Python对CSV文件的一些处理方法
该文将在jupyter notebook平台对已给csv数据进行处理。使用python3.8。用到的库有numpy,pandas,seaborn,matplotlib
目标
提供linpack、mlc、tpc、fio四个场景下所采集的数据,这些数据未作任何处理。进行数据预处理操作,并设计一个简单的分类模型,实现以上四个场景的分类功能。
数据预处理包括:合并数据集、数据清洗、数据集成、数据变换、数据规约
读入数据
对于csv文件,可以用padas库来进行读取数据
import pandasas pd
fio_Raw_data=pd.read_csv('fio_Raw_data.csv')#读入数据
fio_Raw_data.head()#显示前5行,从0行开始# fio_Raw_data.shape = (2853, 20)鉴于我们直接读入的数据可能有部分列是我们所不希望的,这里可以用padas的drop()函数进行对列(或者行)的删除。
这里已经知道给定的csv文件有20列,其中有1列为我们用不到的
fio=fio_Raw_data.drop(['Unnamed: 0'],axis=1)#去掉这几列变为18个特征,加1个类别
fio.head()数据预处理
合并数据集
因为我们要对整个数据进行分类,所以最好将这4个csv文件进行合并。这里用到padas中的concat()函数。
其详细内容在https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html可查。
对于concat有:
pd.concat(
objs,
axis=0,
join="outer",
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True,
)因为4个数据我们要忽略他们的索引,具体代码如下
#合并数据集
frames=[fio,linpack,mcl,tpc]
merge_Raw=pd.concat(frames,ignore_index=True)
merge_Raw数据清洗
缺失值检查
对采集的数据集进行缺失值检查,若出现缺失值可以采用删除法,替换法、插补法等多种方法。
可以用isnull()函数来检查是否存在缺失值。(只能检测NaN,如果有特殊的缺失值可以先用replace()函数转换为NaN)
如果存在缺失值,使用pandas的dropna()函数进行去除(该函数为删除整行)。或者使用fillna()函数替换(只替换NaN)
#缺失值检查
merge_Raw.isnull().sum()异常值处理
