01. 引言
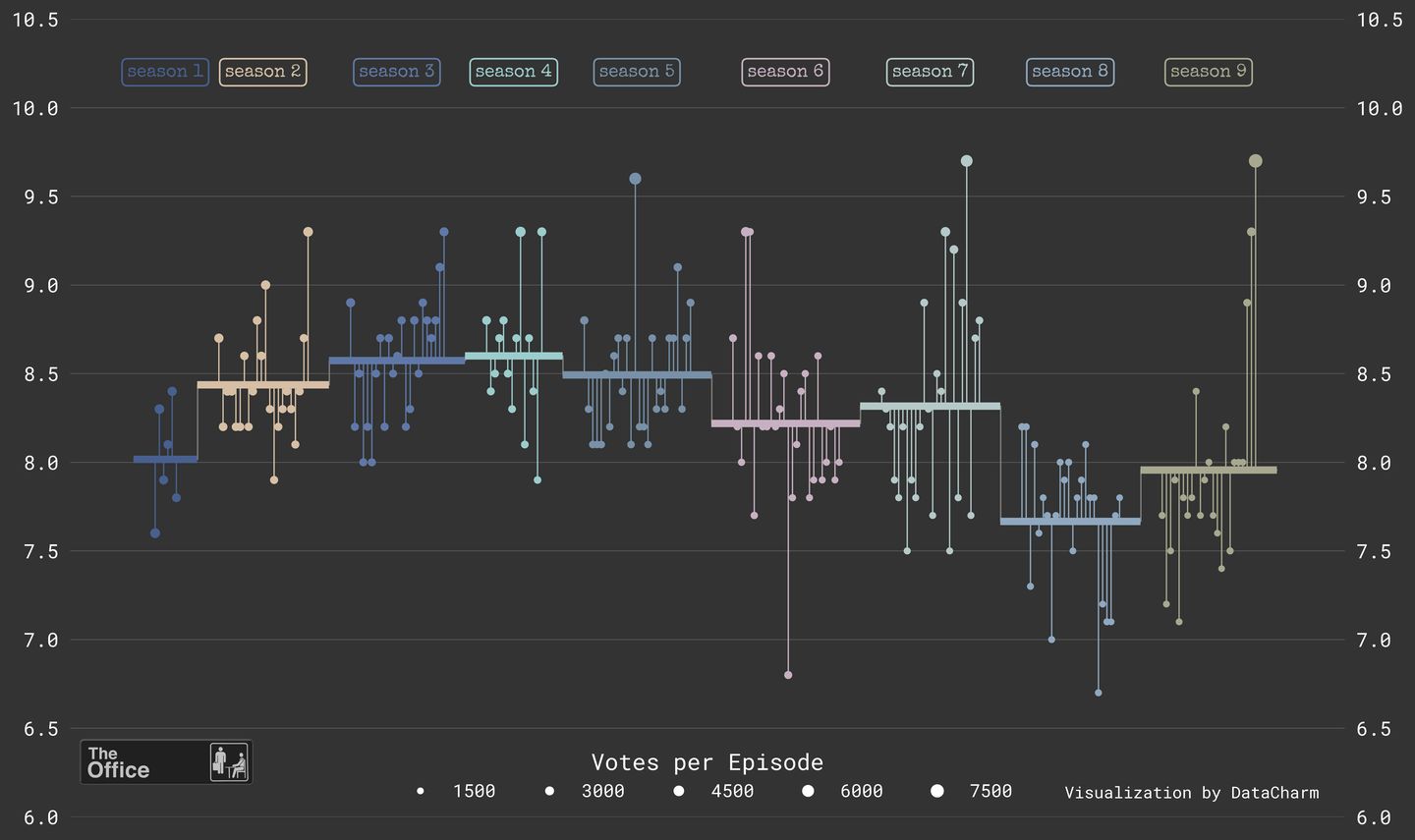
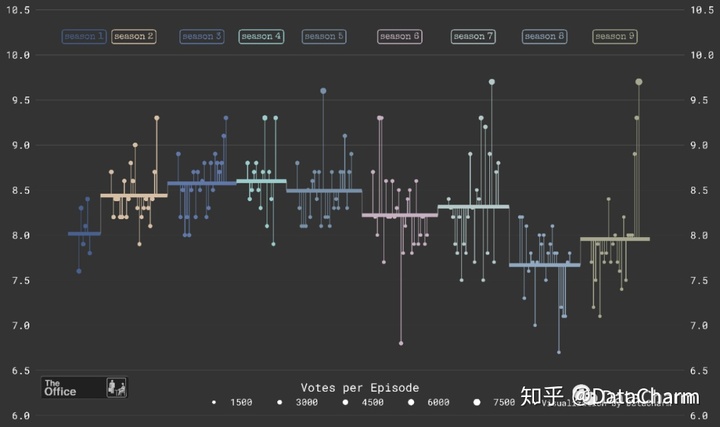
这篇推文还是python-matplotlib 散点图的绘制过程,涉及到的内容主要包括matplotlibax.scatter()、hlines()、vlines()、text()、添加小图片和定制化散点图图例样式等。前期的数据处理部分还是pandas、numpy库的灵活 应用(这里主要涉及可视化的设置,数据处理、分析部分后期会专门开设专辑进行教程讲解。当然大家有不理解地方可以后台和我交流)。可视化效果如下:
02. 数据处理
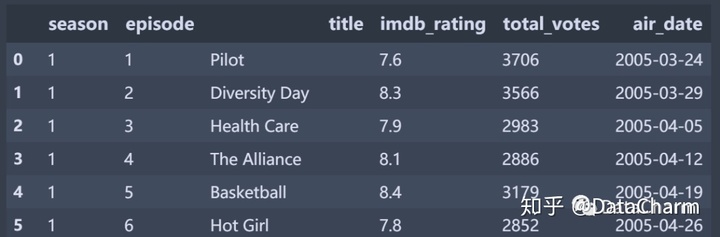
2.1 原始数据
原始数据主要如下(部分):
首先对数据进行排序操作:
#按照'season','episode' 排序操作,并将na值放置最后
office = office.sort_values(by=['season','episode'],na_position='last')这里提一下,后期构建的绘图数据集主要基于上数据集中“season”和“episode”两列数据。
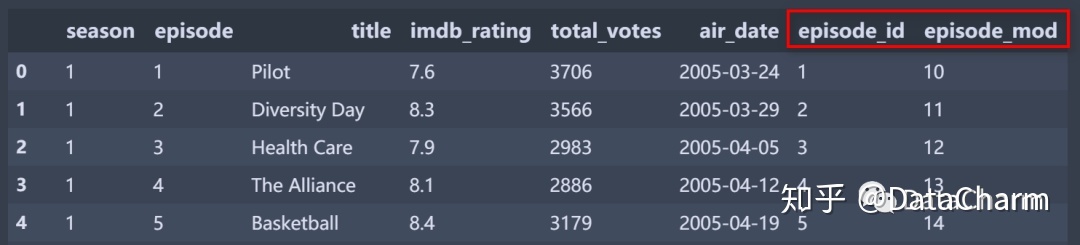
2.2 构建绘图新数据
通过如下代码构建新的特征变量:
office['episode_id'] = office.index + 1
office['episode_mod'] = office['episode_id'] + (9*office['season'])结果如下:
分组操作:
这里分组操作涉及pandas的groupby()方法,这也是数据统计分析中常用步骤,本文分组统计求取平均值的代码如下:
avg_select = office[['season','imdb_rating','episode_id','episode_mod']].groupby(by=['season']).mean()
avg_select.reset_index()网上好多咨询pandas 分组后无法像DataFrame一样进行查看,这里只需进行
reset_index()操作即可,结果如下:
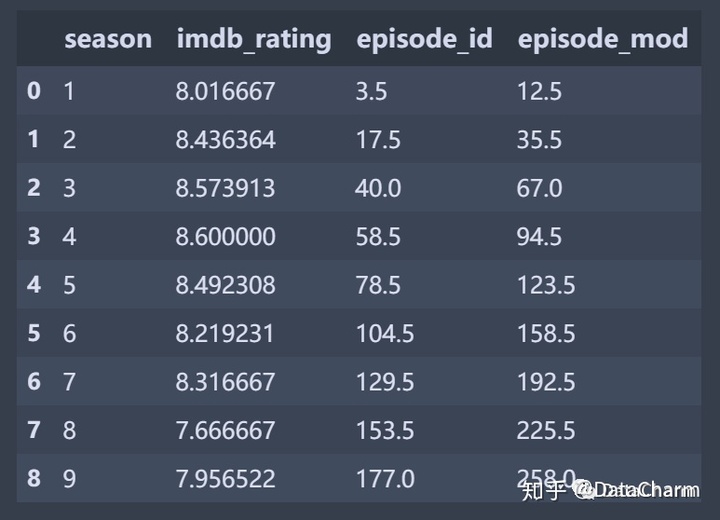
接下来一步算是比较重要的数据处理过程了,即将groupby操作后的结果转成字典,然后再根据字典结果对生成新数据。操作如下:
生成字典:
avg_select_dic = avg_select.to_dict()结果如下:
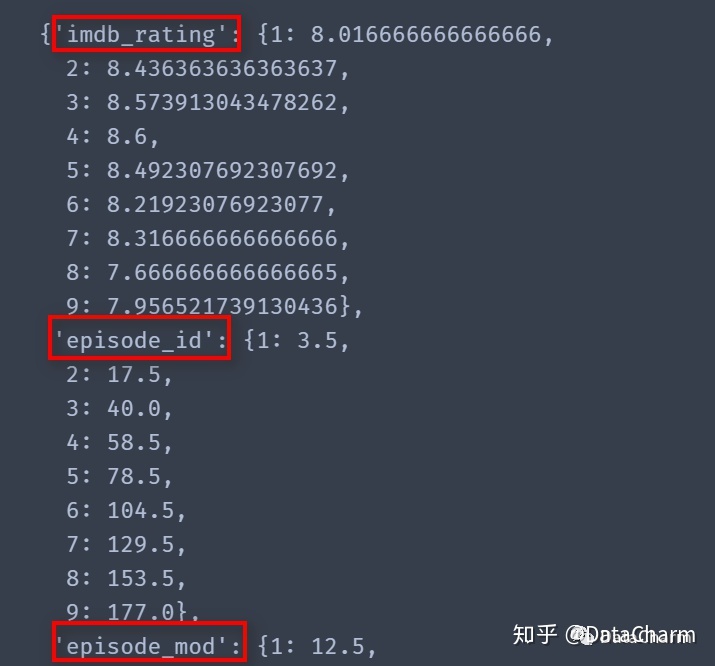
注意红框标记的地方,下面根据字典生成新的特征列数据,代码如下:
office['avg'] = office['season'].apply(lambda x : avg_select_dic['imdb_rating'][x])
office['mid'] = office['season'].apply(lambda x : avg_select_dic['episode_mod'][x])(这一步在数据处理过程中进行使用,希望大家可以直接掌握)结果如下:
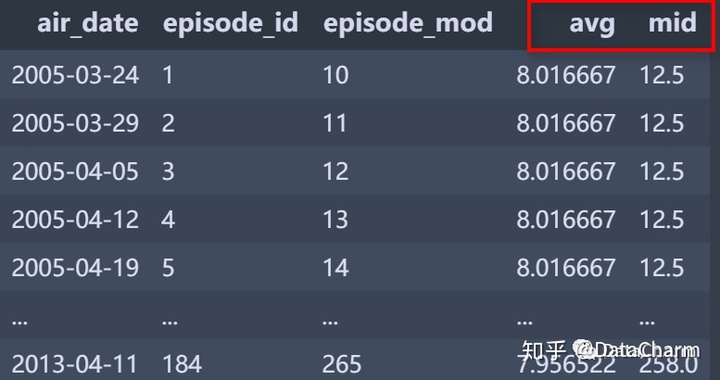
接下来的分组操作也是非常重要和根据需求操作较多的数据处理过,笔者我也是查了些资料才实现自己的需求:即groupby()后根据不同列的值生成对应不同数据操作的数据结果,大家可以直接记住此步骤。棘突代码如下:
office_line = office.groupby('season')[['episode_mod','avg']].agg(
start_x = pd.NamedAgg(column='episode_mod',aggfunc = lambda x: min(x)-5),
end_x = pd.NamedAgg(column = 'episode_mod',aggfunc = lambda x : max(x)+5),
y = pd.NamedAgg(column='avg',aggfunc = lambda x : np.unique(x))).reset_index()
office_line解释:
根据 episode_mod 列生成新特征start_x列,结果为 episode_mod 列的最小值减5;
根据 episode_mod 列生成新特征end_x列,结果为 episode_mod 列的最大值加5;
根据 avg 列生成新特征y列,结果为 avg 列的唯一值。
该操作在多数数据处理操作中经常遇到,如果觉得pandasz这样处理太过麻烦,也可以使用 R的dplyr 包的mutate()方法结合if_else操作完成。因为本文主要介绍Matplotlib可视化绘制,数据处理也尽可能使用pandas进行数据处理。结果如下:
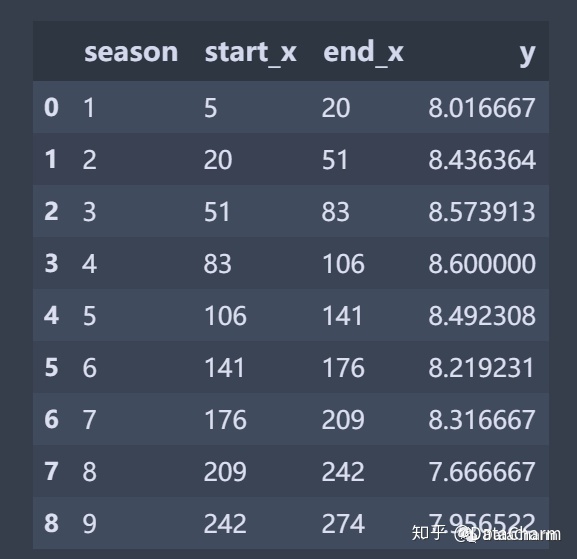
将宽数据转成长数据:
office_line = office_line.melt(id_vars=['season','y'],value_vars=['start_x','end_x'],
var_name=['type'],value_name='x')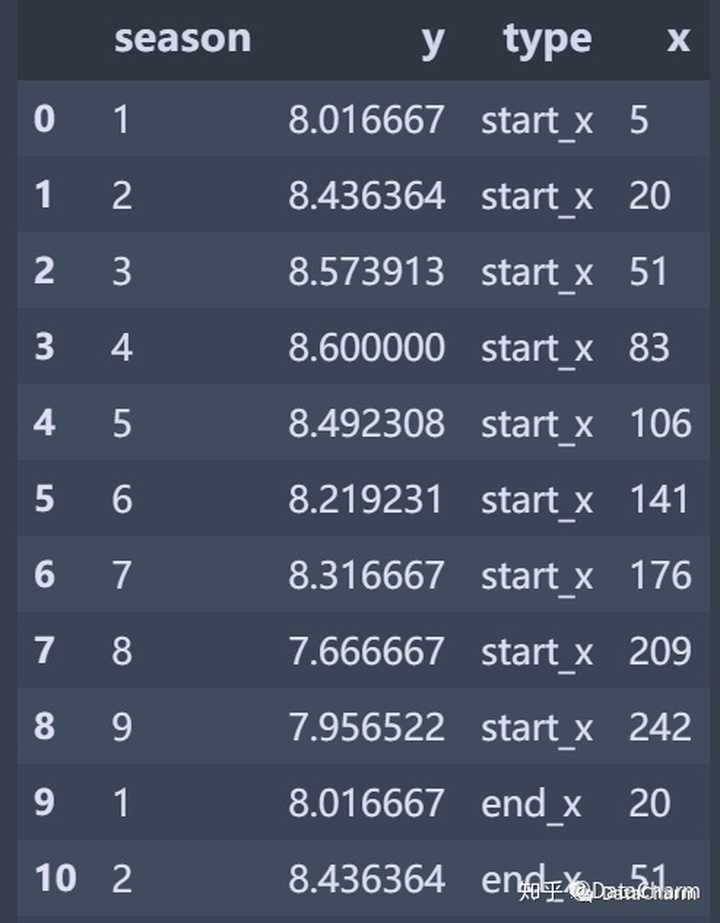
接下来的步骤也就是根据具体的需求进行特征构建,所涉及的操作步骤也就不叫简单(列表生成式结合if-else操作):代码如下:
group01 = [y+.1 if type == 'start_x' else y-.1 for x, y in zip(office_line.type,office_line['x'])]
group02 = [y-.1 if (z == 'start_x') & (x == office_line.x.min()) else y for z, x,y in zip(office_line.type,office_line['x'],office_line.x_group)]
group03 = [y+.1 if (z == 'end_x') & (x == office_line.x.max()) else y for z, x,y in zip(office_line.type,office_line['x'],office_line.x_group)]
