Kafka要点
1 kafka 一些特性问题
2 kafka 服务端高并发,高性能,高可用架构设计
3 kafka Producer 高性能架构设计
4 kafka consumer 稳定性设计
5 kafka 设计和调优kafka 一些特性问题
1 kafka broker节点之间的主从选举
谁先在zk创建znode目录就是主节点
2 如何解决主节点单点故障问题
从节点都会监听主节点创建的目录,一旦主节点故障,其余从节点就会重新抢占
3 kafka 主节点(controller/follower broker节点)作用
主节点监听zk元数据变化,一旦变化主节点就会更新存储元数据,再同步元信息给所有从节点
4 主从副本 replica 特点
生产消费数据都只作用于主副本(即主partition),主副本作从副本的数据同步,从副本不干活
主partition也会负载均衡在不同的broker上,分散主副本的读写压力
5 kafka 更多是对等式架构,不算严格意义上的主从架构。主从仅仅在元数据在管理kafka 服务端高性能架构设计
处理服务端请求架构设计 Reactor 设计模式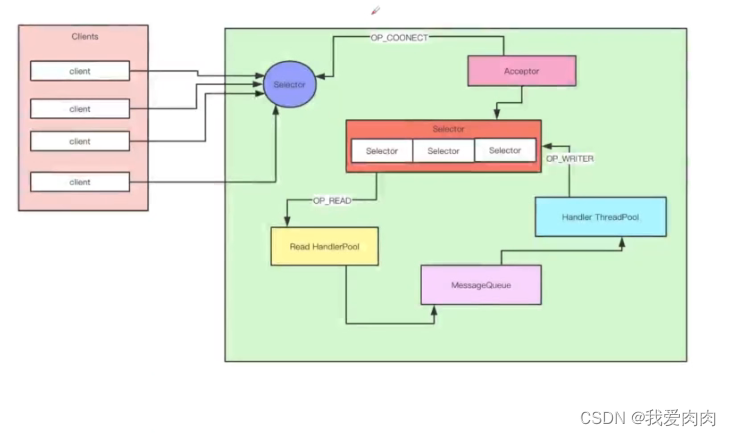
