准备
- 搭建好kafka
- 可正常访问查询节点的8888端口: http://hadoop04:8888
按部就班
新建一个摄取规范,定义你的数据从哪摄取、怎么摄取、摄取成什么样。 选择kafka。
选择kafka。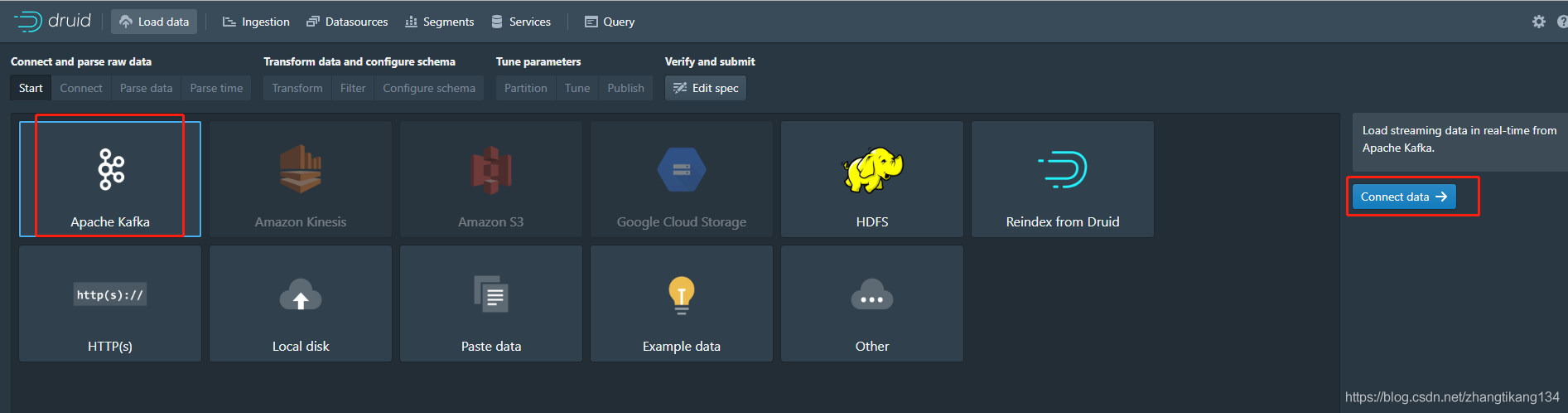
