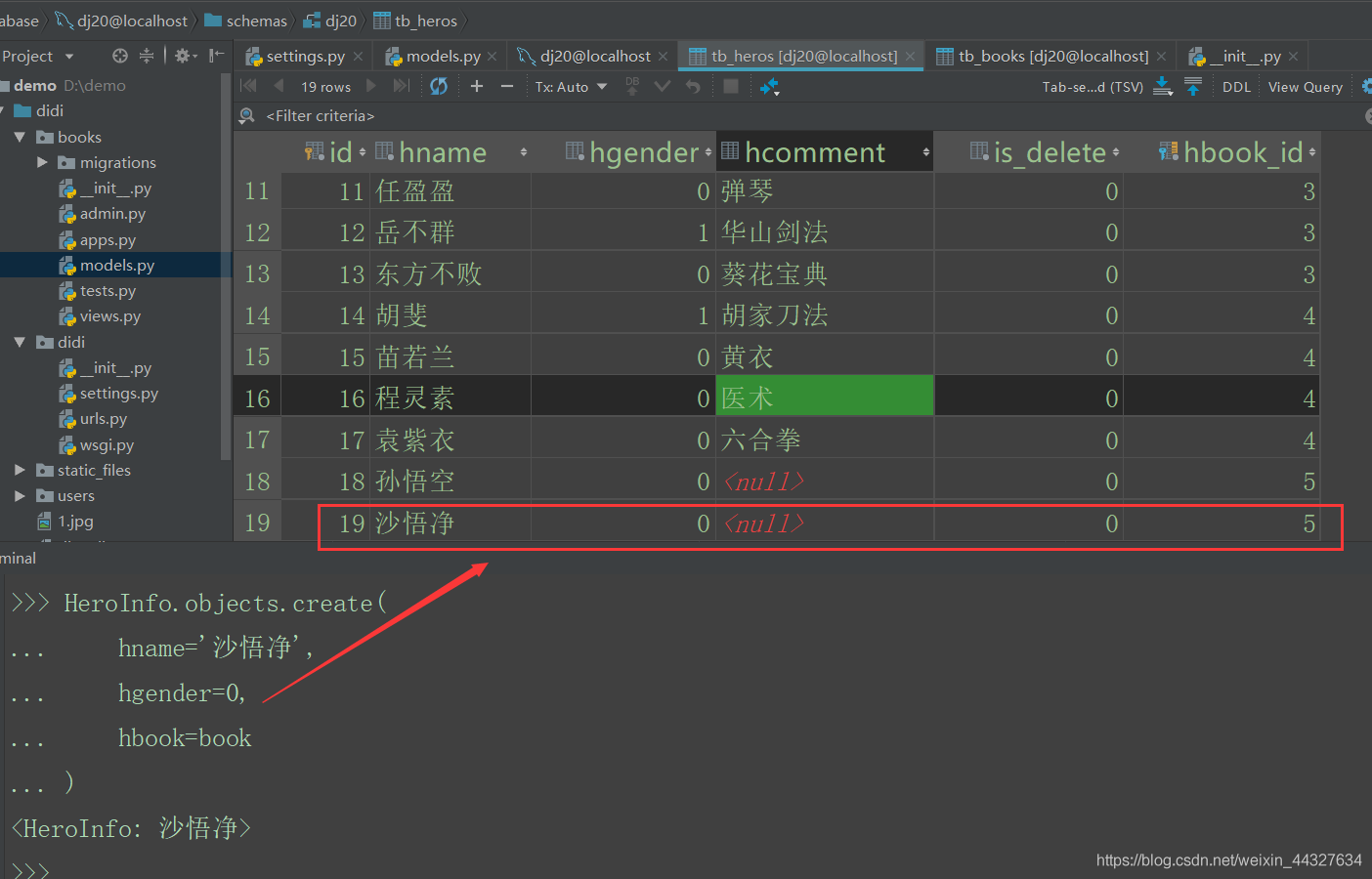
通过模型类.objects.create()保存。我们一般都用这种方式,不用像上面那样再单独调用save方法
>>> HeroInfo.objects.create(
hname='沙悟净',
hgender=0,
hbook=book
)
2 查询
2.1 基本查询
get 查询单一结果,如果不存在会抛出模型类.DoesNotExist异常。
all 查询多个结果。
count 查询结果数量。
>>> BookInfo.objects.all()
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo: 雪山飞狐>, <BookInfo: 西游记>]>
>>> book = BookInfo.objects.get(btitle='西游记')
>>> book.id
5
>>> BookInfo.objects.get(id=3)
<BookInfo: 笑傲江湖>
>>> BookInfo.objects.get(pk=3)
<BookInfo: 笑傲江湖>
# pk等同于id
>>> BookInfo.objects.get(id=100)
#若id不存在会报错:db.models.DoesNotExist: BookInfo matching query does not exist.聚合函数
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg 平均,Count 数量,Max 最大,Min 最小,Sum 求和,被定义在django.db.models中。
例:查询图书的总阅读量。
from django.db.models import Sum
BookInfo.objects.aggregate(Sum('bread'))注意aggregate的返回值是一个字典类型,格式如下:
{'属性名__聚合类小写':值}
如:{'bread__sum':3}使用count时一般不使用aggregate()过滤器。
例:查询图书总数。
BookInfo.objects.count()注意count函数的返回值是一个数字。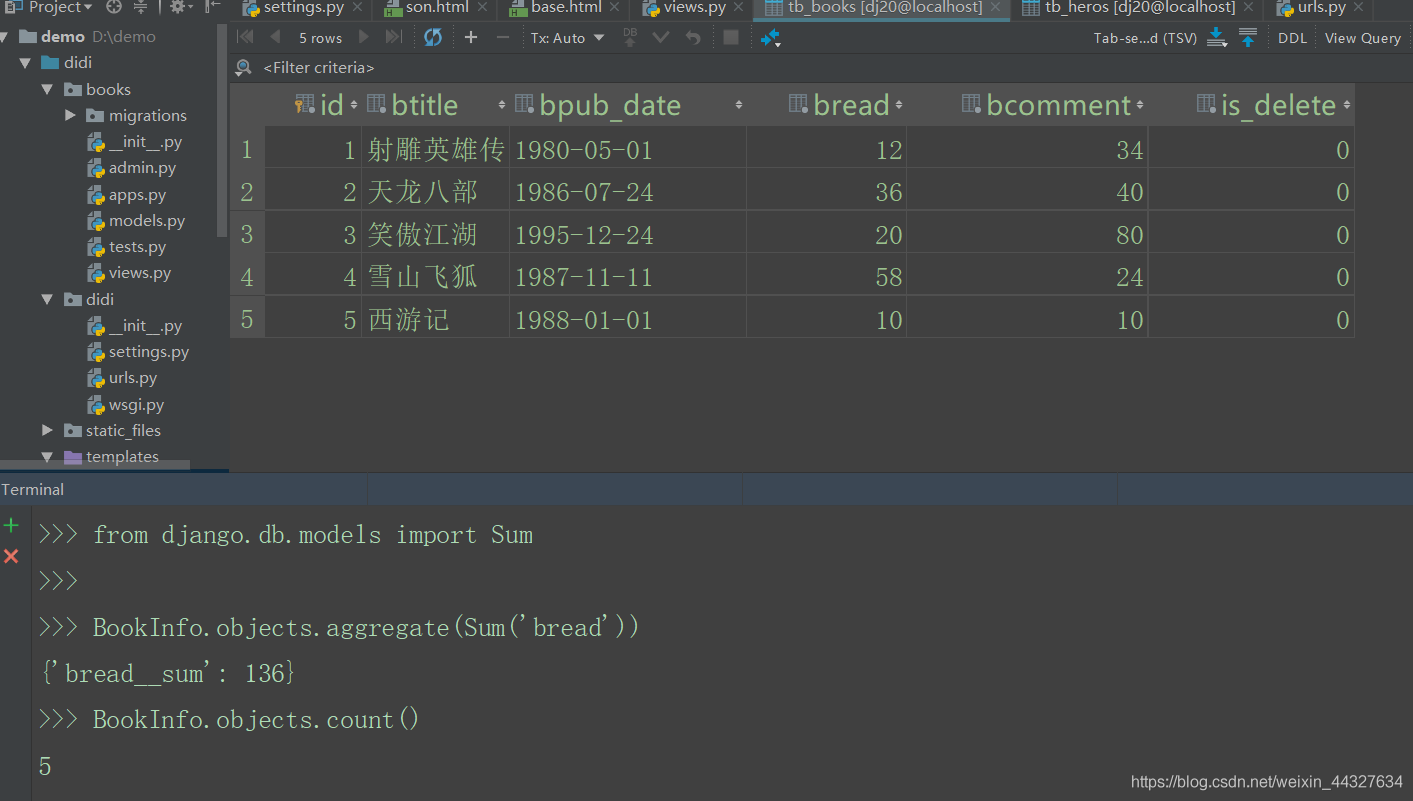