异常点在预测问题中是不受开发者欢迎的,因为预测问题通产关注的是整体样本的性质,而异常点的生成机制与整体样本完全不一致,如果算法对异常点敏感,那么生成的模型并不能对整体样本有一个较好的表达,从而预测也会不准确。
在正态分布数据中,我们认为当前值与均值之差如过超过3倍标准差,那么可以将其视为异常值。而如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
∣
x
−
m
e
a
n
∣
>
3
∗
s
t
d
|x-mean|>3*std∣x−mean∣>3∗std
#绘制fio各个类别的和核密度图(kde)#AxesSubplot如何保存成图片for iin columns[0:18]:
plt.figure()
fig=fio[i].plot(kind='kde',title='fio_'+i)
fig.get_figure().savefig('../1 Data Mining/fio_kde/fio_'+ i+'.png')核密度估计其实是对直方图的一个自然拓展。DataFrame.plot(kind=‘kde’,subplots=True),这里用subplots只是在一张画布上进行子图绘制。由于画布大小固定,而子图数目较多,所以会导致每张子图被严重压缩。
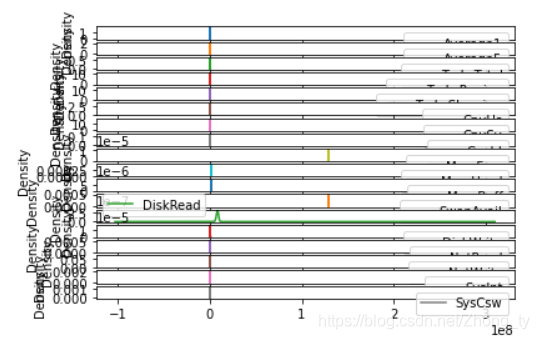
