Pytorch 加载数据集的几种方法
总结
坑
方案1:
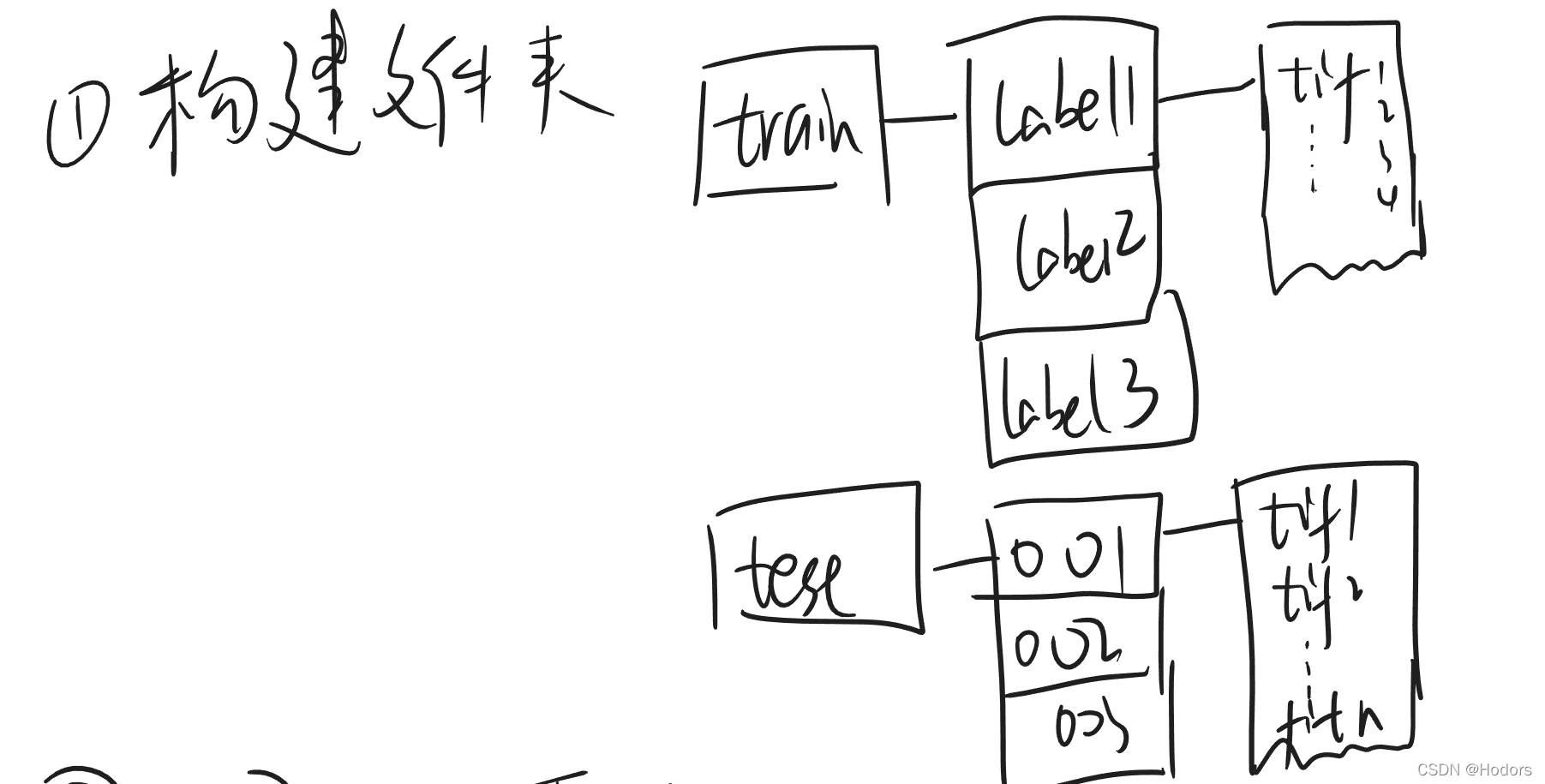

方案2:
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)在for循环中调用
for i, (images, labels) in enumerate(train_loader):
方案3:官网的介绍
Dataset stores the samples and their corresponding labels
Dataset 包含数据样本和相应的标签labels;
DataLoader wraps an iterable around theDataset to enable easy access to the samples.