2.2 过滤查询
实现SQL中的where功能,包括
1.filter 过滤出多个结果
2.exclude 排除掉符合条件剩下的结果
3.get 过滤单一结果
对于过滤条件的使用,上述三个方法相同。
过滤条件的表达语法如下:
属性名称__比较运算符=值
# 属性名称和比较运算符间使用两个下划线,所以属性名不能包括多个下划线1)相等
exact:表示判等。
例:查询编号为1的图书。
BookInfo.objects.filter(id__exact=1)
可简写为:
BookInfo.objects.filter(id=1)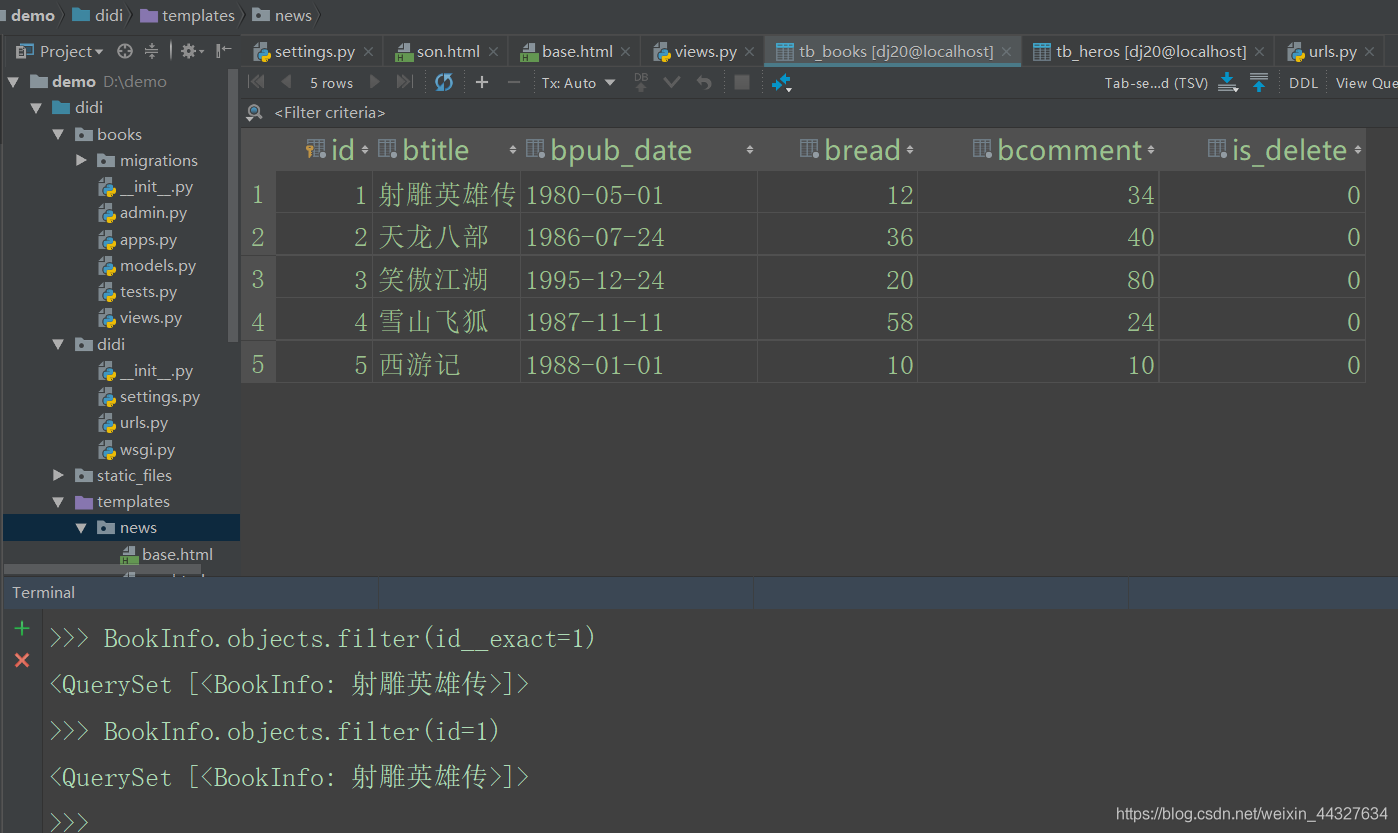
2)模糊查询
contains:是否包含。
说明:如果要包含%无需转义,直接写即可。
例:查询书名包含’传’的图书。
BookInfo.objects.filter(btitle__contains='传')
结果:
<QuerySet [<BookInfo: 射雕英雄传>]>startswith、endswith:以指定值开头或结尾。
例:查询书名以’部’结尾的图书
BookInfo.objects.filter(btitle__endswith='部')以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith。
3) 空查询
isnull:是否为null。
例:查询书名不为空的图书。
BookInfo.objects.filter(btitle__isnull=False)4) 范围查询
in:是否包含在范围内。
例:查询编号为1或3或5的图书
BookInfo.objects.filter(id__in=[1, 3, 5])
结果:
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 笑傲江湖>, <BookInfo: 西游记>]>5)比较查询
gt 大于 (greater then)
gte 大于等于 (greater then equal)
lt 小于 (less then)
lte 小于等于 (less then equal)
例:查询编号大于3的图书
BookInfo.objects.filter(id__gt=3)不等于的运算符,使用exclude()过滤器。
