
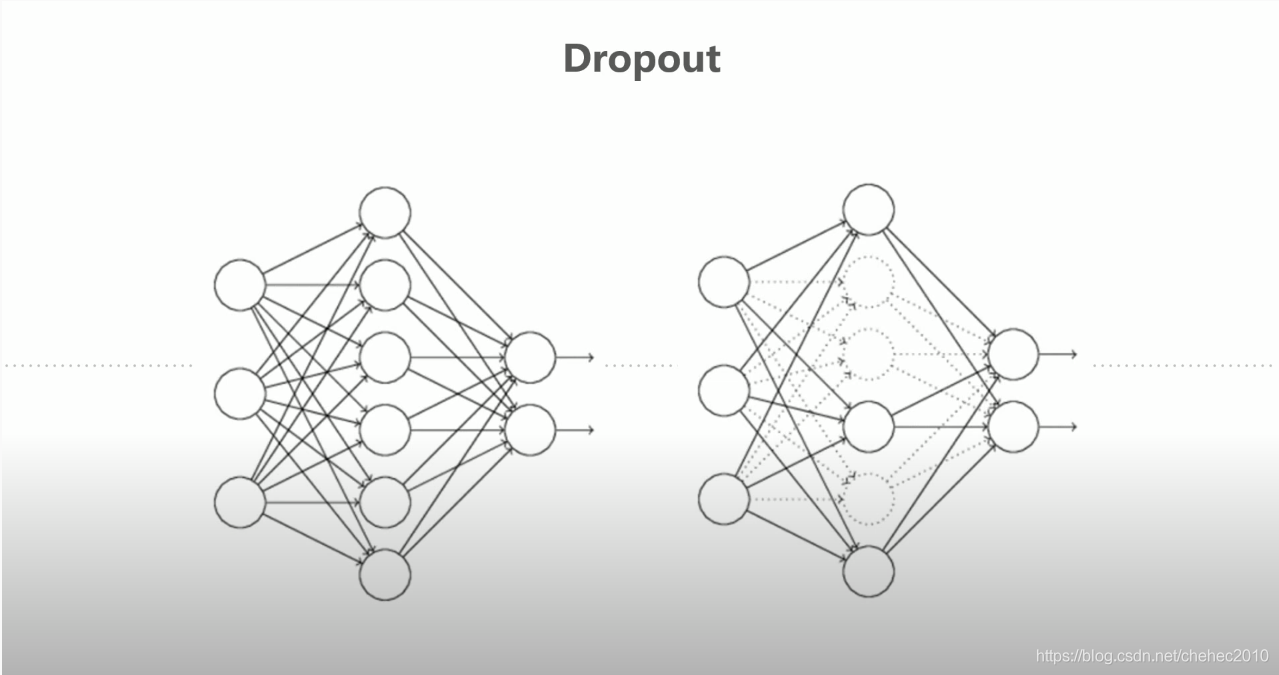

使用Dropout解决过拟合的情况发生
修改代码
import numpy as np
import torch
from torch import nn,optim
from torch.autograd import Variable
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
#训练集
train_dataset=datasets.MNIST(root='./', #存放到项目目录下
train=True, #是训练数据
transform=transforms.ToTensor(), #转换成基本类型tensor数据
download=True) #需要下载
#测试集
test_dataset=datasets.MNIST(root='./',
train=False,
transform=transforms.ToTensor(),
download=True)
#每次训练图片的数量
batch_size=64
#装在训练集数据
train_loader=DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True
)
#加载训练集
test_loader=DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True
)
for i,data in enumerate(train_loader):
inputs,labels=data
print(inputs.shape)
print(labels.shape)
break
#定义网络结构(使用Dropout)
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()#调用父类方法
#Dropout一部分神经元工作一部分不工作
self.layer1=nn.Sequential(nn.Linear(784,500),nn.Dropout(p=0.5),nn.Tanh())#p=0.5表示50%的神经元不工作
self.layer2 = nn.Sequential(nn.Linear(500, 300), nn.Dropout(p=0.5), nn.Tanh())
self.layer3 = nn.Sequential(nn.Linear(300, 10), nn.Softmax(dim=1))
def forward(self,x):
#[64,1,28,28]----(64,784)四维数据编程2维数据
x=x.view(x.size()[0],-1)#-1表示自动匹配
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
return x
LR=0.5
#定义模型
model=Net()
#定义代价函数(均方差)
mse_loss=nn.MSELoss()
#定义优化器
optimizer=optim.SGD(model.parameters(),LR)
def train():
# 表示训练状态, #Dropout一部分神经元工作一部分不工作
model.train()
for i,data in enumerate(train_loader):
#获得一个皮次数据和标签
inputs,labels=data
#获得模型预测结果(64,10)
out=model(inputs)
#to onehot,把数据编码变成独热编码
#(64)编程(64,-1)
labels=labels.reshape(-1,1)
#tensor.scatter(dim,index,src)
#dim对那个维度进行独热编码
#index:要将src中对应的值放到tensor的哪个位置
#src:插入index的数值
one_hot=torch.zeros(inputs.shape[0],10).scatter(1,labels,1)
#计算loss,mse_loss的俩个数据的shape要一致
loss=mse_loss(out,one_hot)
#梯度清零
optimizer.zero_grad()
#计算梯度
loss.backward()
#修改权值
optimizer.step()
#测试
def test():
# 表示模型测试状态,#Dropout所有神经元都要工作
model.eval()
correct=0
for i,data in enumerate(test_loader):
#获取一个批次的数据和标签
inputs,labels=data
#获得模型的预测结果(64,10)
out=model(inputs)
#获取最大值,以及最大值所在的位置
_,predicted=torch.max(out,1)
# 预测正确的数量
correct += (predicted == labels).sum()
print("Test acc:{0}".format(correct.item()/len(test_dataset)))
correct = 0
for i, data in enumerate(train_loader):
# 获取一个批次的数据和标签
inputs, labels = data
# 获得模型的预测结果(64,10)
out = model(inputs)