DataLoader 相当于是对dateset的一个迭代器封装;
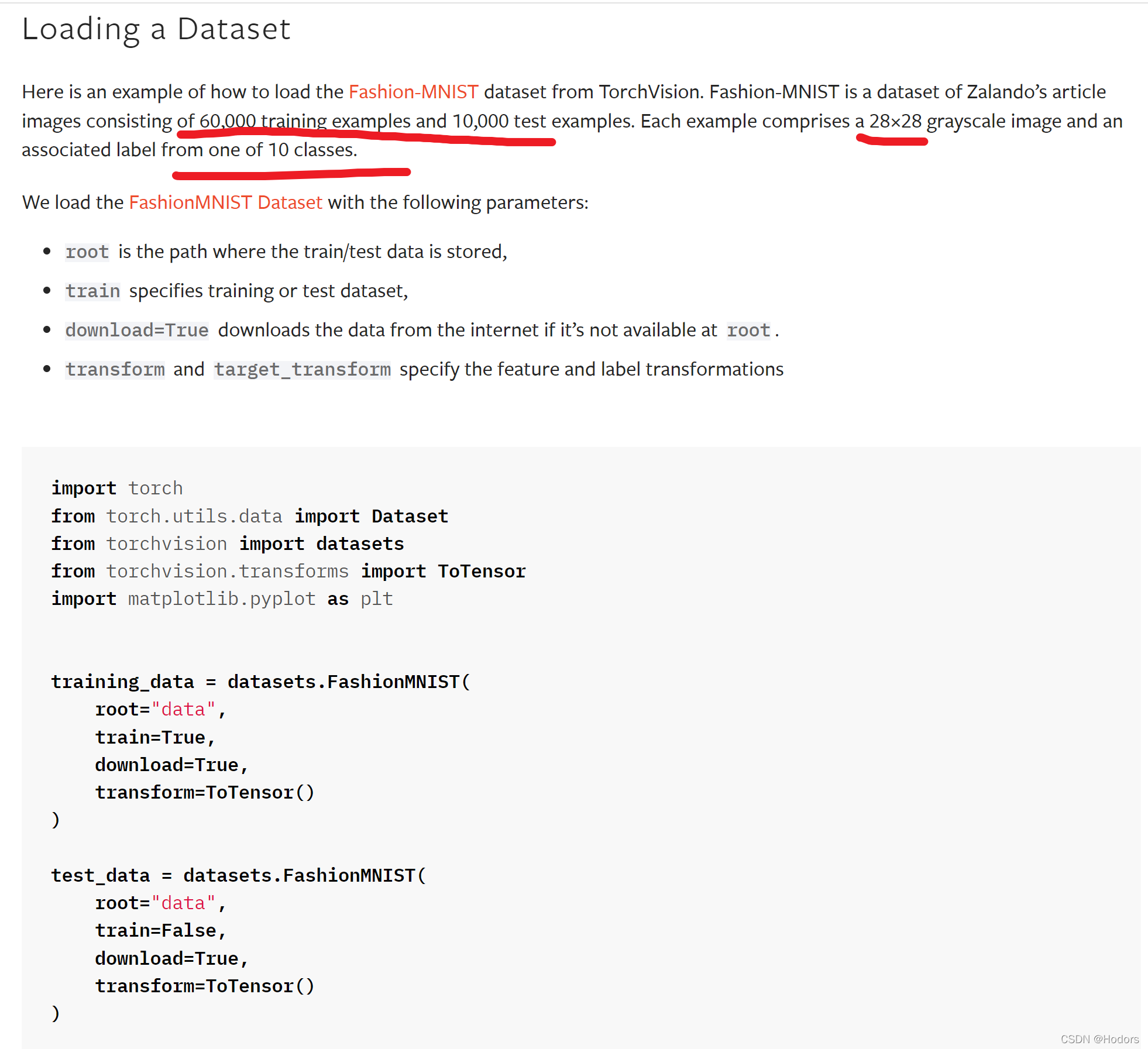

对数据集中的数据,进行可视化;
构建自己的dataset