填写kafka消费者基本属性。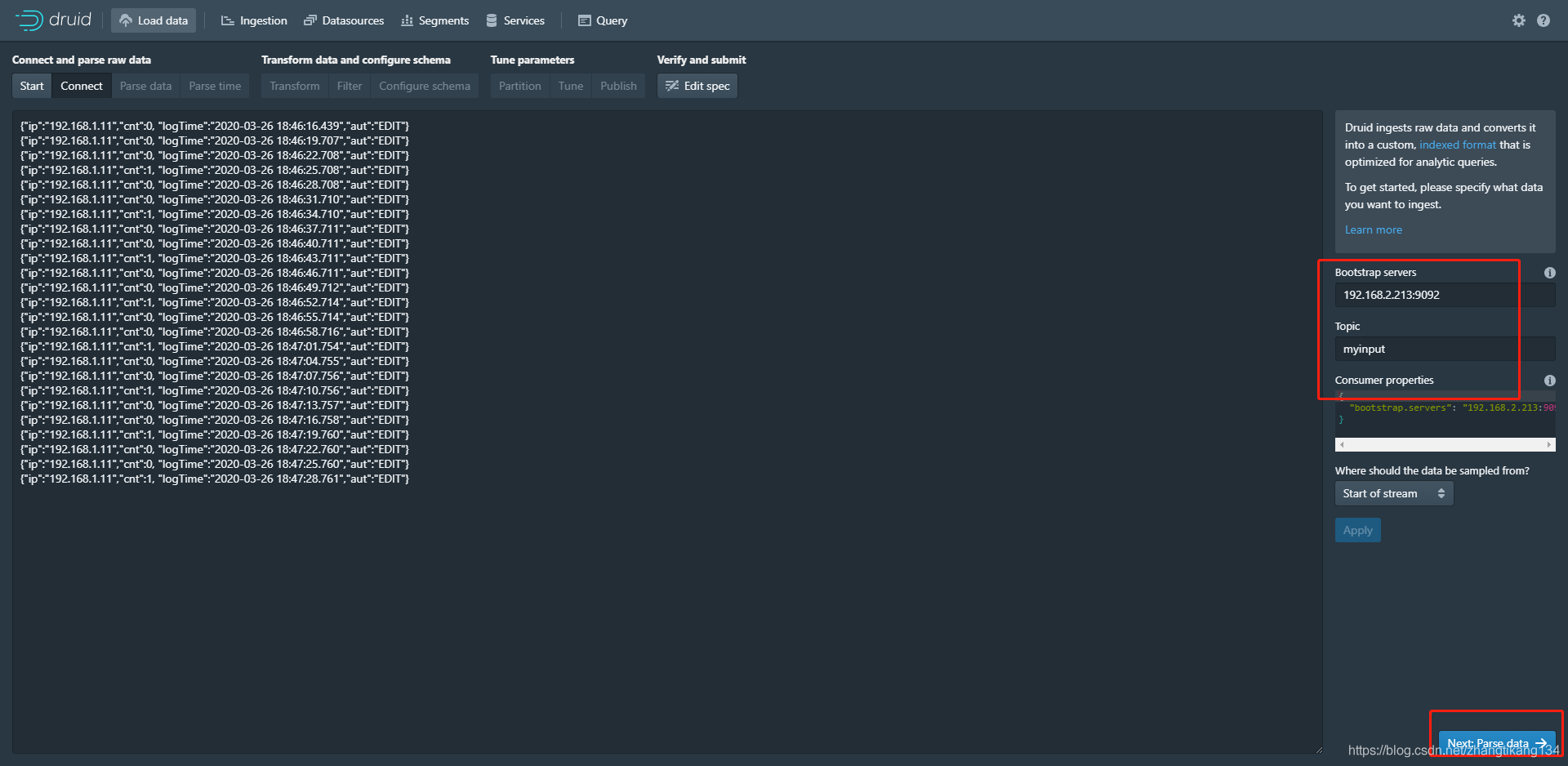 检查你的数据列是否完整。
检查你的数据列是否完整。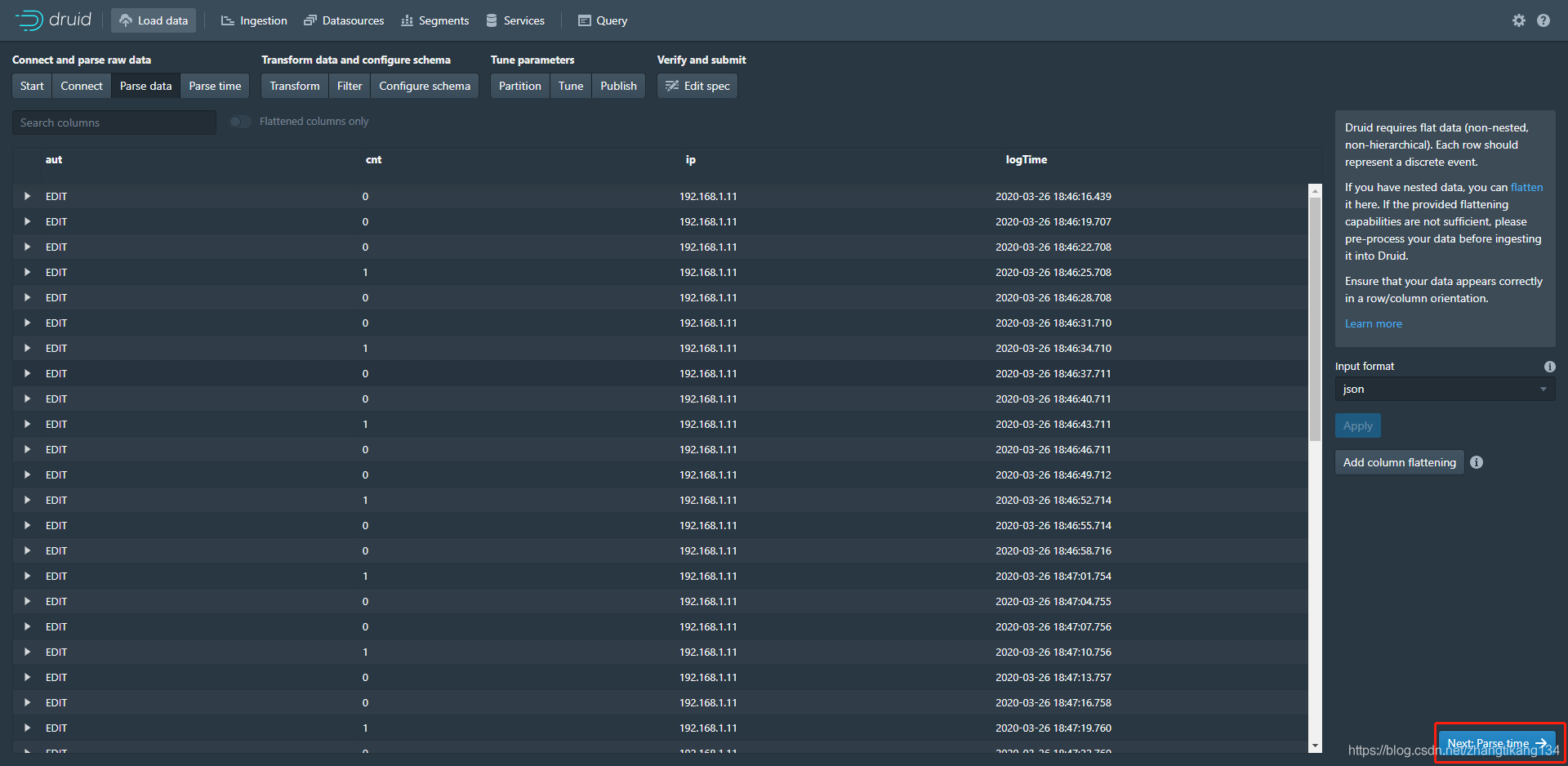 