所以这里用循环+新建画布进行图片绘制与保存。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Al9huge3-1616141137440)(C:\Users\123\AppData\Roaming\Typora\typora-user-images\image-20210315152426954.png)]](http://img.555519.xyz/uploads/20220616/f08be083e9cb0cecec2acde4a1412fdf.jpg)
原数据如下:
| 场景 | 总数据量 |
|---|---|
| fio | 2853 |
| linpack | 2736 |
| mcl | 3065 |
| tpc | 5889 |
删除异常值后的数据:
| 场景 | 总数据量 |
|---|---|
| fio | 2515 |
| linpack | 2244 |
| mcl | 2766 |
| tpc | 5472 |
数据集成
进行相关系数的热力图分析。
用corr()函数计算相关系数,之后用seaborn库中的heatmap()函数绘制热力图。
这里计算相关系数要对整体计算,如果之对于某一个而言。因为存在某一列的标准差为0,导致相关系数返回为空值(函数自身定义)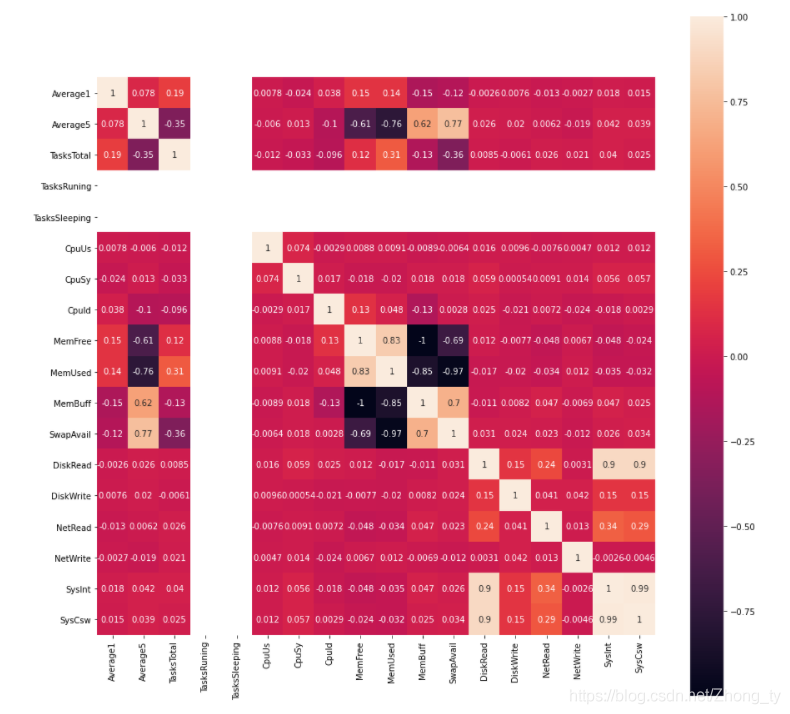