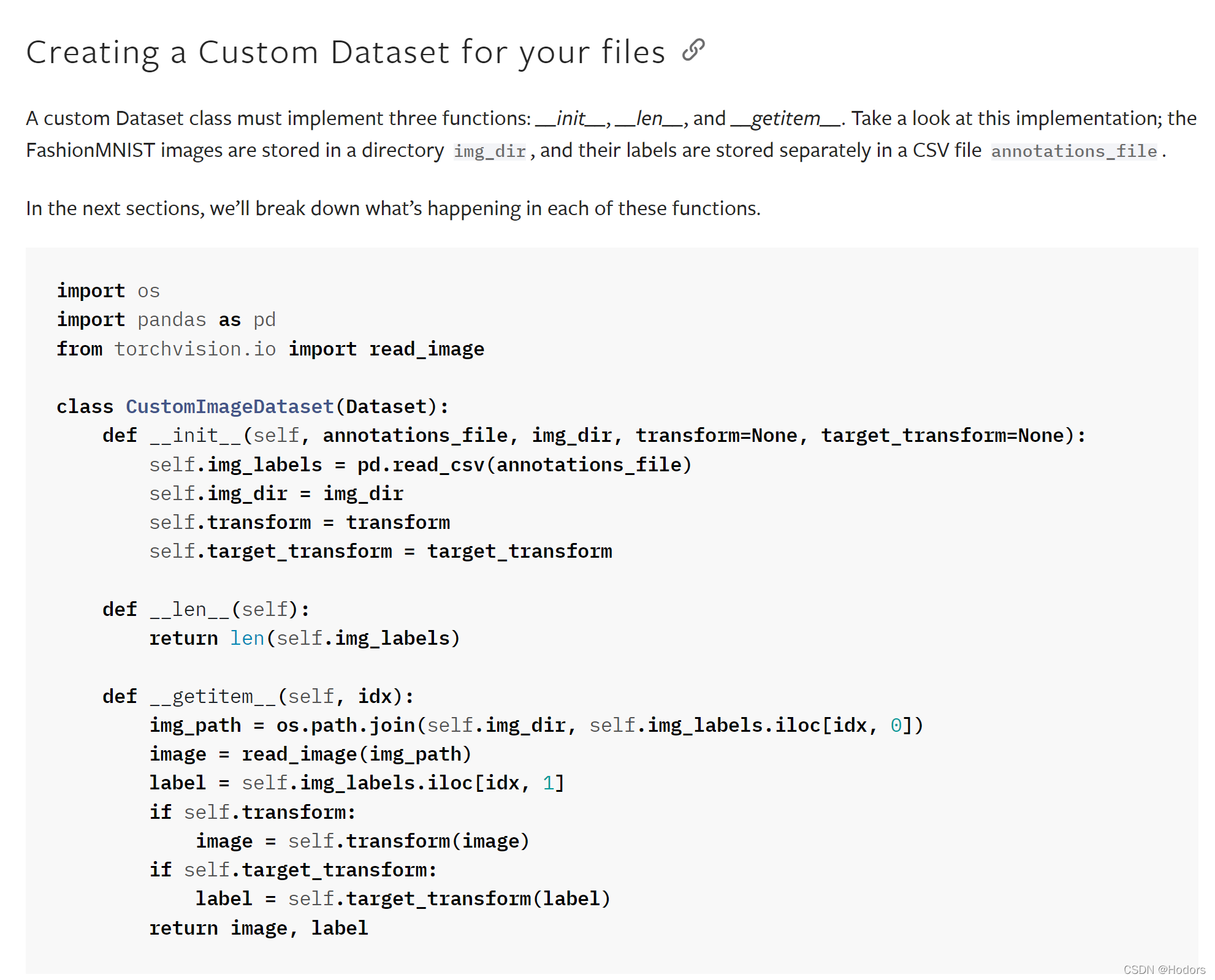
Datasets & DataLoaders — PyTorch Tutorials 1.11.0+cu102 documentation
官方文档YYDS