将logTime列设置为时序列__time,格式yyyy-MM-dd HH:mm:ss。
将logTime列设置为时序列__time,格式yyyy-MM-dd HH:mm:ss。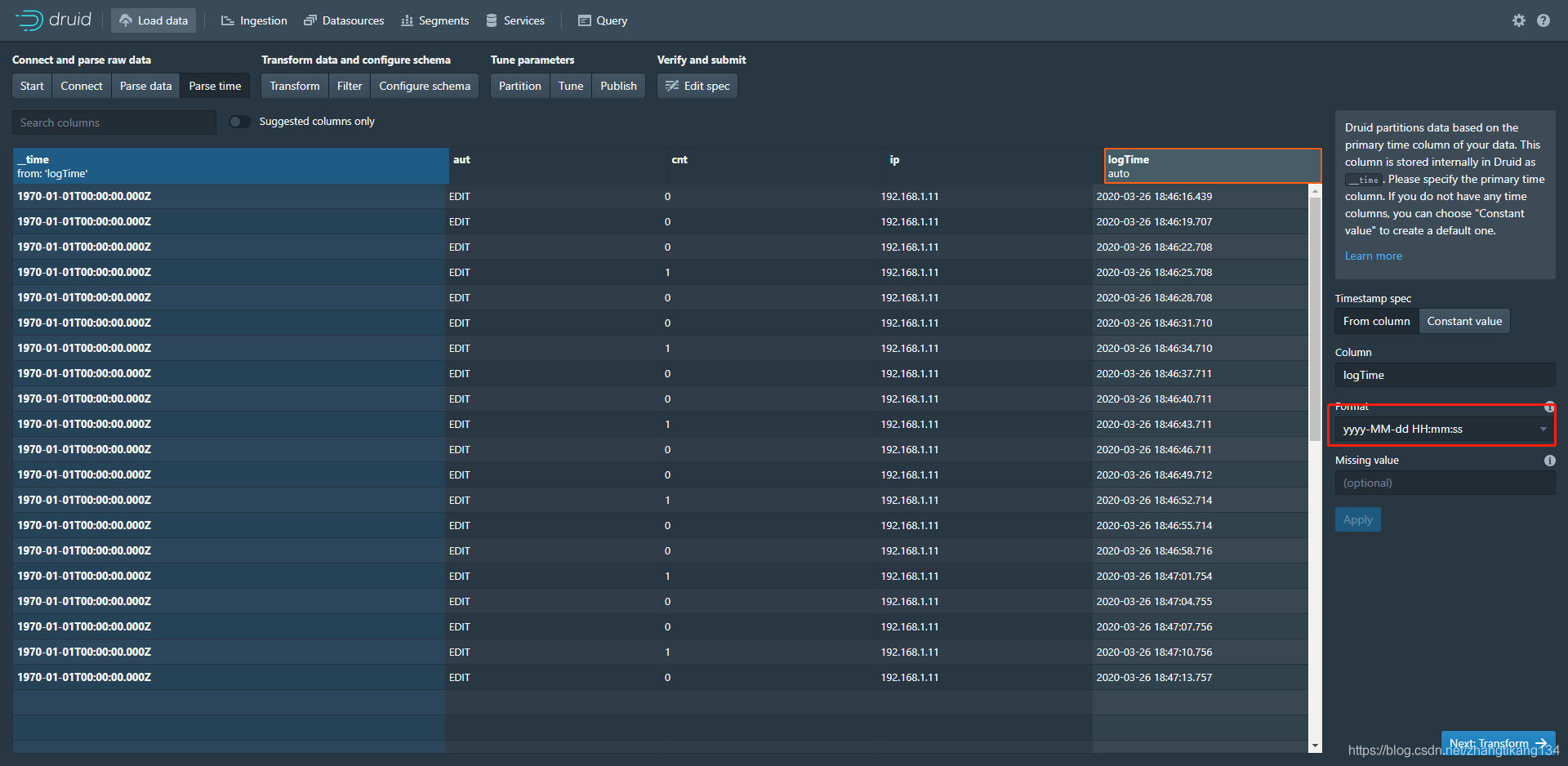