一个selecor轮询处理连接请求,多个selector轮询处理读写请求,通过MessageQueue做读写缓存(解决读写处理速度不一致问题)左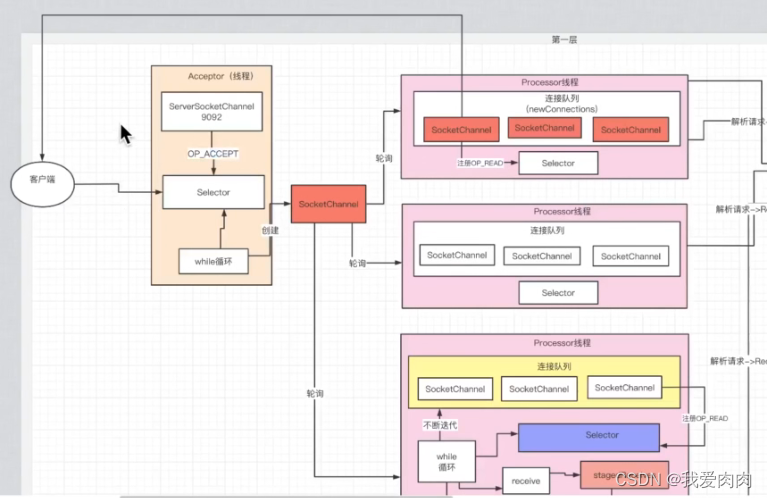
左下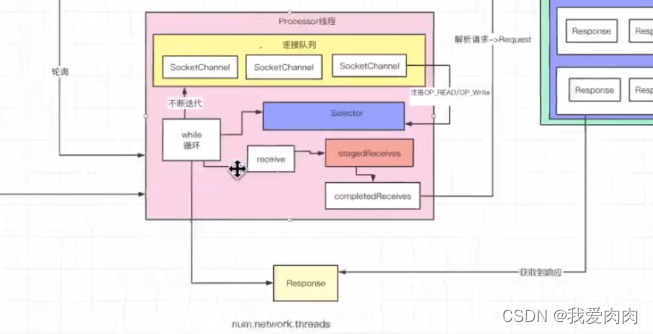
作用:响应发送客户端
kafka配置 num.network.threads 默认值为3,即processor线程数量为3,可手动修改配置中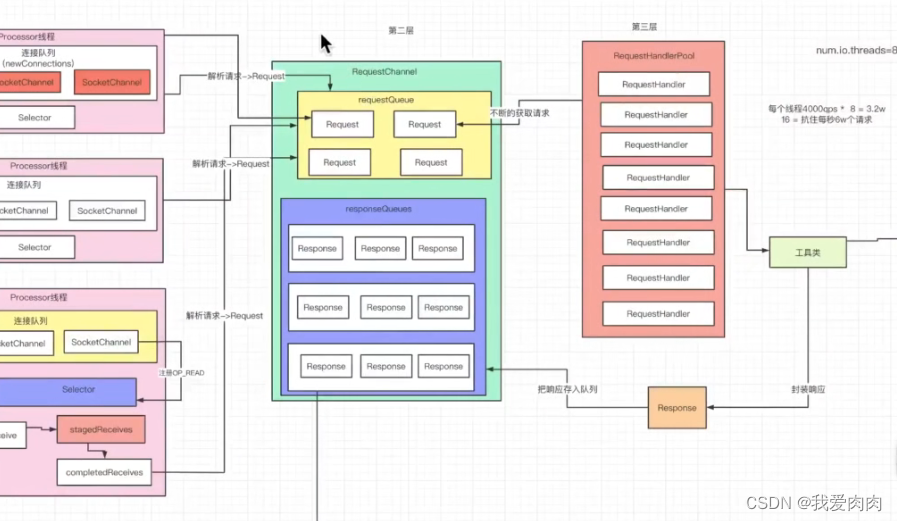
第二层:起缓存作用,即全局图的MessageQueue右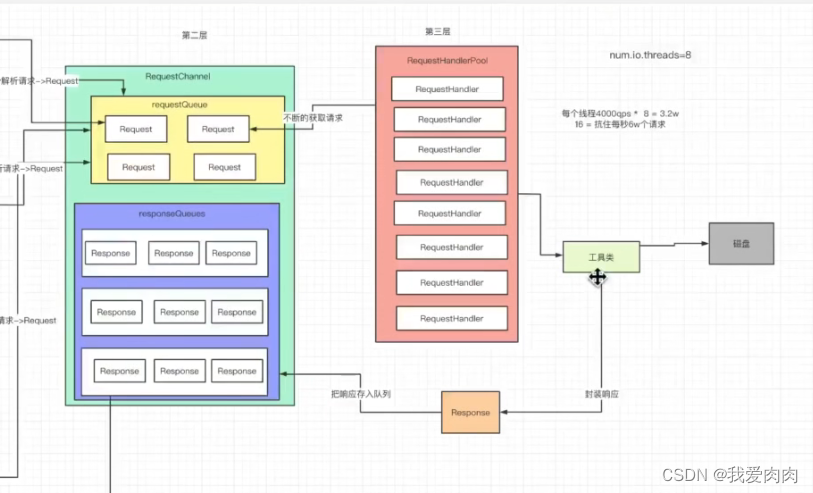
第三层:处理数据
kafka 配置 num.io.threads 默认 8,即默认8个线程处理数据,可以预估每个线程2000qps,即处理1.6w请求每秒文件读取的高性能
1 磁盘顺序写
2 跳表设计
跳表中key为文件名的偏移量,多层索引提高定位文件效率,空间换时间
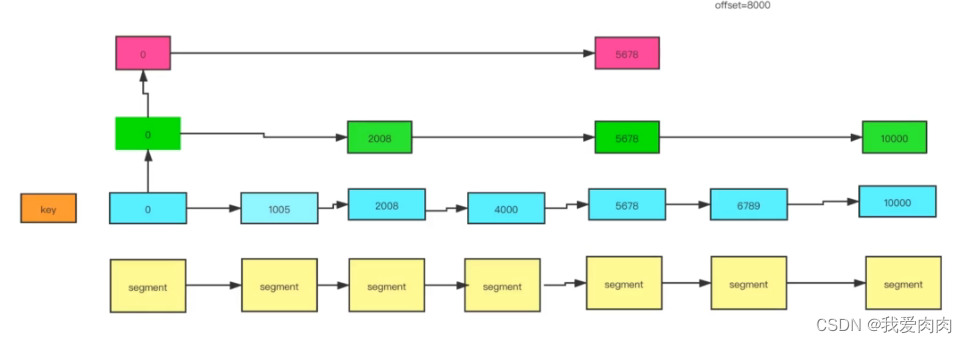