例:查询编号不等于3的图书
BookInfo.objects.exclude(id=3)
结果:
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>, <BookInfo: 西游记>]>6)日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
例:查询1980年发表的图书。
BookInfo.objects.filter(bpub_date__year=1980)例:查询1990年1月1日后发表的图书。
BookInfo.objects.filter(bpub_date__gt=date(1990, 1, 1))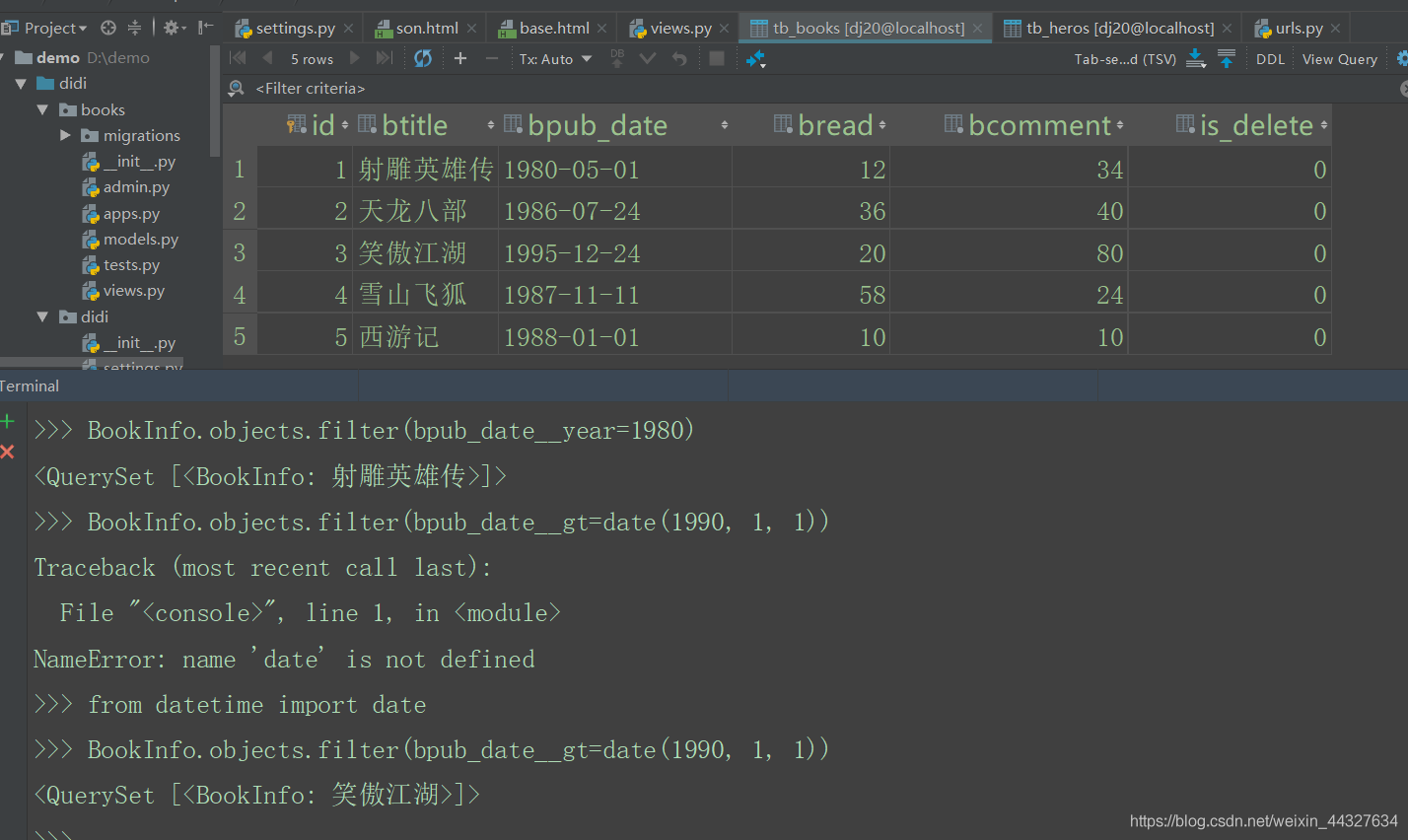
7) F对象
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢?答:使用F对象,被定义在django.db.models中。
语法如下:
F(属性名)例:查询阅读量大于等于评论量的图书。
from django.db.models import F
BookInfo.objects.filter(bread__gte=F('bcomment'))可以在F对象上使用算数运算。
例:查询阅读量大于2倍评论量的图书。
BookInfo.objects.filter(bread__gt=F('bcomment') * 2)8) Q对象
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
例:查询阅读量大于20,并且编号小于3的图书。
BookInfo.objects.filter(bread__gt=20,id__lt=3)
或
BookInfo.objects.filter(bread__gt=20).filter(id__lt=3)如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符,Q对象被定义在django.db.models中。
语法如下:
Q(属性名__运算符=值)例:查询阅读量大于20的图书,改写为Q对象如下。
from django.db.models import Q
