Q-Learning走迷宫
上文中我们了解了Q-Learning算法的思想,基于这种思想我们可以实现很多有趣的功能和小demo,本文让我们通过Q-Learning算法来实现用计算机来走迷宫。
原理简述
我们先从一个比较高端的例子说起,AlphaGo大家都听说过,其实在AlphaGo的训练过程中就使用了Q-Learning的思想,对于机器下错棋和下对棋的时候给予一定的惩罚和奖励,当经过无数次的训练之后,机器自然就会直接向着奖励前进,直接选择对的位置进行下棋,久而久之在各种场景下都能选择对的位置下棋的机器人就能够把人类打败了。
再回到我们今天要讲的例子上来,走迷宫和下棋的原理其实类似,我们要走的路无非就是两种:顺畅的路和有障碍的路,那我们要做的事也就很明了了,当触碰到障碍的时候给予一定的惩罚,走了正确的路时给予一定的奖励,这样经过不断的训练,机器就应该能够知道该如何”走迷宫“了。我们要走的迷宫示意图如下:
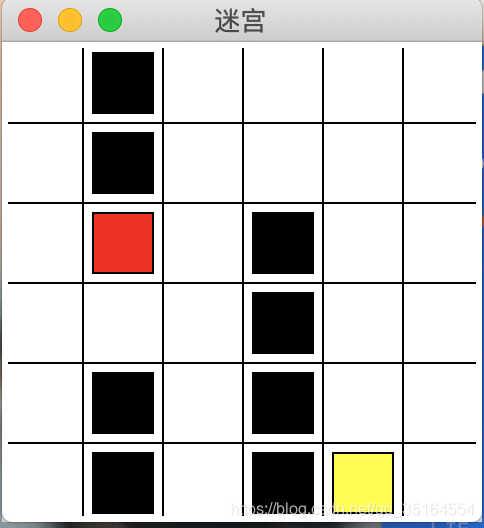
代码实现
构建画布
我们首先要做的就是来构建画布并且画出迷宫,Python中Tkinter就是一个很好的画图工具(相对于其他的库来说,该库运行快,且不容易卡死)
构建画布的时候,我们除了需要构建基本的图形和迷宫,还需要实现行动的方式,对于简单的迷宫来说,我们只需要设定“上下左右”的行动方式就可以了,如果走到了黑块就得到-1的惩罚并结束回合,走到黄块得到1的奖励并结束回合。其余的解释放在代码注释中,画布代码如下:
# coding: utf-8import sysimport timeimport numpyas npif sys.version_info.major==2:import Tkinteras tkelse:import tkinteras tkclassMaze(tk.Tk,object):
UNIT=40# 像素
MAZE_H=6# 网格高度
MAZE_W=6# 网格宽度def__init__(self):super(Maze, self).__init__()
self.action_space=['U','D','L','R']
self.n_actions=len(self.action_space)
self.title('迷宫')
self.geometry('{0}x{1}'.format(self.MAZE_H* self.UNIT,
self.MAZE_W* self.UNIT))
self._build_maze()# 画矩形# x y 格坐标# color 颜色def_draw_rect(self, x, y, color):
center= self.UNIT/2
w= center-5
x_= self.UNIT* x+ center
y_= self.UNIT* y+ centerreturn self.canvas.create_rectangle(x_- w,
y_- w,
x_+ w,
y_+ w,
fill=color)# 初始化迷宫def_build_maze(self):
h= self.MAZE_H* self.UNIT
w= self.MAZE_W* self.UNIT# 初始化画布
self.canvas= tk.Canvas(self, bg='white', height=h, width=w)# 画线for cinrange(0, w, self.UNIT):
self.canvas.create_line(c,0, c, h)for rinrange(0, h, self.UNIT):
self.canvas.create_line(0, r, w, r)# 陷阱
self.hells=[
self._draw_rect(3,2,'black'),
self._draw_rect(3,3,'black'),
self._draw_rect(3,4,'black'),
self._draw_rect(3,5,'black'),
self._draw_rect(4,5,'black'),
self._draw_rect(1,0,'black'),
self._draw_rect(1,1,'black'),
self._draw_rect(1,2,'black'),
self._draw_rect(1,4,'black'),
self._draw_rect(1,5,'black')]
self.hell_coords=[]for hellin self.hells:
self.hell_coords.append(self.canvas.coords(hell))# 奖励
self.oval= self._draw_rect(4,5,'yellow')# 玩家对象
self.rect= self._draw_rect(0,0,'red')
self.canvas.pack()#执行画# 重新初始化(用于撞到黑块后重新开始)defreset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
self.rect= self._draw_rect(0,0,'red')
self.old_s=None#返回 玩家矩形的坐标 [5.0, 5.0, 35.0, 35.0]return self.canvas.coords(self.rect)# 走下一步defstep(self, action):