3 定位文件后,通过稀疏索引快速定位文件中的数据
稀疏索引则存在上面图中展示ide xxx.index 中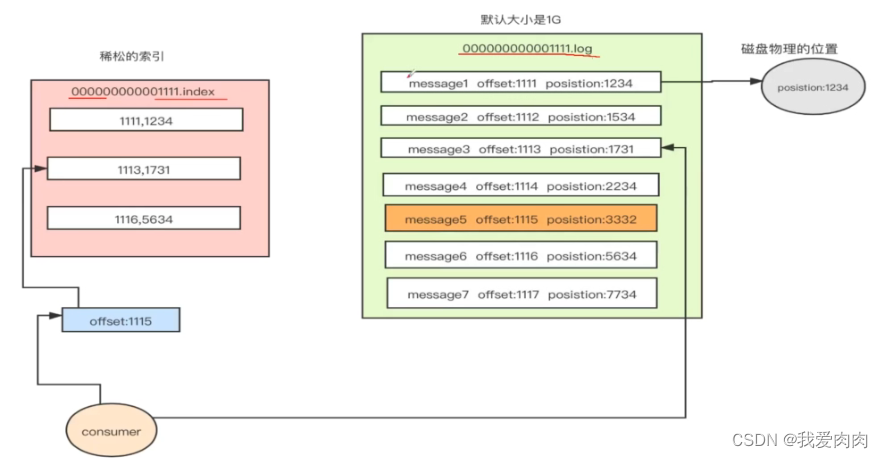
4 零拷贝
堆内内存记录堆外内存的地址。操作数据就不需要再堆内操作可以直接在jvm内存以外的内存操作。此时每次读写操作都节省了两次内存复制操作非零拷贝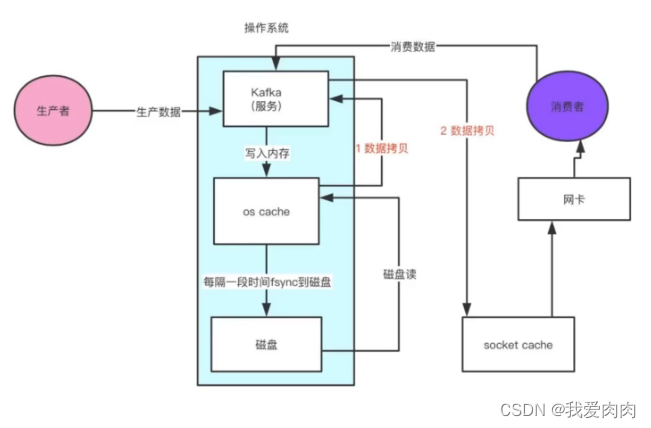
kafka 零拷贝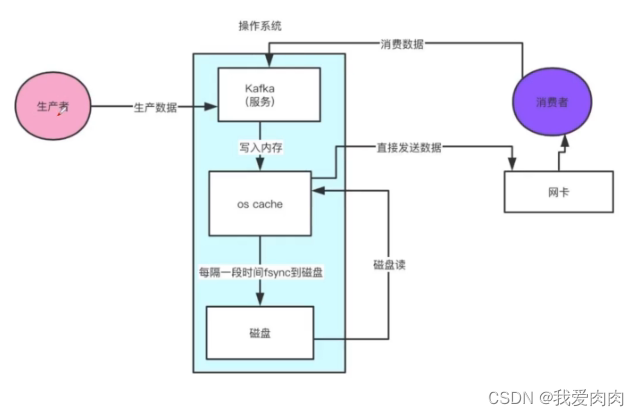
kafka Producer 高性能架构设计
producer 设计-批处理
封装和序列化消息
读取元数据信息然后partitionor计算写入哪个分区
存入缓存中,由Sender线程batch批量发送到broker中
Why batch批量
kafka 0.8版本之前是分区后不批量的直接写入,吞吐量很差
batchcaches缓存中不同分区的多个批数据队列,如果在同一个节点上,kafka会合并这些队列为一个请求发送,提高网络传输性能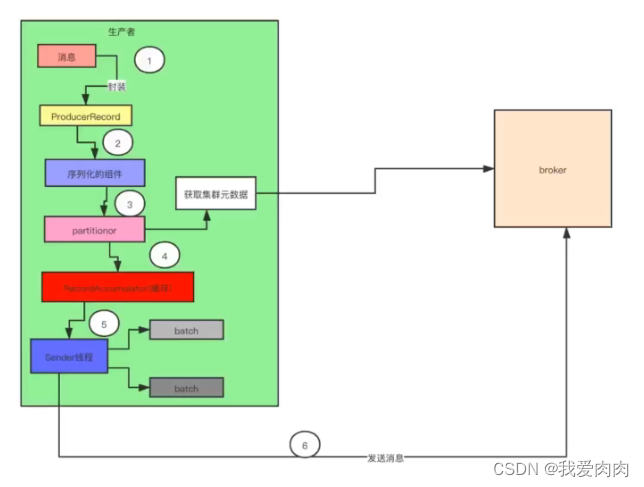