03. 数据可视化
这里提下如下内容:
from mpl_toolkits.axes_grid1.inset_locator import inset_axes上述代码用于图片的添加,试了很多方法,还是这种效果最好,当然,如果是ggplot2 绘制的话,结合 png::readPNG()和cowplot包的draw_image()就可完美绘制。
颜色字典构建:
color = ("#486090", "#D7BFA6", "#6078A8", "#9CCCCC", "#7890A8", "#C7B0C1",
"#B5C9C9", "#90A8C0", "#A8A890")
season = office_line.season.to_list()
season_color = dict(zip(season,color))
season_color完整代码如下:
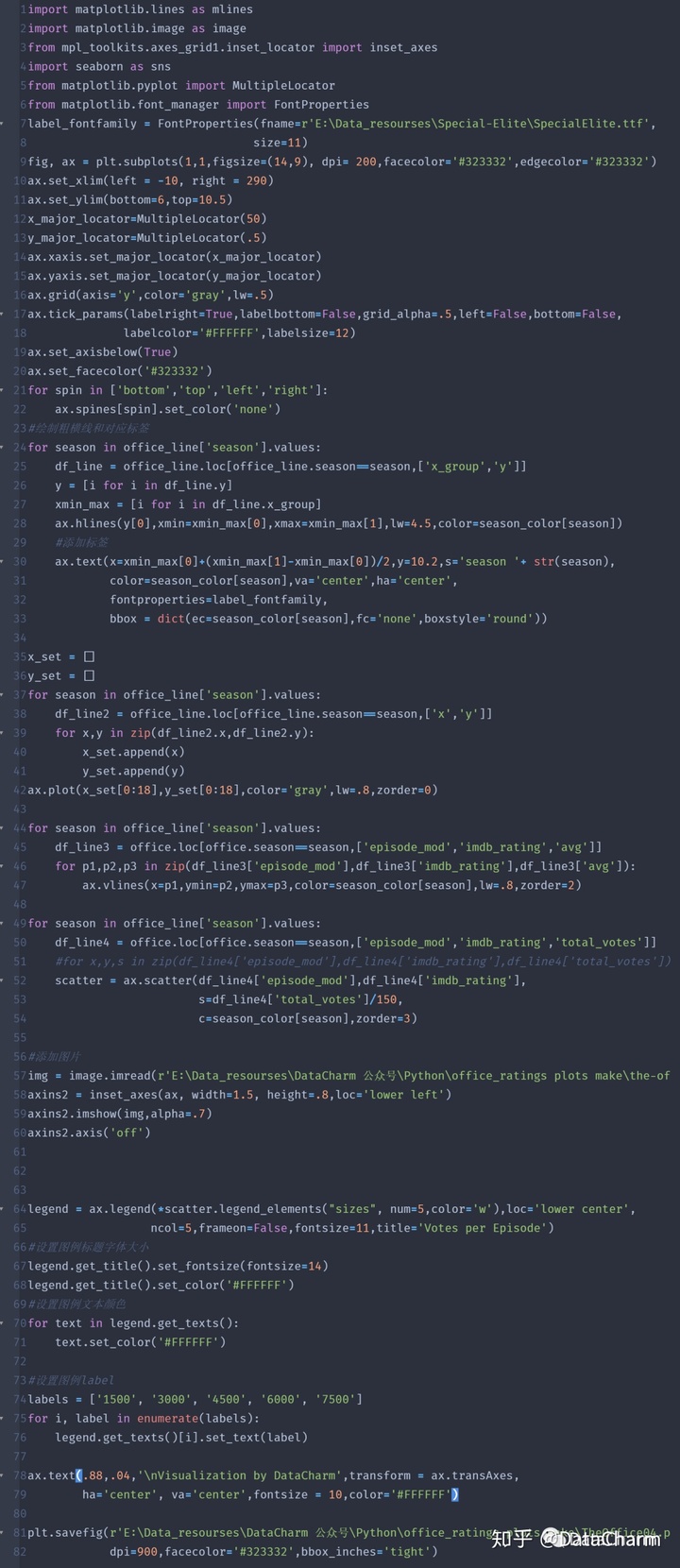
最终可视化结果如下:
04. 总结
本片绘制推文还是灵活的使用python-matplotlib进行散点图的绘制,主要涉及的绘图技巧为:ax.scatter()、 hlines()、 vlines() 以及散点图例的定制绘制,其目的就是为了熟悉绘图技巧,同时也希望为大家提供绘图灵感和帮助。后期推文会尽可能使用matplotlib绘制。ggplot2的可视化绘制图文后期也会跟上的,希望大家能够喜欢。能力有限,有错误或者不理解的地方可以后台交流或加入 DataCharm交流群进行讨论。