发现中间存在空白值,这是因为两类数据全部相等,导致标准差为0,根据互相关系数的公式,标准差是要作为分母的,故corr()函数规定在这种情况下,相关系数值为NaN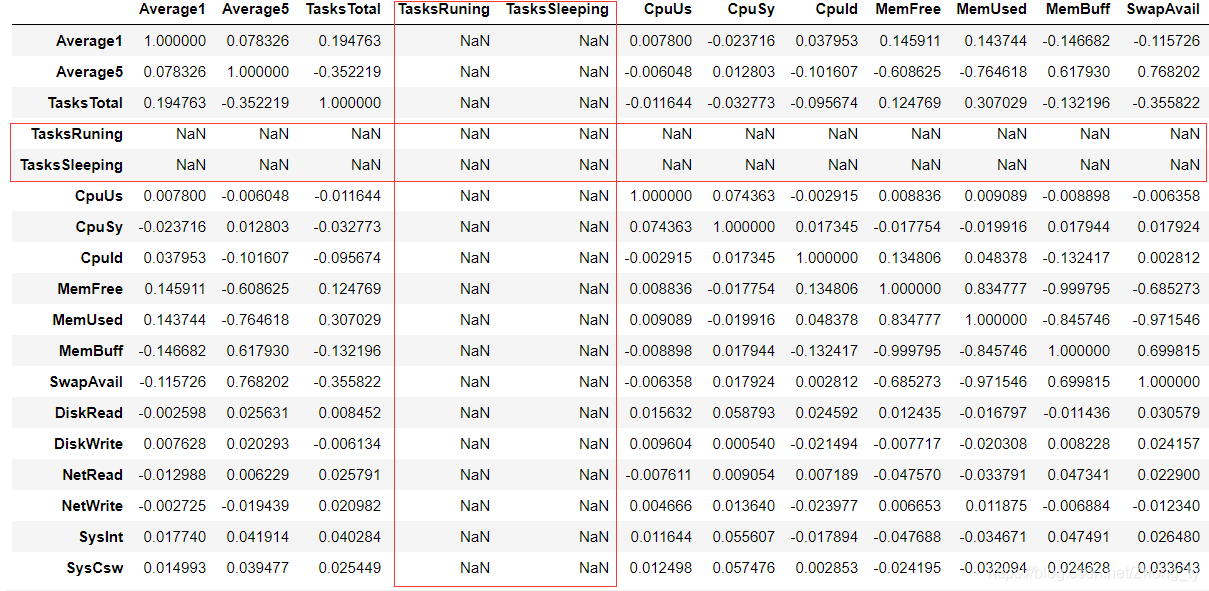
#绘制热力图import seabornas sns
frames_removed=[fio_removed,linpack_removed,mcl_removed,tpc_removed]
merge_removed=pd.concat(frames_removed,ignore_index=True)#一共删除了1054条数据
merge_removed
plt.figure(figsize=(20,15))
fig=sns.heatmap(merge_removed.corr(),annot=True,fmt='.2f')
fig.get_figure().savefig('merge_removed_heatmap.png')后来对整体处理过的数据进行concat合并,再做相关性热力图分析得到的热力图如下所示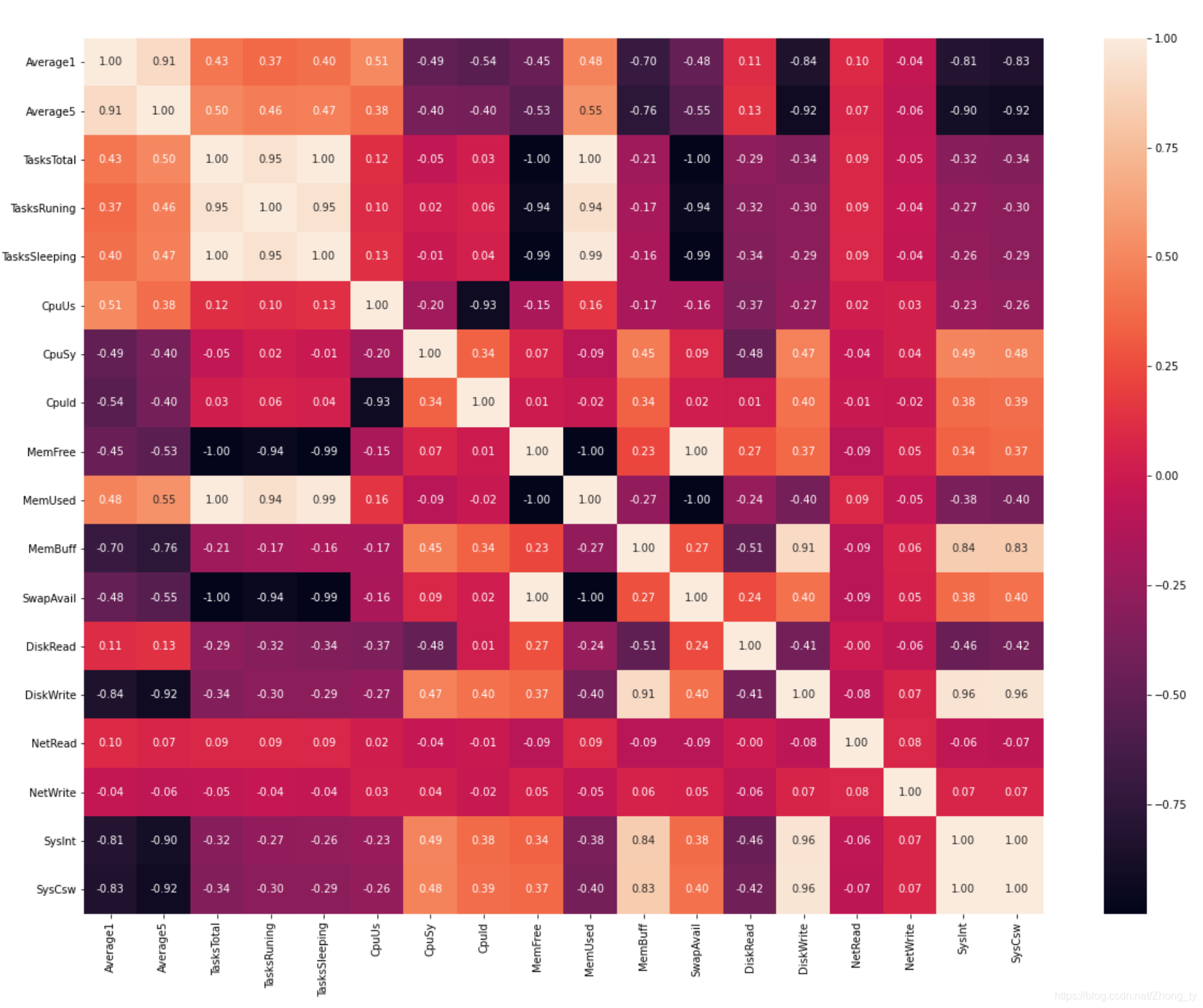
其中TasksTotal与TsaksSleeping,MemFree,MemUsed,SwapAvail呈线性相关;SysInt和SysCsw呈线性相关;TasksTotal与TasksRuning呈高度相关(相关系数为0.95)