内存池设计-避免内存中批信息频繁full GC
当发送端数据量极大时,ByteBuffer就会无限制地频繁申请,可能会引发OOM
另外,发送完数据后,ByteBuffer就会释放,会频繁的引发FullGC
内存池一共32mb,每个16kb的批信息创建后记录在内存池中,来达到以固定的内存空间来复用内存
当缓冲池满了以后,也就是说消息写入的速度大于向broker发送的速度,那么就阻塞写入,直到缓冲池中有空余内存时为止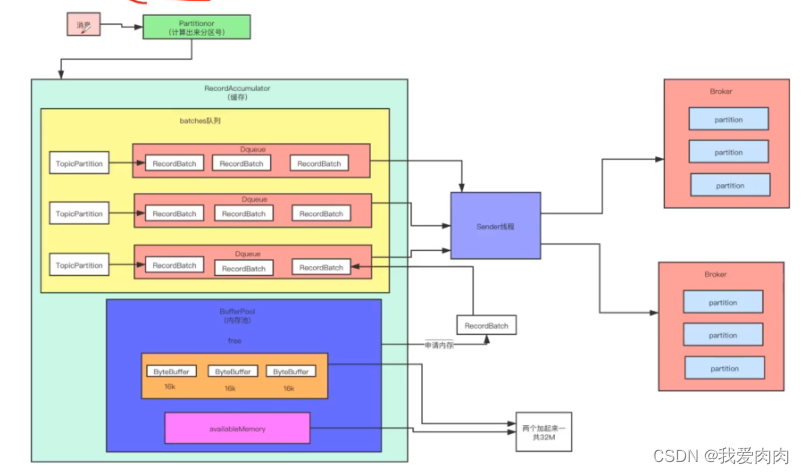
kafka Consumer 高性能架构设计

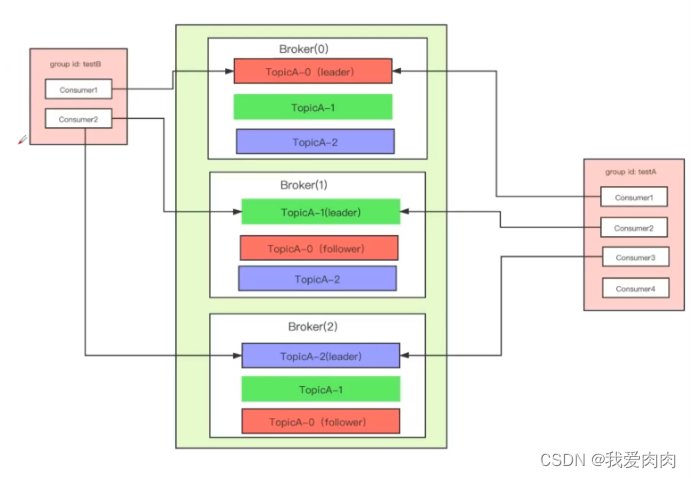
kafka 同时支持p2p和发布订阅
同一个消费者组是p2p模式,同一个消息只能被同一个组的一个消费者消费,一个分区同时只能被一个消费者组消费
不同组是订阅模式,一个消息可以被不同消费者组消费偏移量存储
kafka 0.8版本之前,consumer消费kafka数据后,偏移量存储在zk中。但是zk不适合高频读写,高并发操作
新版本改成偏移量存储在各自broker上