BookInfo.objects.filter(Q(bread__gt=20))Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或。
例:查询阅读量大于20,或编号小于3的图书,只能使用Q对象实现
BookInfo.objects.filter(Q(bread__gt=20) | Q(pk__lt=3))Q对象前可以使用~操作符,表示非not。
例:查询编号不等于3的图书。
BookInfo.objects.filter(~Q(pk=3))2.3 排序
使用order_by对结果进行排序
BookInfo.objects.all().order_by('bread') # 升序
BookInfo.objects.all().order_by('-bread') # 降序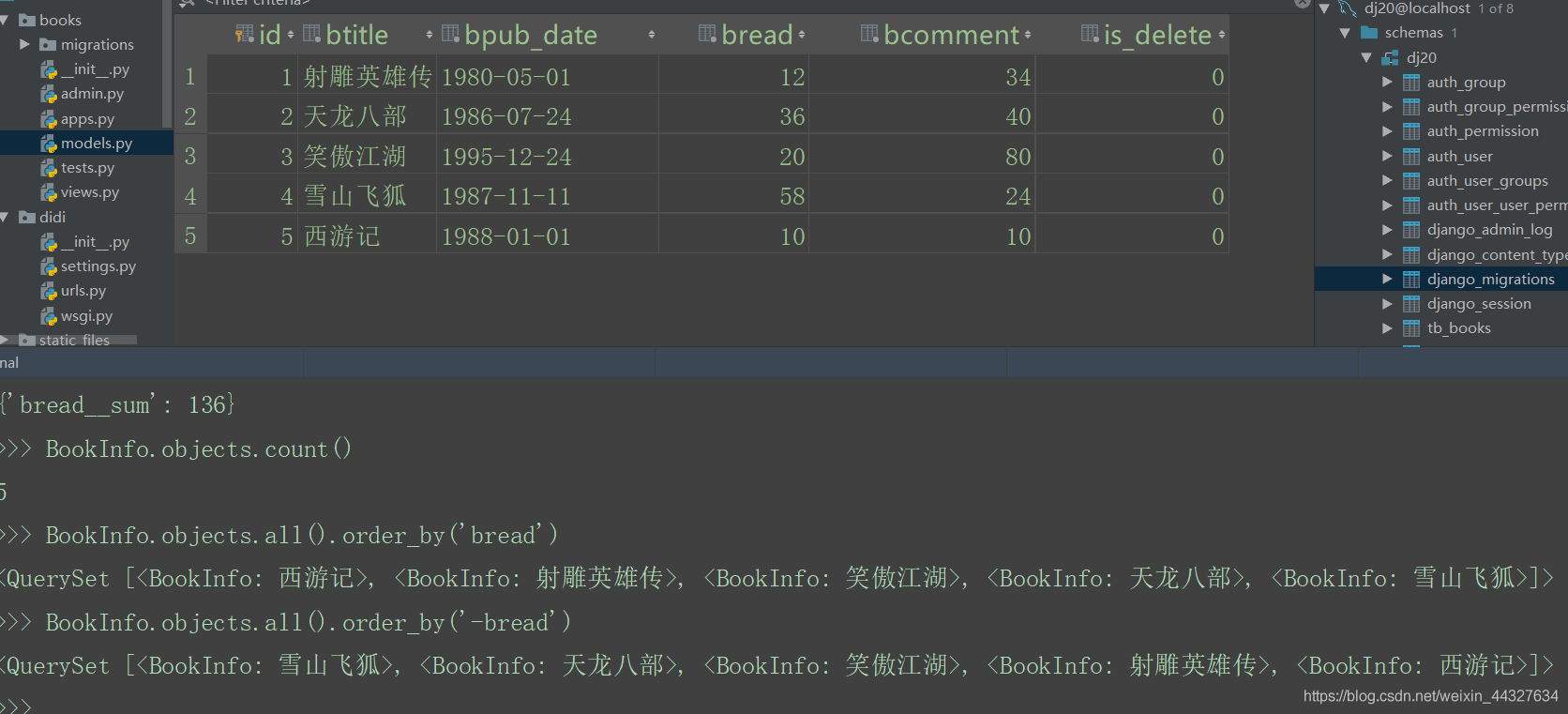
2.4 关联查询
由一到多的访问语法:
一对应的模型类对象.多对应的模型类名小写_set例:
b = BookInfo.objects.get(id=1)
b.heroinfo_set.all()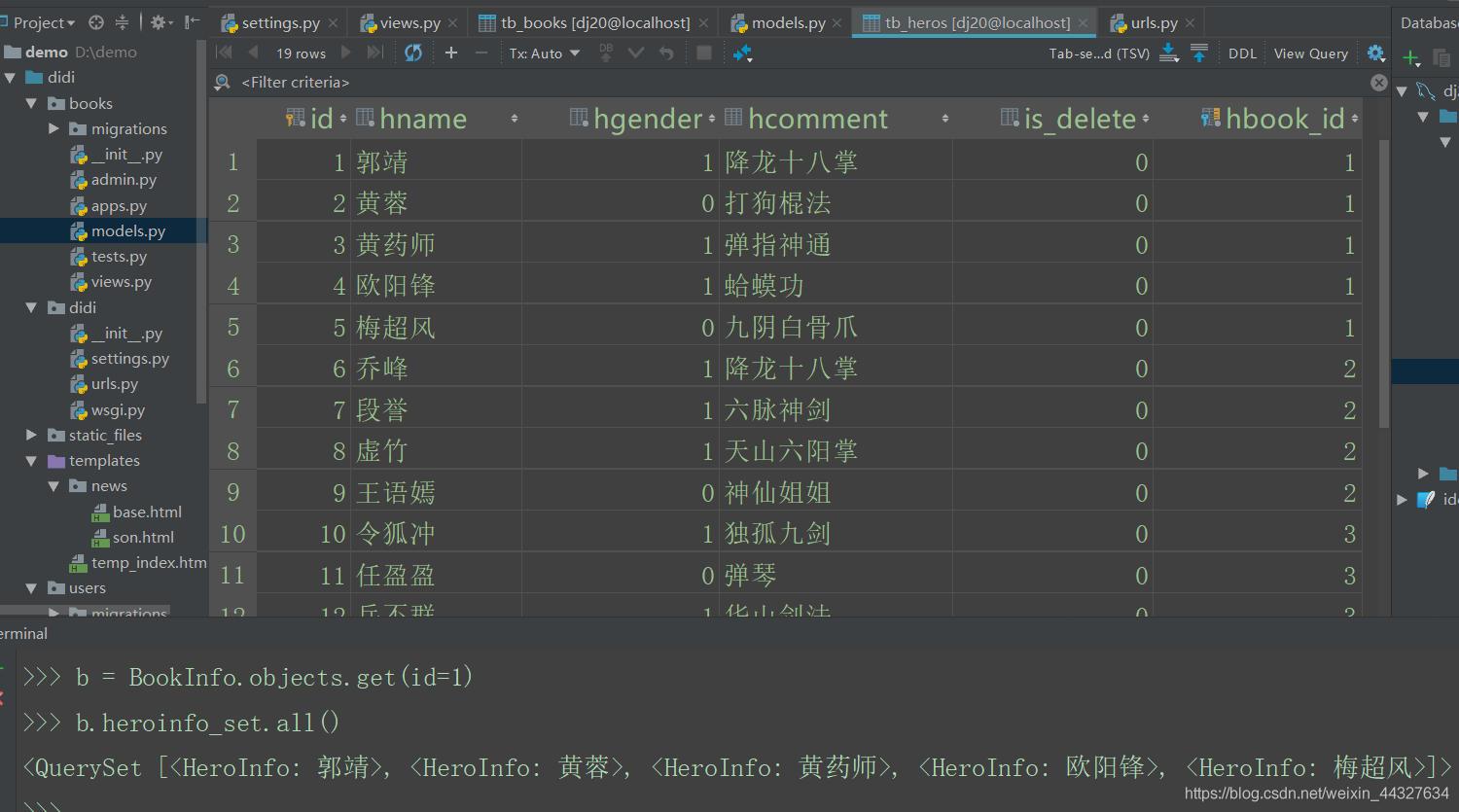
由多到一的访问语法:
多对应的模型类对象.多对应的模型类中的关系类属性名例:
h = HeroInfo.objects.get(id=1)
h.hbook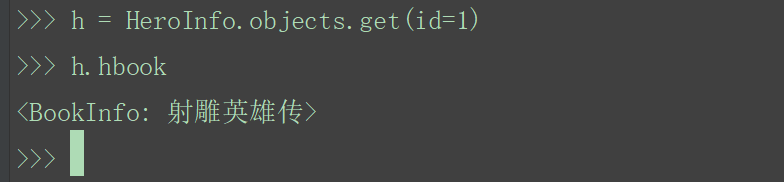
访问一对应的模型类关联对象的id语法:
多对应的模型类对象.关联类属性_id例:
h = HeroInfo.objects.get(id=1)
h.hbook_id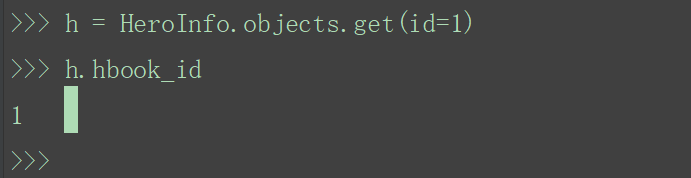
关联过滤查询
由多模型类条件查询一模型类数据:
语法如下:
关联模型类名小写__属性名__条件运算符=值注意:如果没有"__运算符"部分,表示等于。
例:
查询图书,要求图书英雄为"孙悟空"
BookInfo.objects.filter(heroinfo__hname='孙悟空')查询图书,要求图书中英雄的描述包含"八"
BookInfo.objects.filter(heroinfo__hcomment__contains='八')由一模型类条件查询多模型类数据:
语法如下:
一模型类关联属性名__一模型类属性名__条件运算符=值注意:如果没有"__运算符"部分,表示等于。
例:
查询书名为“天龙八部”的所有英雄。
HeroInfo.objects.filter(hbook__btitle='天龙八部')查询图书阅读量大于30的所有英雄
HeroInfo.objects.filter(hbook__bread__gt=30)3 修改
修改更新有两种方法
1)save
修改模型类对象的属性,然后执行save()方法
hero = HeroInfo.objects.get(hname='猪八戒')
hero.hname = '猪悟能'
hero.save()2)update
使用模型类.objects.filter().update(),会返回受影响的行数
HeroInfo.objects.filter(hname='沙悟净').update(hname='沙僧')4 删除
删除有两种方法
1)模型类对象delete
hero = HeroInfo.objects.get(id=13)
hero.delete()2)模型类.objects.filter().delete()
HeroInfo.objects.filter(id=14).delete()五、查询集 QuerySet
1 概念
Django的ORM中存在查询集的概念。查询集,也称查询结果集、QuerySet,表示从数据库中获取的对象集合。
当调用如下过滤器方法时,Django会返回查询集(而不是简单的列表):
all():返回所有数据。
filter():返回满足条件的数据。
exclude():返回满足条件之外的数据。
order_by():对结果进行排序。
对查询集可以再次调用过滤器进行过滤,如
BookInfo.objects.filter(bread__gt=30).order_by('bpub_date')也就意味着查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果。从SQL的角度讲,查询集与select语句等价,过滤器像where、limit、order by子句。
判断某一个查询集中是否有数据:
exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。2 两大特性
1)惰性执行
创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用
例如,当执行如下语句时,并未进行数据库查询,只是创建了一个查询集qs
qs = BookInfo.objects.all()继续执行遍历迭代操作后,才真正的进行了数据库的查询
for book in qs:
print(book.btitle)2)缓存
使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数。
情况一:如下是两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载。
from booktest.models import BookInfo
[book.id for book in BookInfo.objects.all()]
[book.id for book in BookInfo.objects.all()]情况二:经过存储后,可以重用查询集,第二次使用缓存中的数据。
qs=BookInfo.objects.all()
[book.id for book in qs]
[book.id for book in qs]3 限制查询集
可以对查询集进行取下标或切片操作,等同于sql中的limit和offset子句。
注意:不支持负数索引。
对查询集进行切片后返回一个新的查询集,不会立即执行查询。
示例:获取第1、2项,运行查看。
qs = BookInfo.objects.all()[0:2]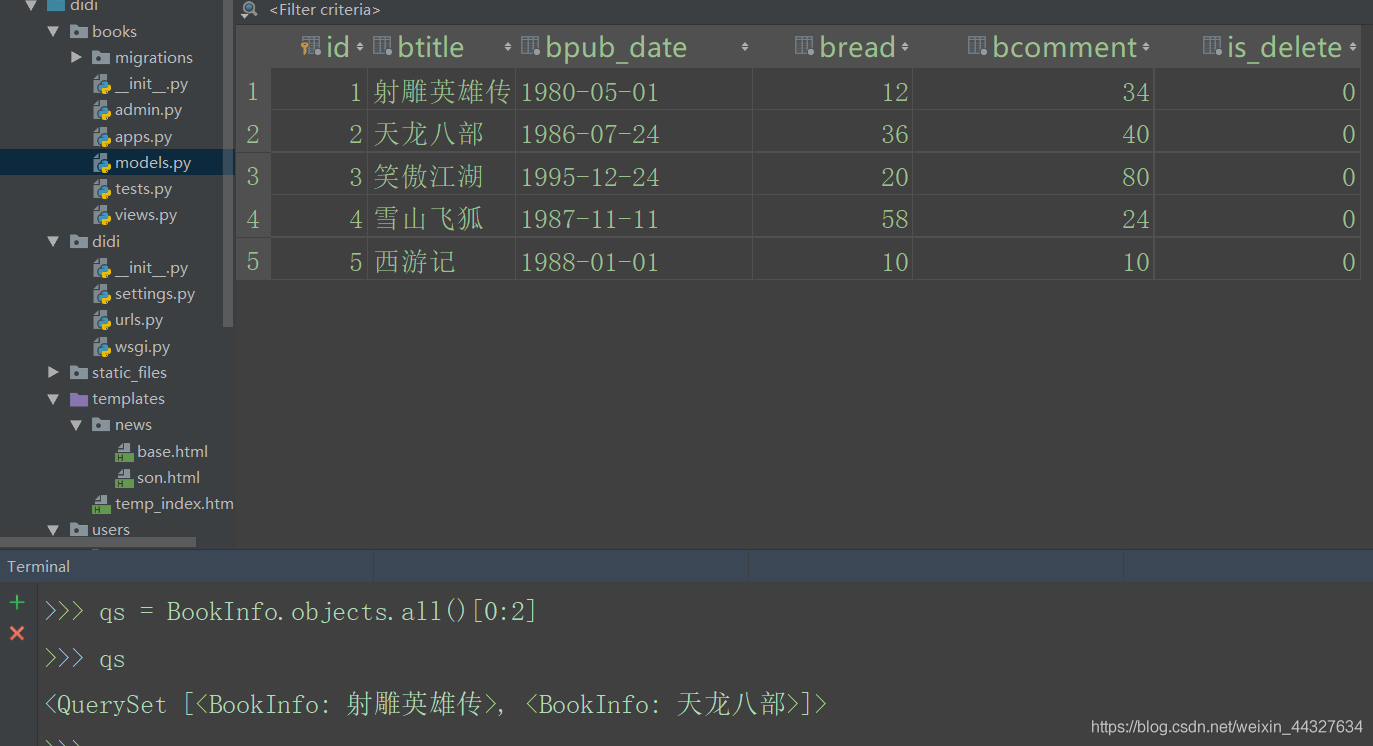
如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()如果没有数据引发DoesNotExist异常。
六、管理器Manager(了解即可,用的较少)
管理器是Django的模型进行数据库操作的接口,Django应用的每个模型类都拥有至少一个管理器。
我们在通过模型类的objects属性提供的方法操作数据库时,即是在使用一个管理器对象objects。当没有为模型类定义管理器时,Django会为每一个模型类生成一个名为objects的管理器,它是models.Manager类的对象。
