1.概述
是什么?
Spring Cloud Stream 是一个构建消息微服务驱动的框架。可以屏蔽底层消息中间件的差异,降低版本切换成本,统一消息的编程模型,目前仅支持 RabbitMQ 和 Kafka。
设计思想
标准 MQ 的设计思想。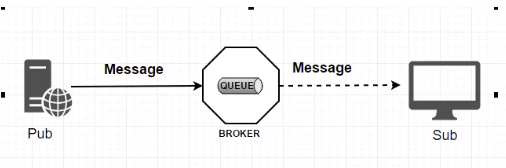
生产者 / 消费者之间靠消息媒介传递信息内容,Message
消息必须走特定的通道,MessageChannel
消息通道里的消息如何被消费呢,谁负责收发处理?消息通道MessageChannel的子接口SubscribableChannel负责发处理,由消息处理器MessageHandler所订阅后即可消费。
Spring Cloud Stream 的设计思想
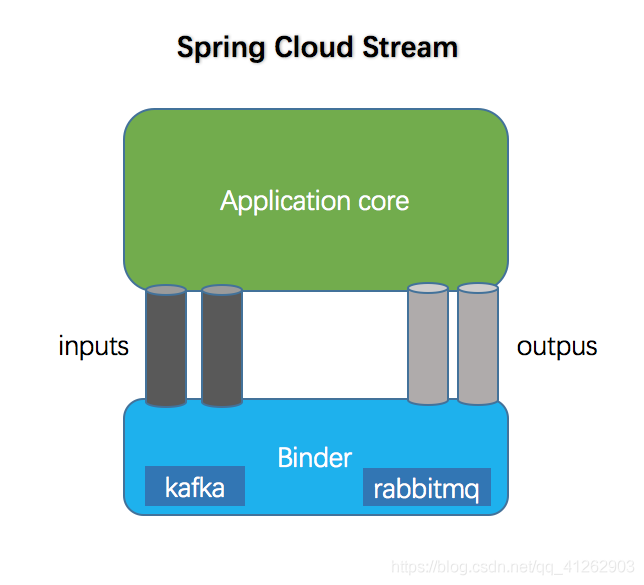
inputs 对应消费者,outputs 对应生产者
Stream中的消息通信方式遵循了发布-订阅模式,用 Topic 主题进行广播(在RabbitMQ就是Exchange,在Kafka中就是Topic)
工作流程
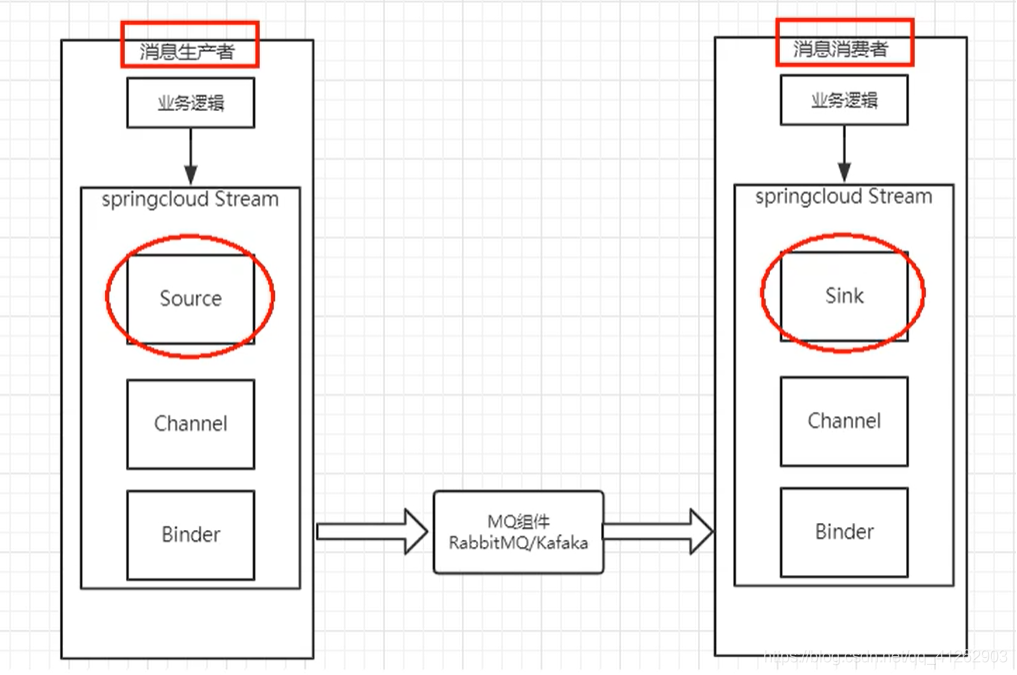
Binder:绑定器,很方便的连接中间件,屏蔽差异
Channel:通道,是队列 Queue 的一种抽象,在消息通讯系统中就是实现存储与转发的媒介,通过 Channel 对队列进行配置
Source 和 Sink:简单理解就是参照物是 Spring Cloud Stream 本身,从 Stream 发布消息就是输出(Source),接收消息就是输入(Sink)
编码 API 和常用注解
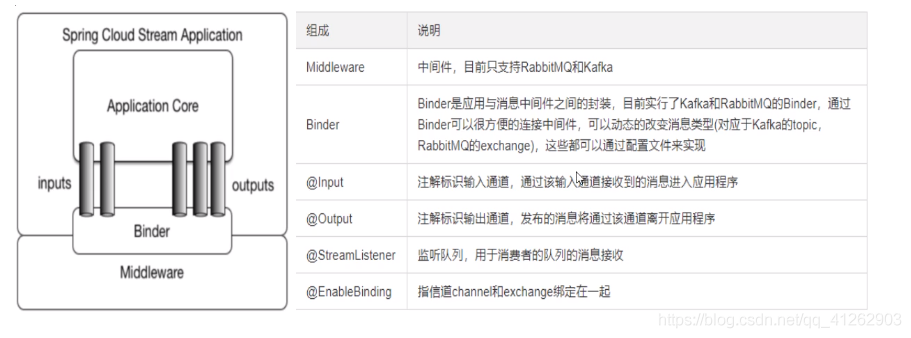
2.HelloWord
先创建一个springboot项目。
引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>配置rabbitmq:
spring.rabbitmq.host=rabbitmq地址
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.port=5672创建用于接收来自RabbitMQ消息的类:
@EnableBinding(Sink.class)
public class MyReceiver {
public static final Logger logger = LoggerFactory.getLogger(MyReceiver.class);
@StreamListener(Sink.INPUT)
public void reveicer(Object payload){
logger.info("Receiver:"+payload);
}
}启动项目这时可以从日志中看到与rabbitmq建立了连接
这时候可以在rabbitmq管理端看到已经建立了一个指向36.148.83.121的连接。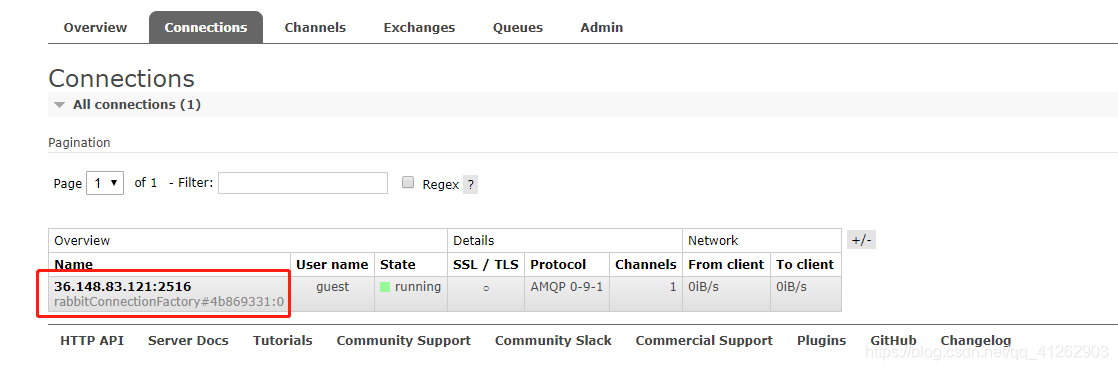
并且可以在队列列表看到一个名为input.anonymous.cXRH-vL2T5eQJoTUtHi5tQ的队列。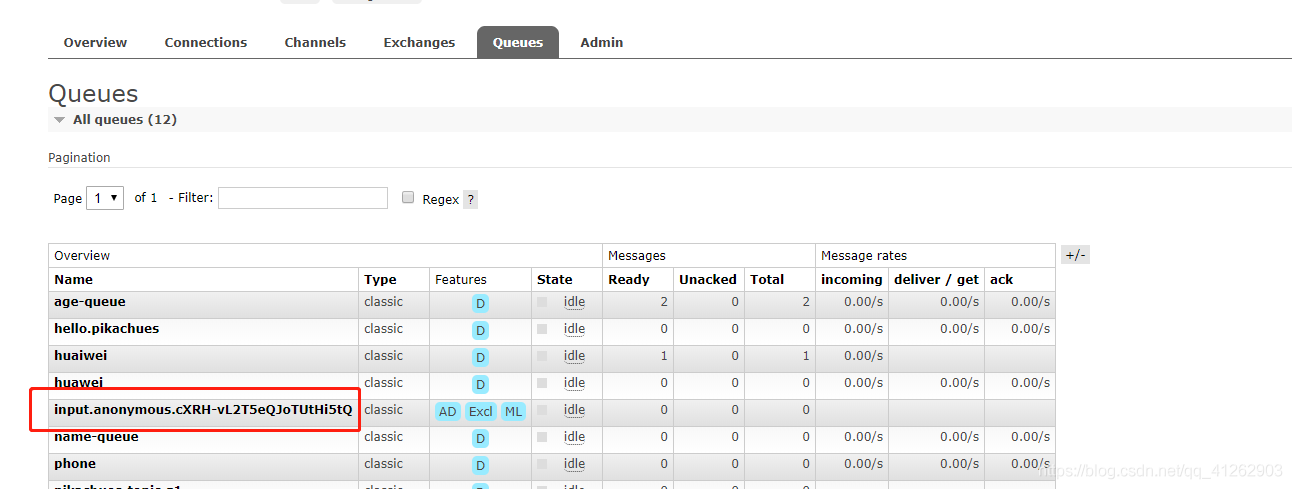
接下来进入input.anonymous.cXRH-vL2T5eQJoTUtHi5tQ的队列管理页面,通过Publish Message功能来发送一条消息到该队列中。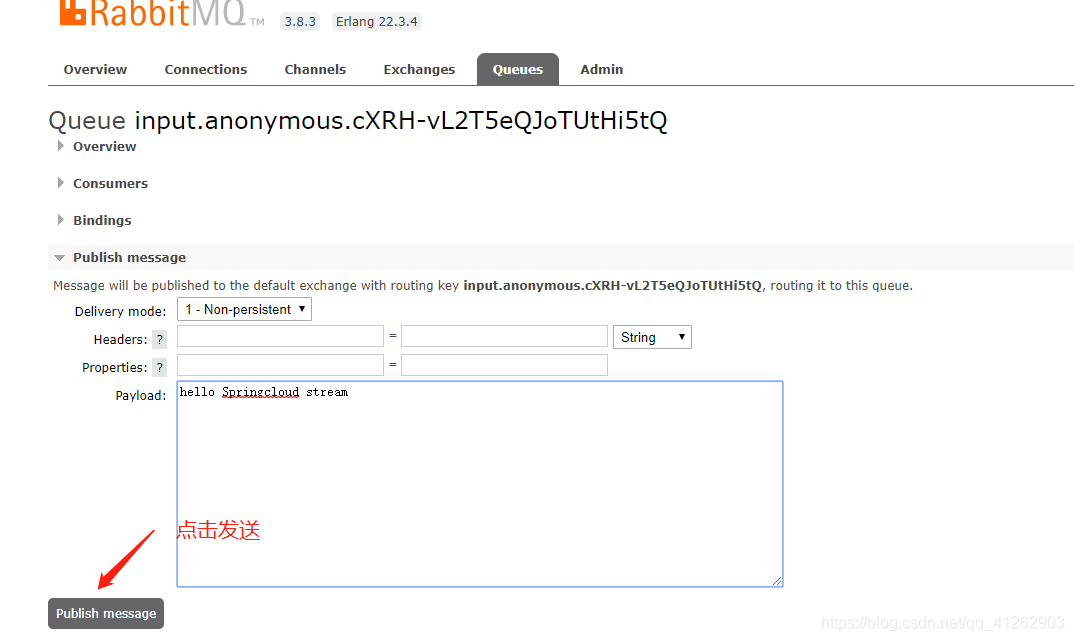
这时候可以在控制台中看到刚刚发送的消息。
3.自定义消息通道
首先创建一个名为Mychannel的接口:
public interface MyChannel {
String INPUT = "pikachues-input";
String output = "pikachues-output";
@Output(output)
MessageChannel output();
