引言
本节学习模型微调(Finetune)的方法,以及认识Transfer Learning(迁移学习)与Model Finetune之间的关系。
一、Transfer Learning & Model Finetune
Transfer Learning(迁移学习):机器学习分支,研究源域(source domain)的知识如何应用到目标域(target domain)。我们将源任务所学习到的知识(权值)应用到目标任务当中,用来提升目标任务中的性能。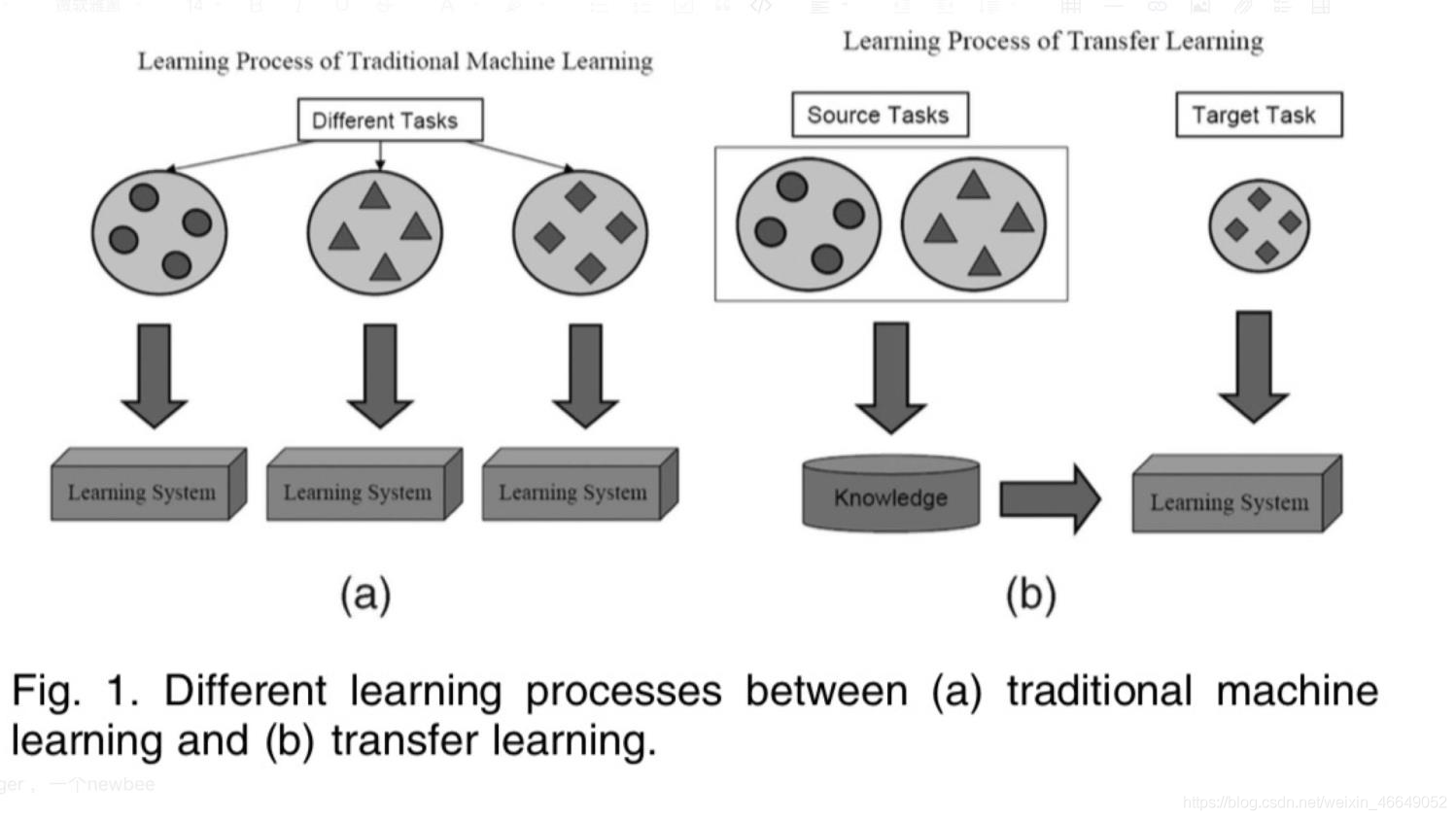
那么,深度学习中的模型微调与迁移学习之间有什么关系?模型微调就是模型的迁移学习。为什么倾向于采用模型微调这个trick呢?这是由于在新任务当中数据量较小不足以训练一个较大的模型,因此,我们采用模型微调这个trick来辅助我们在新任务上训练一个较好的模型,让我们训练过程更快。这就类比于一个人学会了骑电动车,那么,他学自行车就比较快。那么,模型该如何迁移呢?以卷积神经网路为例,我们将特征提取部分认为是非常有共性的地方,我们可以原封不动的进行迁移,分类器的参数认为与具体的任务有关,通常我们需要去改变,分类器中的输出层通常需要进行改变。
模型微调步骤:
- 获取预训练模型参数
- 加载模型(load_state_dict)
- 修改输出层
模型微调训练trick:
固定预训练的参数(requires_grad =False or lr=0)
# 冻结卷积层 flag_m1=0# flag_m1 = 1if flag_m1:for paramin resnet18_ft.parameters(): param.requires_grad=False在非常小的数据量上,我们认为卷积核参数不能在更新了,因为数据量过小,如果继续更新,容易导致过拟合。
将Features Extractor设置较小学习率,在分类器中的学习率比较大(params_group),优化器可以对不同的参数组设置不同的超参数,这里,我们就可以在不同部分设置不同的学习率
# conv 小学习率 flag=0# flag = 1if flag: fc_params_id=list(map(id, resnet18_ft.fc.parameters()))# 返回的是parameters的 内存地址 base_params=filter(lambda p:id(p)notin fc_params_id, resnet18_ft.parameters())# 优化器设置不同的参数组,优化器中的元素是一个list,list中的每一个元素是字典 optimizer= optim.SGD([{'params': base_params,'lr': LR*0.1},# 0{'params': resnet18_ft.fc.parameters(),'lr': LR}], momentum=0.9)
二、PyTorch中模型的Finetune
以自然语言处理中BERT模型为例,这里展示模型的微调,具体见代码
BERT模型—3.BERT模型在ner任务上的微调
BERT模型—4.BERT模型在关系分类任务上的微调
BERT模型—7.BERT模型在句子分类任务上的微调(对抗训练)