自定义管理器
我们也可以自定义管理器,并应用到我们的模型类上。
注意:一旦为模型类指明自定义的管理器后,Django不再生成默认管理对象objects。
自定义管理器类主要用于两种情况:
1. 修改原始查询集,重写all()方法。
a)打开books/models.py文件,定义类BookInfoManager
#图书管理器
class BookInfoManager(models.Manager):
def all(self):
#默认查询未删除的图书信息
#调用父类的成员语法为:super().方法名
return super().filter(is_delete=False)b)在模型类BookInfo中定义管理器
class BookInfo(models.Model):
...
bs = BookInfoManager()c)使用方法
from books.models import BookInfo,HeroInfo
BookInfo.bs.all()
# 使用shell测试注意退出重新导入 BookInfo,HeroInfo,否则会报错:AttributeError: type object 'BookInfo' has no attribute 'bs'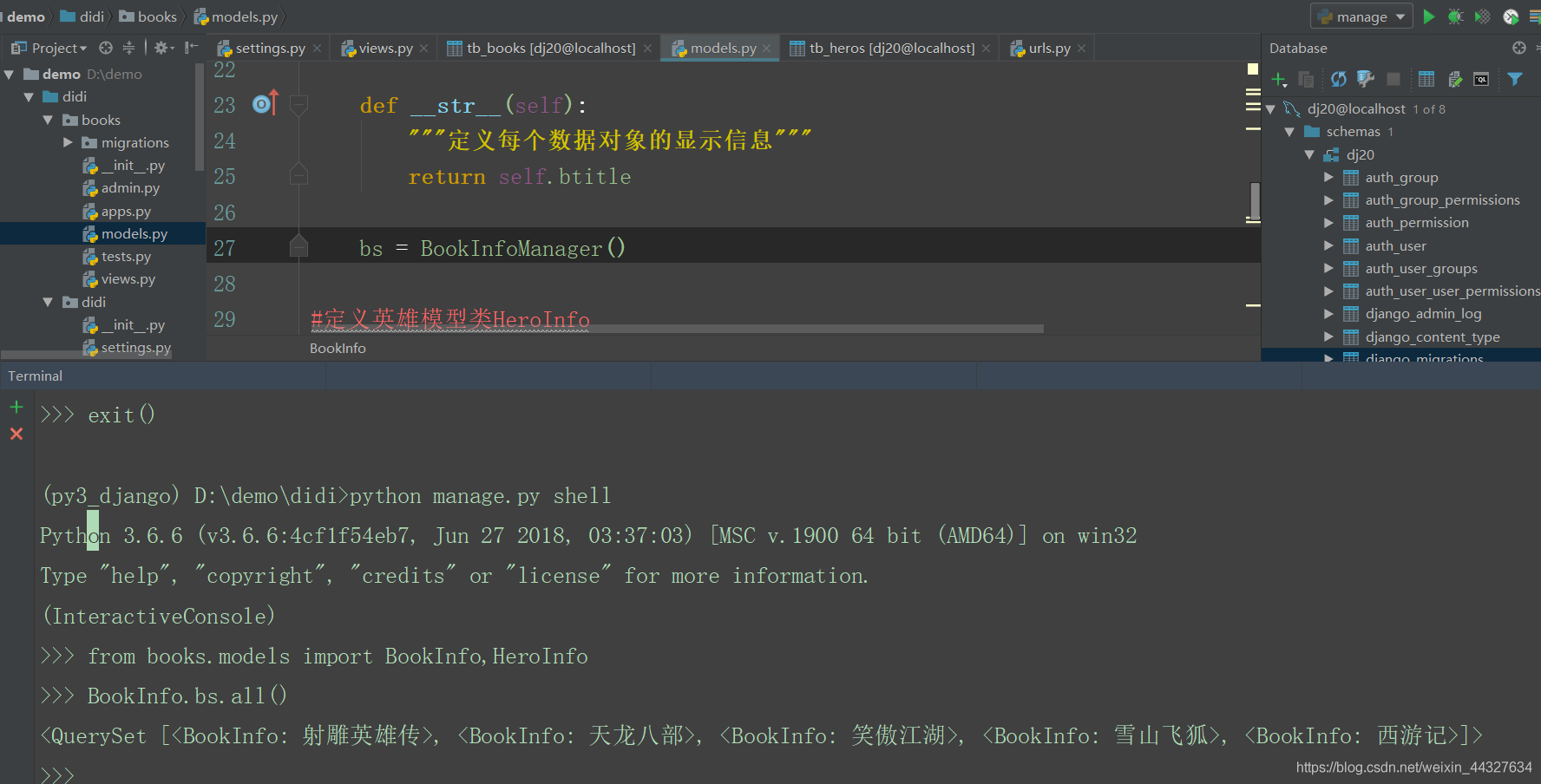
2. 在管理器类中补充定义新的方法
a)打开booktest/models.py文件,定义方法create。
class BookInfoManager(models.Manager):
#创建模型类,接收参数为属性赋值
def create_book(self, title, pub_date):
#创建模型类对象self.model可以获得模型类
book = self.model()
book.btitle = title
book.bpub_date = pub_date
book.bread=0
book.bcommet=0
book.is_delete = False
# 将数据插入进数据表
book.save()
return bookb)为模型类BookInfo定义管理器bs
语法如下
class BookInfo(models.Model):
...