@Input(INPUT)
SubscribableChannel input();
}注意:
1.两个消息通道的名字是不一样的,不然会有问题。
2.从F版开始,默认使用通道名称作为实例命令,所以这里通道名字不可以相同(早期版本可以相同)这样的话,为了能够正常收发消息,需要我们在application.properties中做一些额外配置
下面对在application.peoperties做如下配置:
# 发送接收通道名称不同,但是主题(广播站名称)名称必须相同
spring.cloud.stream.bindings.pikachues-input.destination=pikachues-topic
spring.cloud.stream.bindings.pikachues-output.destination=pikachues-topic自定义消息的接收:
@EnableBinding(MyChannel.class)
public class MyReceiver2 {
public final static Logger logger = LoggerFactory.getLogger(MyReceiver2.class);
@StreamListener(MyChannel.INPUT)
public void receiver(Object playload){
logger.info("receiver2"+playload);
}
}自定义消息发送:
@RestController
public class SendMessageController {
@Autowired
MyChannel myChannel;
@GetMapping("/hello")
public void hello(){
myChannel.output().send(MessageBuilder.withPayload("hello springcloud stream").build());
}
}重新启动项目调用调用接口/hello,可以在控制台看到在SendMessageController发送的消息。
4.消费分组
默认情况下,如果消费者是一个集群,Sring Cloud Stream会将每一个消费者分配一个独立的匿名消费组,这时候当消息发送之后,同一个topic的每个应用都会进行消费,这就造成了重复消费。因此最好为每一个消费者指定一个消费组,防止重复消费。
消费分组只需要在配置文件中做如下配置即可:
spring.cloud.stream.bindings.pikachues-input.group=g1pikachues-input为消费者通道名称。同一个组里的不同消费者存在着竞争关系,只有一个会被消费
5.消费分区
引入了消费组之后,我们能够在消费者集群中保证每个消息只被组内的一个实例进行消费,但是我们不知道具体被哪个消费者实例所消费。这时候消息分区就能帮我们解决问题。
消费分区需要在消息提供方和消息消费方分别配置。
消费方配置如下:
# 开启消费者分区功能
spring.cloud.stream.bindings.pikachues-input.consumer.partitioned= true
# 当前消费者的总实例个数
spring.cloud.stream.instance-count=2
# 当前实例的索引号,从0开始,
spring.cloud.stream.instance-index=0消息提供方配置:
# 指定了分区键的表达式规则,例如当表达式的值为1, 那么在订阅者的instance-index中为1的接收方, 将会执行该消息.
spring.cloud.stream.bindings.pikachues-output.producer.partition-key-expression=0
# 指定消息分区的数量
spring.cloud.stream.bindings.pikachues-output.producer.partition-count= 2