有时候我们明明加了索引了,但是索引却不生效。在哪些情况下,索引会不生效呢?
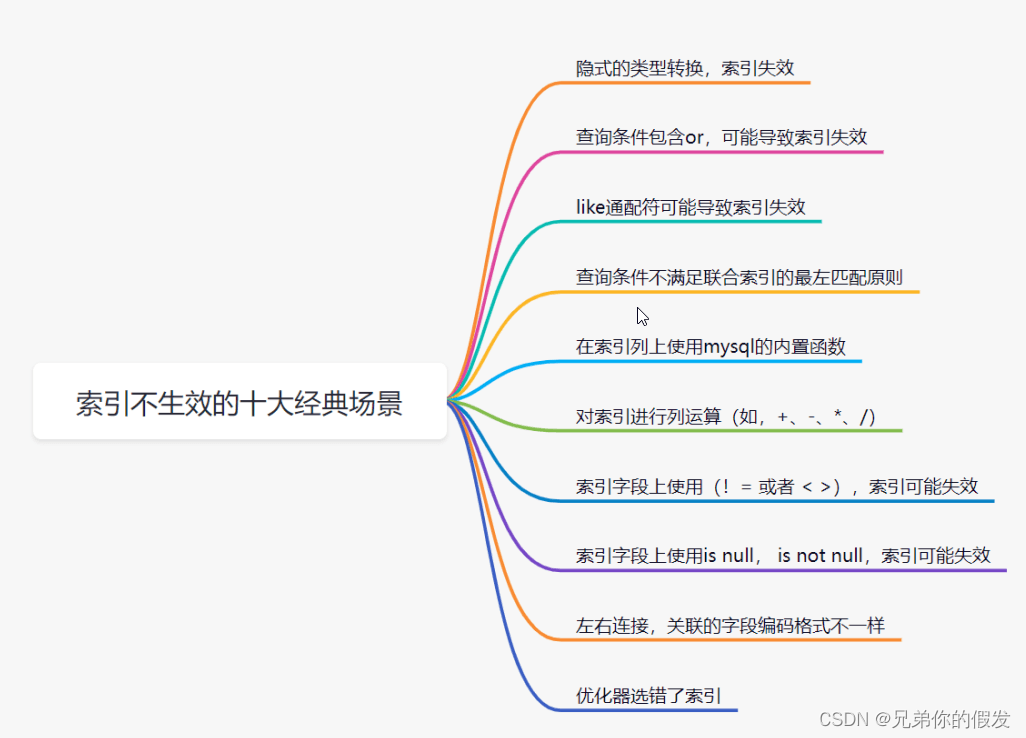
1. 隐式的类型转换,索引失效
例子:
表word_vocabulary字段 book_id 类型为 int(11),book_id设置为索引
//不走索引SELECT*FROM`word_vocabulary`WHERE`book_id`='1'//走索引SELECT*FROM`word_vocabulary`WHERE`book_id`=1查询的时候是字符串跟数字的比较,它们类型不匹配,MySQL 会做隐式的类型转换,把它们转换为浮点数再做比较。隐式的类型转换,索引会失效。
2. 查询条件包含 or,可能导致索引失效
CREATETABLEuser(
idint(11)NOTNULLAUTO_INCREMENT,
userIdvarchar(32)NOTNULL,
agevarchar(16)NOTNULL, namevarchar(255)NOTNULL,PRIMARYKEY(id),KEY idx_userid(userId)USINGBTREE)ENGINE=InnoDBDEFAULTCHARSET=utf8;其中 userId 加了索引,但是 age 没有加索引的。我们使用了 or,以下 SQL 是不走索引的,如下:
SELECT*FROM`user`WHERE`userId`='123'or age='18'对于 or + 没有索引的 age 这种情况,假设它走了 userId 的索引,但是走到 age 查询条件时,它还得全表扫描,也就是需要三步过程:全表扫描 + 索引扫描 + 合并。如果它一开始就走全表扫描,直接一遍扫描就完事。Mysql 优化器出于效率与成本考虑,遇到 or 条件,让索引失效,看起来也合情合理。
注意:如果or 条件的列都加了索引,索引可能会走也可能不走,平时大家使用的时候,还是要注意一下这个 or,学会用 explain 分析。遇到不走索引的时候,考虑拆开两条 SQL。
3. like 通配符可能导致索引失效
并不是用了 like 通配符,索引一定会失效,而是 like 查询是以 % 开头,才会导致索引失效。
like 查询以 % 开头,索引失效:
//不走索引select*fromuserwhere userIdlike'%123';//走索引select*fromuserwhere userIdlike'123%';4. 查询条件不满足联合索引的最左匹配原则
MySQl 建立联合索引时,会遵循最左前缀匹配的原则,即最左优先。如果你建立一个(a,b,c)的联合索引,相当于建立了 (a)、(a,b)、(a,b,c) 三个索引。
假设有以下表结构:
CREATETABLEuser(
idint(11)NOTNULLAUTO_INCREMENT,
user_idvarchar(32)NOTNULL,
agevarchar(16)NOTNULL,
namevarchar(255)NOTNULL,PRIMARYKEY(id),KEY idx_userid_name(user_id,name)USINGBTREE)ENGINE=InnoDBDEFAULTCHARSET=utf8;有一个联合索引 idx_userid_name,我们执行这个 SQL,查询条件是 name,索引是无效:
//不走索引select*fromuserwhere name='小池';//在联合索引中,查询条件满足最左匹配原则时,索引才正常生效select*fromuserwhere user_id='123';5. 在索引列上使用 mysql 的内置函数
表结构:
CREATETABLEuser(
idint(11)NOTNULLAUTO_INCREMENT,
userIdvarchar(32)NOTNULL,
login_timedatetimeNOTNULL,PRIMARYKEY(id),KEY idx_userId(userId)USINGBTREE,KEY idx_login_time(login_Time)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=2DEFAULTCHARSET=utf8;虽然 login_time 加了索引,但是因为使用了 mysql 的内置函数 Date_ADD(),索引直接失效,如图:
一般这种情况怎么优化呢?可以把内置函数的逻辑转移到右边,如下:
6. 对索引进行列运算(如,+、-、*、/), 索引不生效
假设 age 是一个索引,执行以下查询语句索引将无法运行:
select*fromuserwhere age-1=39;不可以对索引列进行运算,可以在代码处理好,再传参进去。
7. 索引字段上使用(!= 或者 < >, not in),索引可能失效
age 加了索引,但是使用了!= 或者 < >,not in 这些时,索引如同虚设。如下查询:
select*fromuserwhere age!=18;select*fromuserwhere age<>18;其实这个也是跟 mySQL优化器有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行的哈,它觉得不划算,不如直接不走索引。平时我们用!= 或者 < >,not in 的时候,要留点心眼。
8. 索引字段上使用 is null, is not null,索引可能失效 (查询结果行数)