# 获取最大值,以及最大值所在的位置
_, predicted = torch.max(out, 1)
# 预测正确的数量
correct += (predicted == labels).sum()
print("Train acc:{0}".format(correct.item() / len(train_dataset)))
for epoch in range(10):
print("epoch:",epoch)
train()
test()主要代码:
#定义网络结构(使用Dropout)
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()#调用父类方法
#Dropout一部分神经元工作一部分不工作
self.layer1=nn.Sequential(nn.Linear(784,500),nn.Dropout(p=0.5),nn.Tanh())#p=0.5表示50%的神经元不工作
self.layer2 = nn.Sequential(nn.Linear(500, 300), nn.Dropout(p=0.5), nn.Tanh())
self.layer3 = nn.Sequential(nn.Linear(300, 10), nn.Softmax(dim=1))
def forward(self,x):
#[64,1,28,28]----(64,784)四维数据编程2维数据
x=x.view(x.size()[0],-1)#-1表示自动匹配
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
return x测试结果对比:
F:\开发工具\pythonProject\tools\venv\Scripts\python.exe F:/开发工具/pythonProject/tools/pytools/pytools032.py
torch.Size([64, 1, 28, 28])
torch.Size([64])
epoch: 0
Test acc:0.8875
Train acc:0.8811
epoch: 1
Test acc:0.9111
Train acc:0.9065833333333333
epoch: 2
Test acc:0.9178
Train acc:0.91535
epoch: 3
Test acc:0.9234
Train acc:0.92
epoch: 4
Test acc:0.9259
Train acc:0.9243166666666667
epoch: 5
Test acc:0.9285
Train acc:0.9270833333333334
epoch: 6
Test acc:0.9296
Train acc:0.9291
epoch: 7
Test acc:0.9331
Train acc:0.9323
epoch: 8
Test acc:0.9357
Train acc:0.9348
epoch: 9
Test acc:0.9366
Train acc:0.93645
Process finished with exit code 0另外一种正则化解决过拟合方案:建议网络结构复杂的情况下使用
LR=0.5
#定义模型
model=Net()
#定义代价函数(均方差)
mse_loss=nn.MSELoss()
#定义优化器,weight_decay设置L2正则化
optimizer=optim.SGD(model.parameters(),LR,weight_decay=0.001)测试结果:
F:\开发工具\pythonProject\tools\venv\Scripts\python.exe F:/开发工具/pythonProject/tools/pytools/pytools033.py
torch.Size([64, 1, 28, 28])
torch.Size([64])
epoch: 0
Test acc:0.883
Train acc:0.8743166666666666
epoch: 1
Test acc:0.8962
Train acc:0.8936833333333334
epoch: 2
Test acc:0.9044
Train acc:0.9002833333333333
epoch: 3
Test acc:0.9043
Train acc:0.90135
epoch: 4
Test acc:0.9051
Train acc:0.9009
epoch: 5
Test acc:0.9035
Train acc:0.9002166666666667
epoch: 6
Test acc:0.9067
Train acc:0.9016833333333333
epoch: 7
Test acc:0.9052
Train acc:0.9004166666666666
epoch: 8
Test acc:0.9036
Train acc:0.9023333333333333
epoch: 9pytorch的优化器介绍:优化器原理都是随机梯度下降法
Adadelta、Adagrad、Adam、Adamx、AdamW、ASGD、LBFGS、RMSprop、Rprop、SGD、SparseAdam
总结:
Dropout和正则化看情况适用,建议网络复杂的情况下使用,用了不一定效果就好。