如果不需要转换Transform 或 Filter,右下角按钮连点两次跳过。
然后看到默认生成的列:
count为预聚合到一行时的总记录条数。
sum_cnt为将cnt列以longSum长整型预聚合的累计和。
其中queryGranularity设置为HOUR,意思是时序列以小时为单位预聚合上面两个值。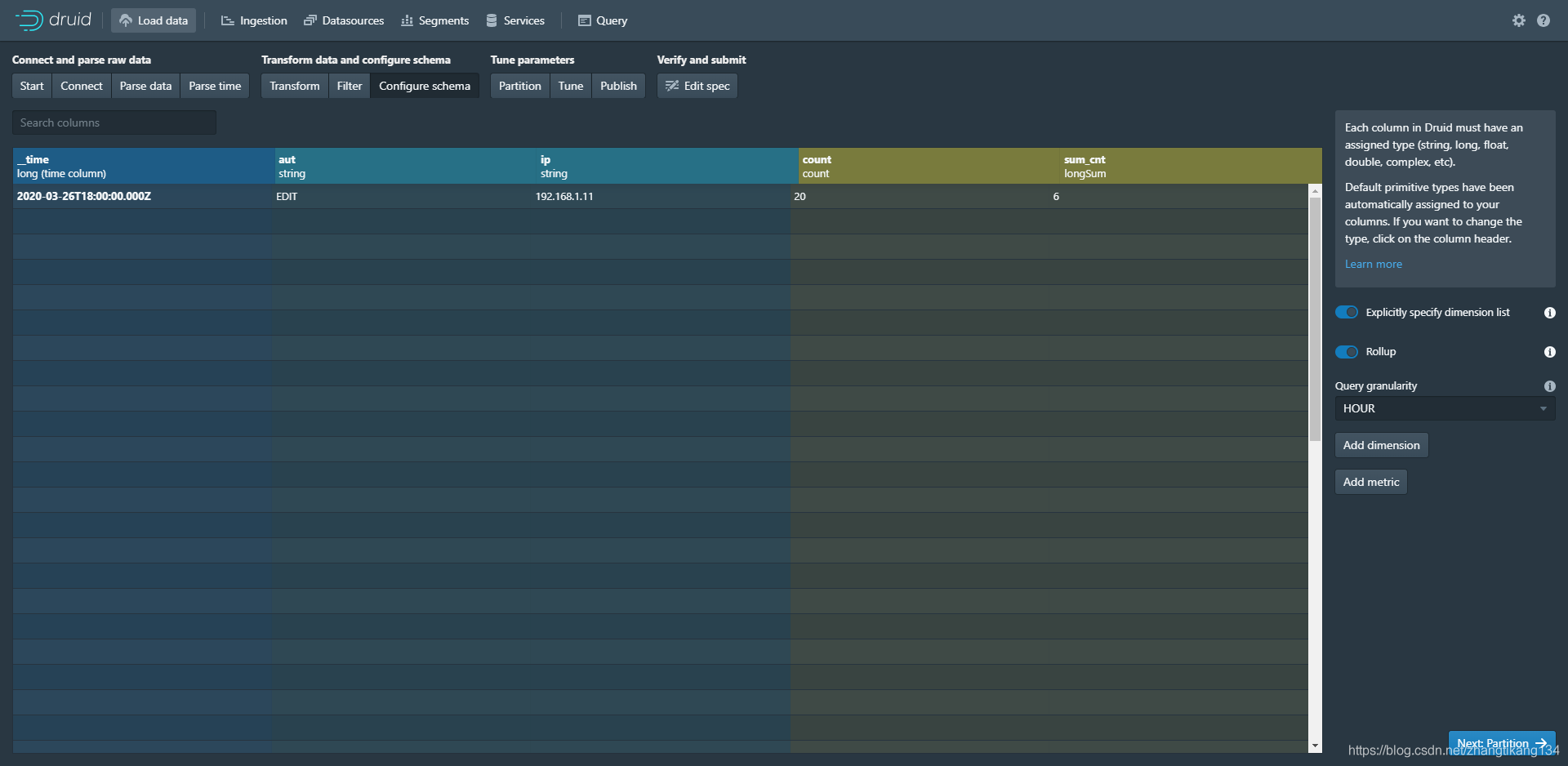
以天为单位来分配segment。如果数据跨天将会新建一个segment,日期不同;如果当前数据条数大于配置的条数,将新建一个segment,日期相同序号递增。