很多时候,是因为数据量问题,导致了 MySQL 优化器放弃走索引。同时,平时我们用 explain 分析 SQL 的时候,如果 type=range, 要注意一下哈,因为这个可能因为数据量问题,导致索引无效。
9. 左右连接,关联的字段编码格式不一样
新建两个表,一个 user,一个 user_job
CREATETABLEuser(
idint(11)NOTNULLAUTO_INCREMENT,
namevarchar(255)CHARACTERSET utf8mb4DEFAULTNULL,
ageint(11)NOTNULL,PRIMARYKEY(id), KEYidx_name(name`)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=2DEFAULTCHARSET=utf8;CREATETABLE user_job(
idint(11)NOTNULL,
userIdint(11)NOTNULL,
jobvarchar(255)DEFAULTNULL,
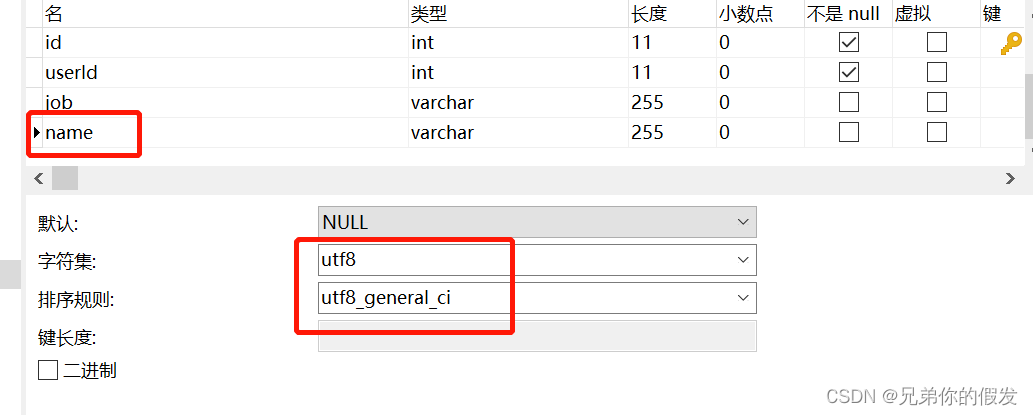
namevarchar(255)DEFAULTNULL,PRIMARYKEY(id),KEY idx_name(name)USINGBTREE)ENGINE=InnoDBDEFAULTCHARSET=utf8;user 表的 name 字段编码是 utf8mb4,而 user_job 表的 name 字段编码为 utf8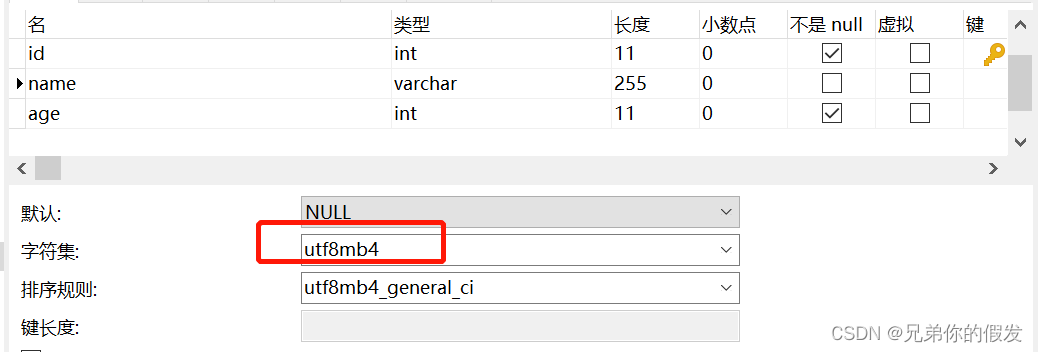
执行左外连接查询,user_job 表还是走全表扫描,如下: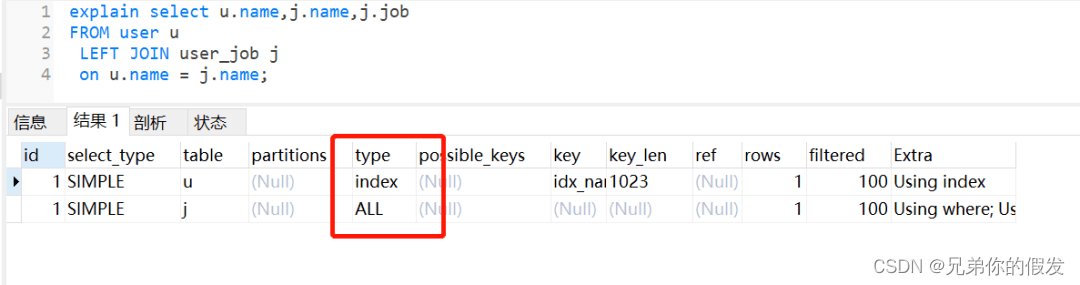
如果把它们的 name 字段改为编码一致,相同的 SQL,还是会走索引。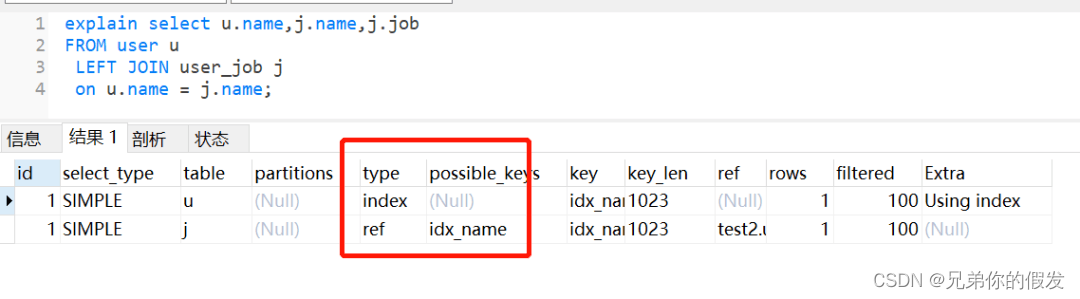
10. 优化器选错了索引
MySQL 中一张表是可以支持多个索引的。你写 SQL 语句的时候,没有主动指定使用哪个索引的话,用哪个索引是由 MySQL 来确定的。
我们日常开发中,不断地删除历史数据和新增数据的场景,有可能会导致 MySQL 选错索引。那么有哪些解决方案呢?
使用 force index 强行选择某个索引
修改你的 SQl,引导它使用我们期望的索引
优化你的业务逻辑
优化你的索引,新建一个更合适的索引,或者删除误用的索引。
原文作者:PHPer技术栈
转自链接:https://learnku.com/articles/68200
版权声明:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请保留以上作者信息和原文链接。