s= self.canvas.coords(self.rect)
base_action= np.array([0,0])if action==0:# upif s[1]> self.UNIT:
base_action[1]-= self.UNITelif action==1:# downif s[1]<(self.MAZE_H-1)* self.UNIT:
base_action[1]+= self.UNITelif action==2:# rightif s[0]<(self.MAZE_W-1)* self.UNIT:
base_action[0]+= self.UNITelif action==3:# leftif s[0]> self.UNIT:
base_action[0]-= self.UNIT# 根据策略移动红块
self.canvas.move(self.rect, base_action[0], base_action[1])
s_= self.canvas.coords(self.rect)# 判断是否得到奖励或惩罚
done=Falseif s_== self.canvas.coords(self.oval):
reward=1
done=Trueelif s_in self.hell_coords:
reward=-1
done=True#elif base_action.sum() == 0:# reward = -1else:
reward=0
self.old_s= sreturn s_, reward, donedefrender(self):
time.sleep(0.01)
self.update()实现算法
实现算法的过程就是按照我们上一文中所说到的Q-Learning的算法运行方式来进行,代码实现如下:
# coding: utf-8import pandasas pdimport numpyas npclassq_learning_model_maze:def__init__(self,
actions,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.99):
self.actions= actions
self.learning_rate= learning_rate
self.reward_decay= reward_decay
self.e_greedy= e_greedy
self.q_table= pd.DataFrame(columns=actions, dtype=np.float32)# 检查状态是否存在defcheck_state_exist(self, state):if statenotin self.q_table.index:
self.q_table= self.q_table.append(
pd.Series([0]*len(self.actions),
index=self.q_table.columns,
name=state,))# 选择动作defchoose_action(self, s):
self.check_state_exist(s)if np.random.uniform()< self.e_greedy:
state_action= self.q_table.loc[s,:]
state_action= state_action.reindex(
np.random.permutation(
state_action.index))# 防止相同列值时取第一个列,所以打乱列的顺序
action= state_action.idxmax()else:
action= np.random.choice(self.actions)return action# 更新q表defrl(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict= self.q_table.loc[s, a]# q估计if s_!='terminal':
q_target= r+ self.reward_decay* self.q_table.loc[
s_,:].max()# q现实else:
q_target= r
self.q_table.loc[s, a]+= self.learning_rate*(q_target- q_predict)训练
训练的时候我们需要做的就是选择状态并执行,最后把执行的结果更新到状态表中。
# coding: utf-8defupdate():for episodeinrange(100):
s= env.reset()whileTrue:
env.render()# 选择一个动作
action= RL.choose_action(str(s))# 执行这个动作得到反馈(下一个状态s 奖励r 是否结束done)
s_, r, done= env.step(action)# 更新状态表
RL.rl(str(s), action, r,str(s_))
s= s_if done:print(episode)breakif __name__=="__main__":
env= Maze()
RL= q_learning_model_maze(actions=list(range(env.n_actions)))
env.after(10, update)# 设置10ms的延迟
env.mainloop()