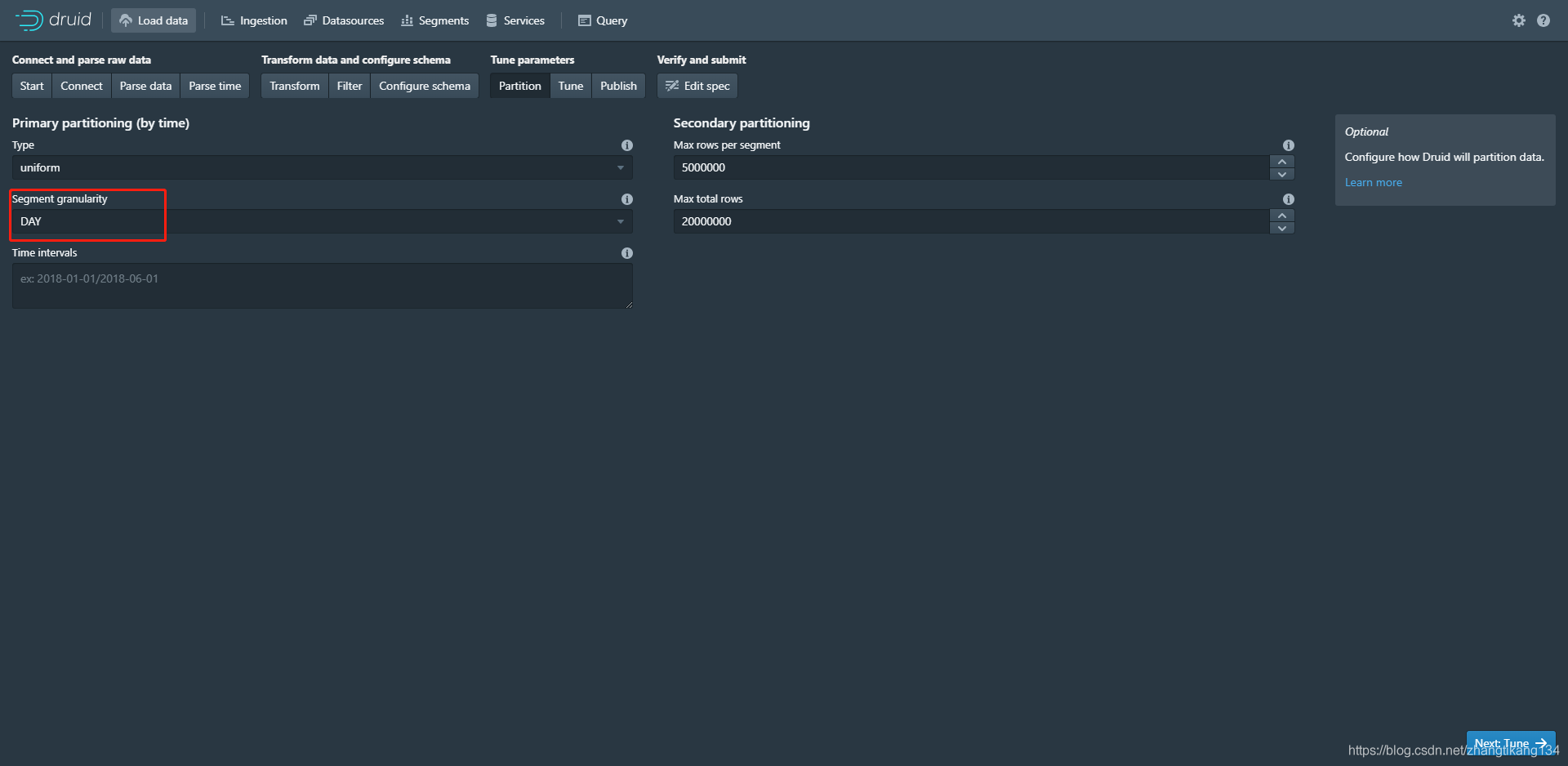
 没有要注意的地方,直接发布。
没有要注意的地方,直接发布。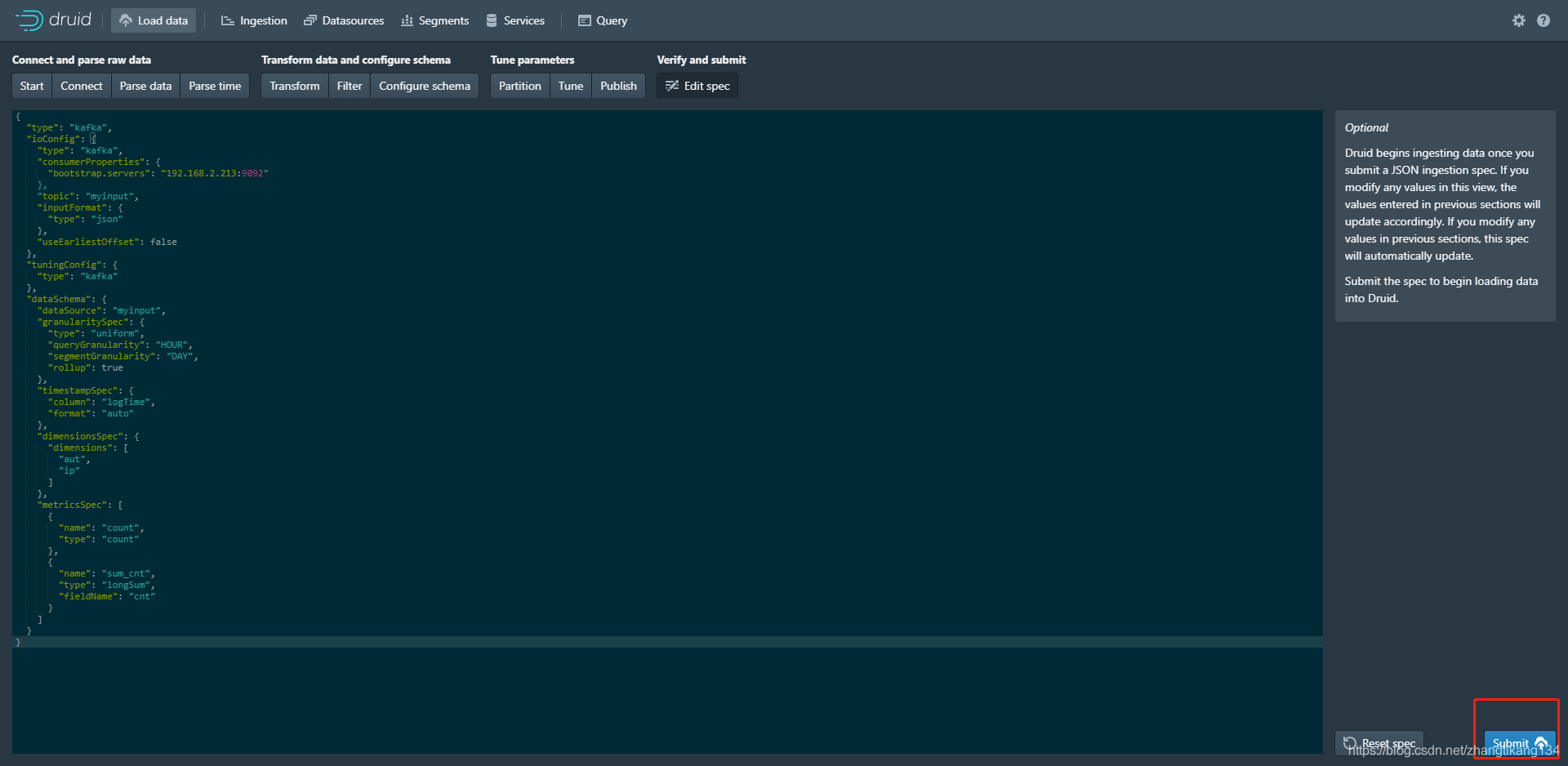 切换到Ingestion页面,看到生成一个Task。