所以保留他们中的一个。这里剔除了TasksRuning, TasksSleeping, MemFree, MemUsed, SwapAvail, SysCsw这六个特征。
剔除后的热力图如下图所示。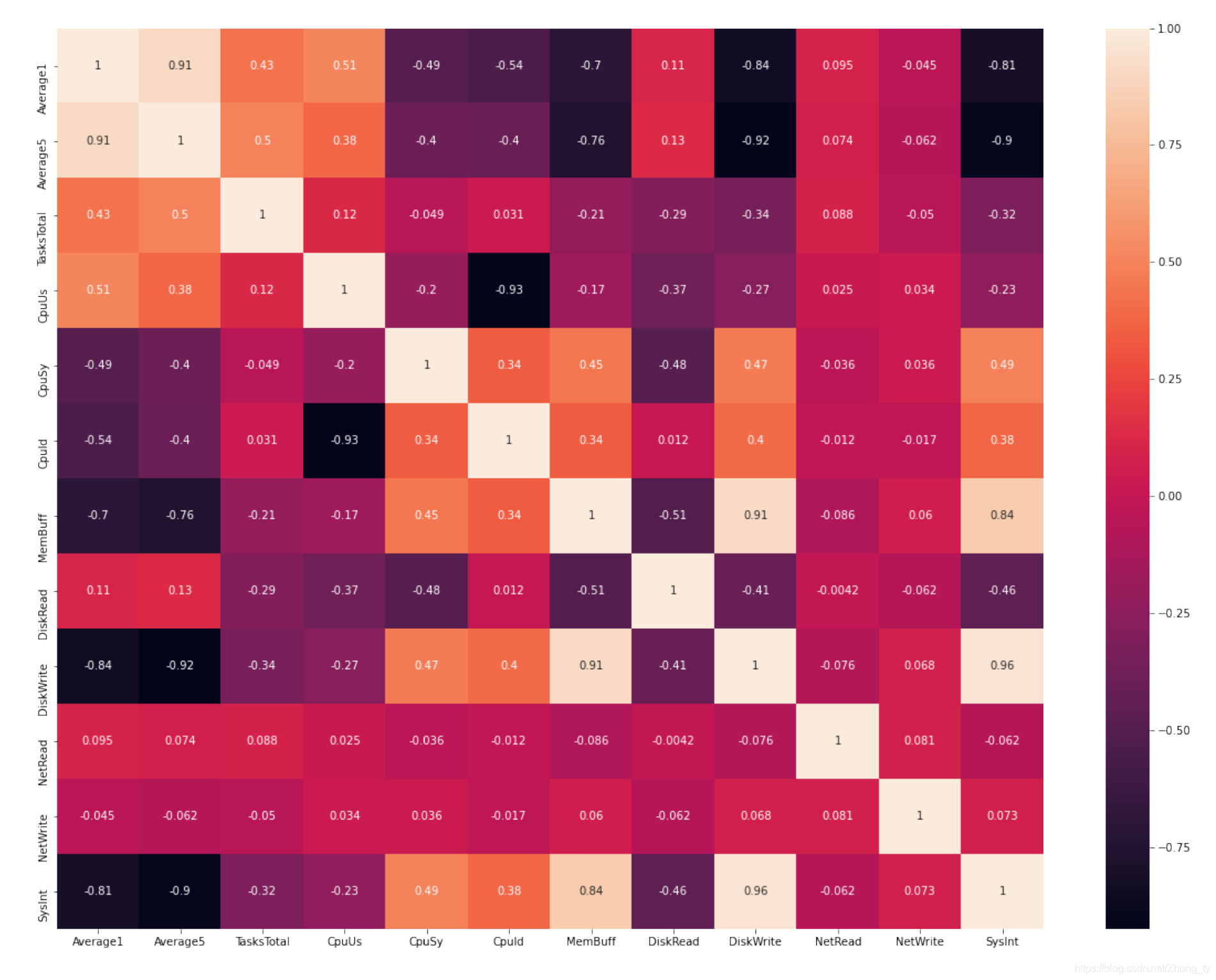
数据变换
如果样本各特征的量纲和数量级不均衡,在使用梯度下降算法时,不同的特征对模型参数的影响程度就会不一样。数据变换让不同的特征具有相同的尺度,这样在进行训练时各特征就能公平的调整模型参数。
绘制箱线图观察
import seabornas sns
sns.set_theme(style="whitegrid")
fig=sns.boxplot(x="Average1", y="species", data=merge_features_removed)
fig.get_figure().savefig('boxplot/Average1_boxplot.png')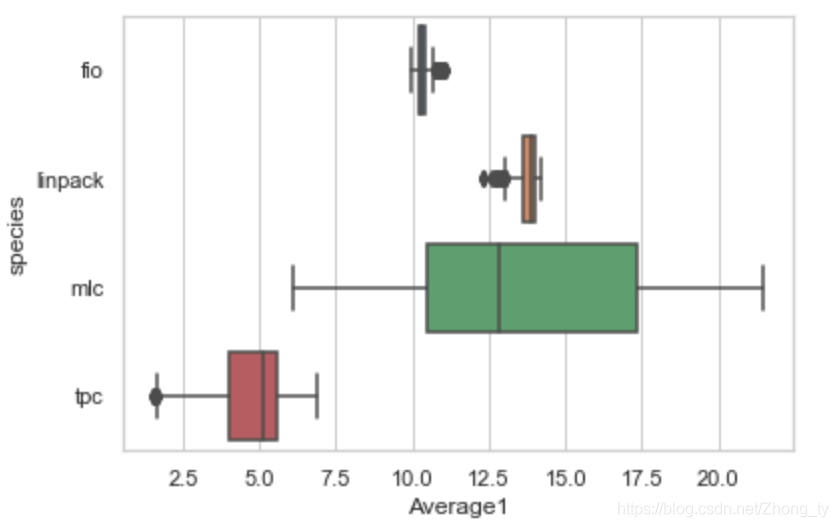

通过观察发现,样本各特征的量纲和数量级不均衡。要进行标准化
x
∗
=
x
−
m
i
n
m
a
x
−
m
i
n
x^*=\frac{x-min}{max-min}x∗=max−minx−min