bs = BookInfoManager()c)调用语法如下:
book=BookInfo.bs.create_book("abc",date(1980,1,1))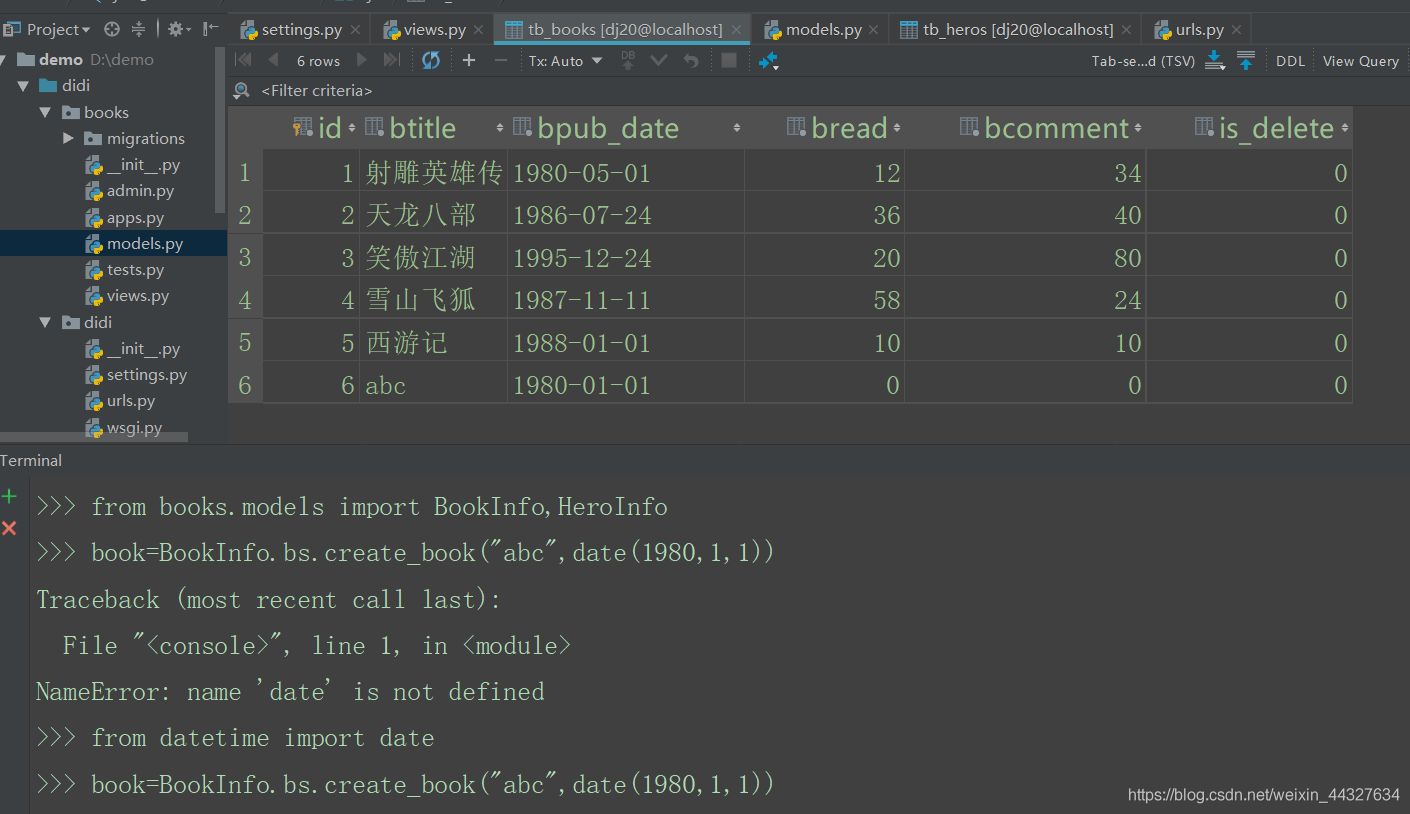
文末鸡汤
心有蓝图,才会人在旅途。不然,充其量就只是随波逐流。漫漫人生路,人总要有一个心心念念的诗和远方,如果已经知晓,那么请一往无前、风雨兼程,如果没有头绪,那么请扪心自问、孜孜以求!
感谢您的阅读,未来一起加油!