切换到Ingestion页面,看到生成一个Task。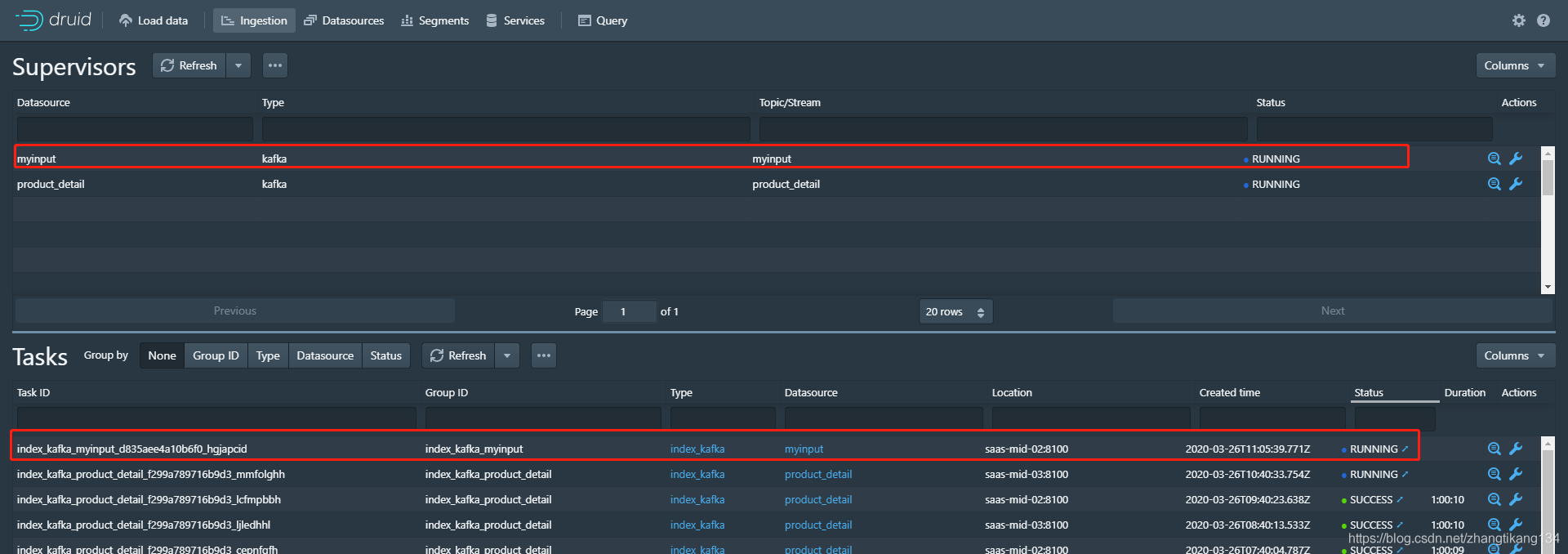 Task启动一段时间后,Datasource出现。这个相当于关系型数据库的表。