x ∗ = x − m e a n s t d x^*=\frac{x-mean}{std}x∗=stdx−mean
这里采用标准差标准化的的方法,结果如下: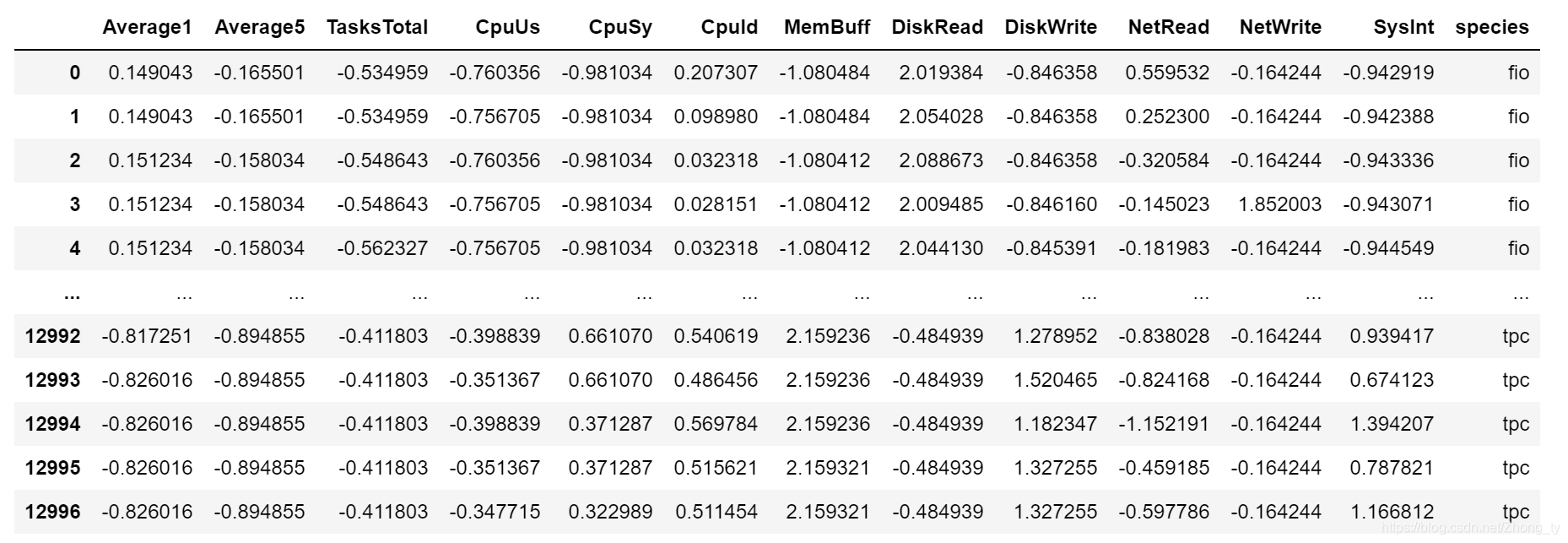
数据均衡处理
得到我们想要的最终数据还要查看各个场景下的数据量差别是否大,这将影响到下一步的训练。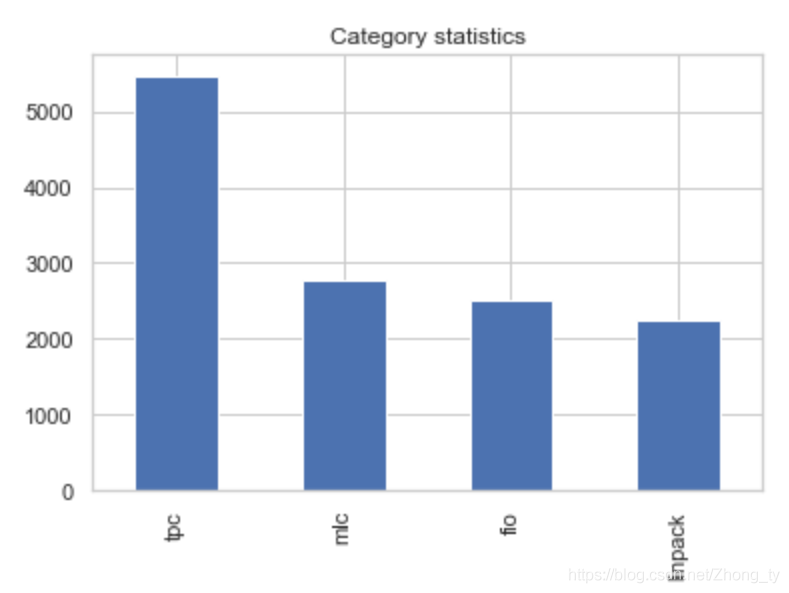
这里使用sample()函数对tpc类数据进行抽样,sample()函数的参数如下:
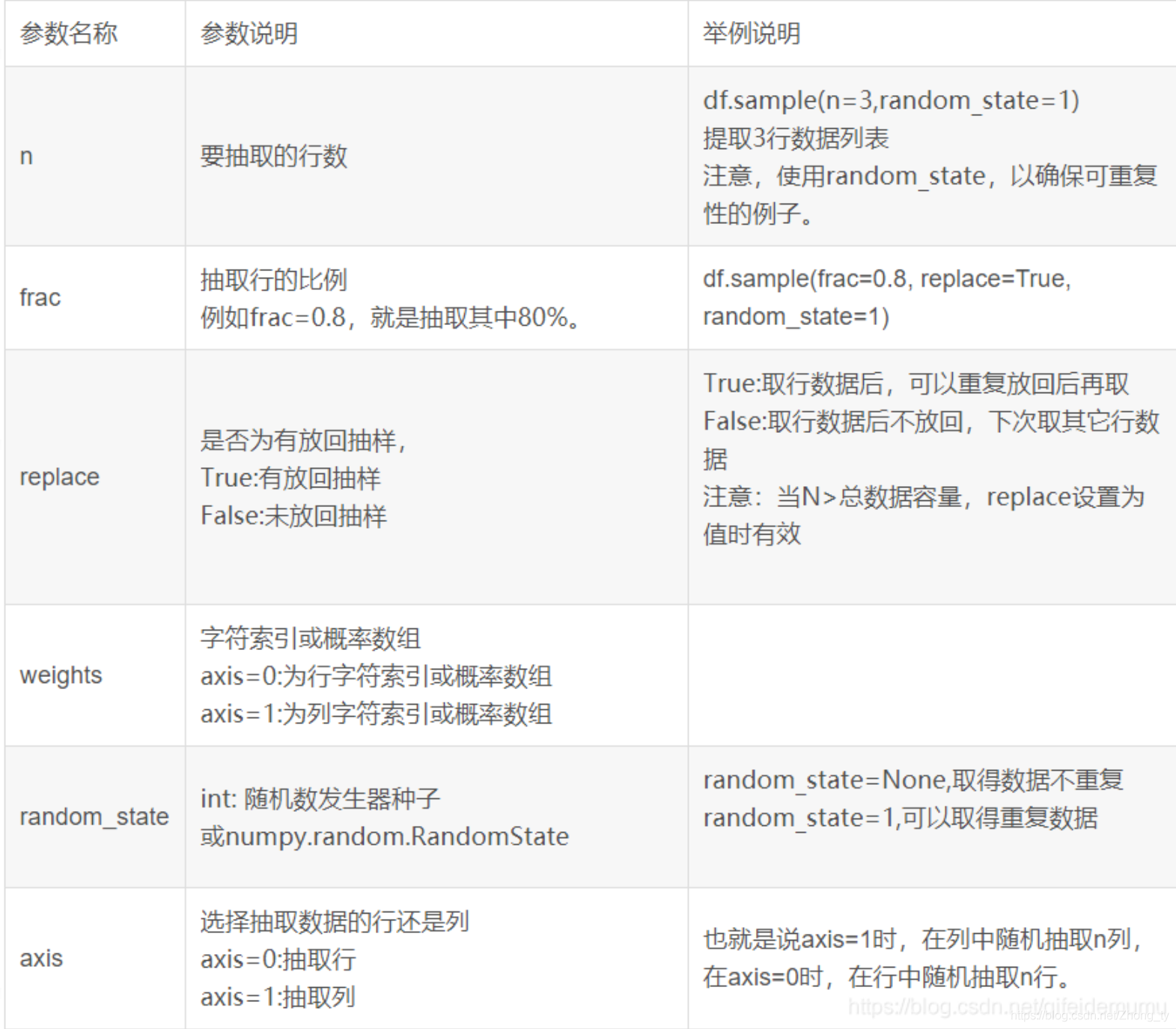
choice_num=(len(merge_final_std[merge_final_std['species']=='mlc'])+len(merge_final_std[merge_final_std['species']=='fio'])+len(merge_final_std[merge_final_std['species']=='linpack']))/3
merge_sample_tpc=merge_final_std[merge_final_std['species']=='tpc'].sample(n=int(choice_num), frac=None, replace=False, weights=None, random_state=None, axis=None)#将随机抽样的部分幅值给原数据