Task启动一段时间后,Datasource出现。这个相当于关系型数据库的表。 点击右边的小扳手,选择查询SQL。
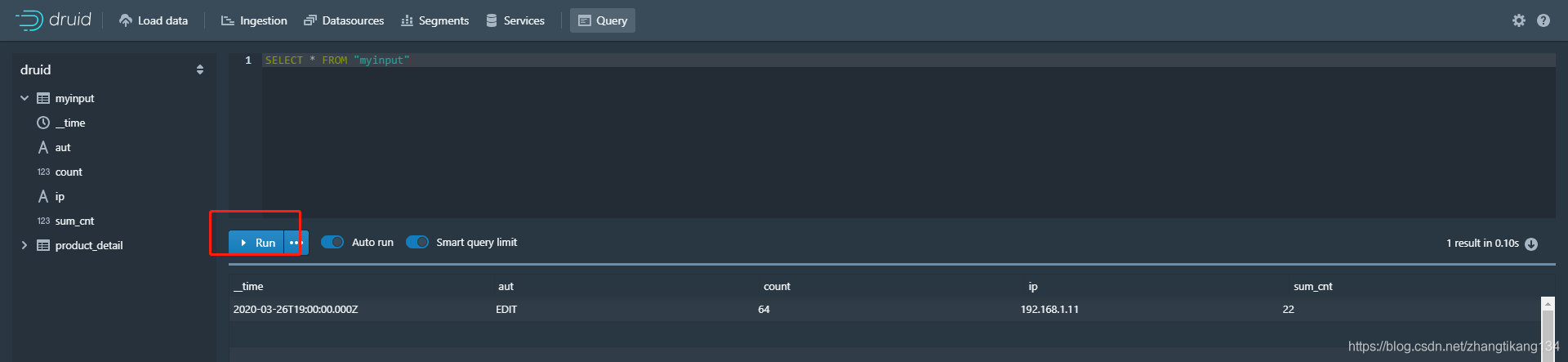
点击右边的小扳手,选择查询SQL。
现在已经消费了64条,且当前cnt之和为22.