merge_final_std[merge_final_std['species']=='tpc']=merge_sample_tpc随机抽样处理后: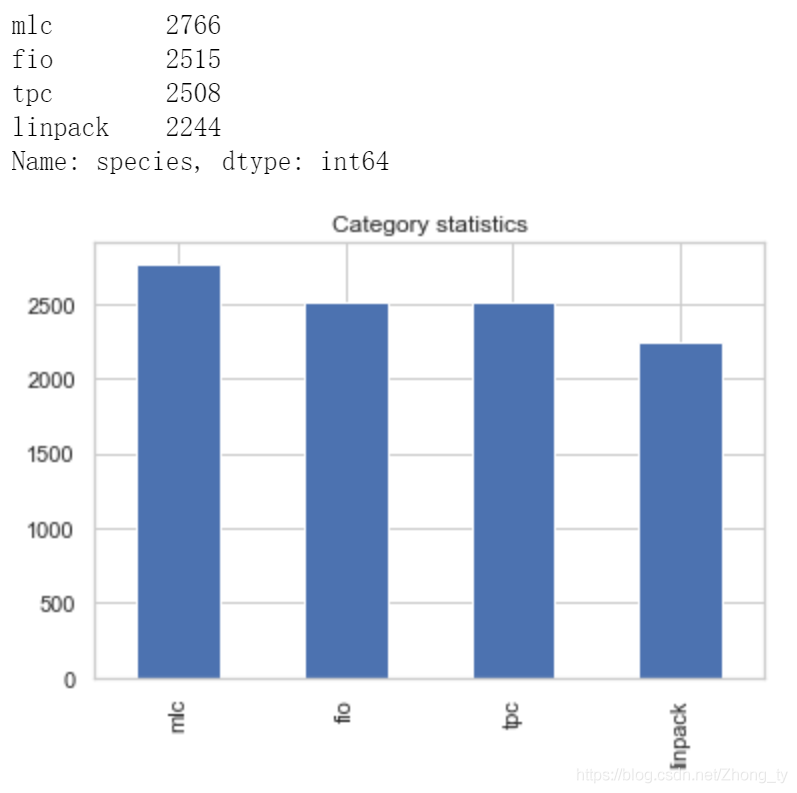
注意到原本的index不会重置,导致存在NaN的存在,所以这里把空值丢掉,并保存为csv文件,以便接下来对数据进行训练
#随机抽样后,原本的index不会重置,导致存在NaN的存在
merge_final_std=merge_final_std.dropna(how='any')
merge_final_std.to_csv('Data_processed.csv',index=False)注意到原本的index不会重置,导致存在NaN的存在,所以这里把空值丢掉,并保存为csv文件,以便接下来对数据进行训练
#随机抽样后,原本的index不会重置,导致存在NaN的存在
merge_final_std=merge_final_std.dropna(how='any')
merge_final_std.to_csv('Data_processed.csv',index=False)