[pytorch] 训练加速技巧 代码示例
- 技巧一:num_workers 和 pin_memory
- 技巧二:torch.backends.cudnn.benchmark = True
- 技巧三:增加batch_size
- 技巧四:梯度累加(Gradient Accumulation)
- 技巧五:卷积层后面跟batch normalization层时不要偏置b
- 技巧六:使用parameter.grad = None 代替 model.zero_grad()
- 技巧七:使用lr_scheduler.CyclicLR
- 技巧八:混合精度训练(Automatic Mixed Precision)
- 技巧九 : 减少GPU和CPU之间的数据传递
- 技巧十:使用 .as_tensor() 代替 .tensor()
- 技巧十一:validation时关闭梯度计算
- 技巧十二:使用梯度剪裁(gradient clipping)
- 技巧十三: 使用DistributedDataParallel
- 技巧十四: 仅在实际需要时打开调试工具
- 综合使用
我一直在做3d医学图像的处理,对3d图像的学习非常费时,所以我尝试寻找一些加速训练的方法,网上的方法都没好的代码示例。
首先,我的基础代码来自[pytorch] Resnet3D预训练网络 + MedMNIST 3D医学数据分类 , 我会在这篇比较基础的代码上应用这些加速技巧。
putorch训练加速技巧:
- PYTORCHPERFORMANCE TUNING GUIDE
- Here are 17 ways of making PyTorch training faster – what did I miss?
技巧一:num_workers 和 pin_memory
When using torch.utils.data.DataLoader, set num_workers > 0, rather than the default value of 0, and pin_memory=True, rather than the default value of False.
注意num_workers并不是越大越好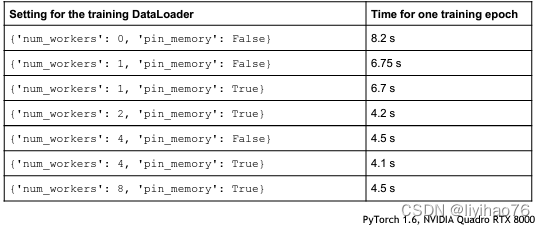
train_loader= data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,num_workers=8, pin_memory=True)
val_loader= data.DataLoader(dataset=val_dataset,
batch_size=batch_size,
shuffle=False,num_workers=8, pin_memory=True)
test_loader= data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False,num_workers=8, pin_memory=True)技巧二:torch.backends.cudnn.benchmark = True
设置 torch.backends.cudnn.benchmark=True 将会让程序在开始时花费一点额外时间,为整个网络的每个卷积层搜索最适合它的卷积实现算法,进而实现网络的加速。适用场景是网络结构固定(不是动态变化的),网络的输入形状(包括 batch size,图片大小,输入的通道)是不变的,其实也就是一般情况下都比较适用。反之,如果卷积层的设置一直变化,将会导致程序不停地做优化,反而会耗费更多的时间。
更多信息:torch.backends.cudnn.benchmark ?!
直接加载开头就行,比如说import库之后。
torch.backends.cudnn.benchmark=True技巧三:增加batch_size
这一点没什么说的,人人都想要大的batch_size,但是往往机能所限,即使我用了相当先进的RTX A6000,高达52GB的显存有时仍然不够用,所以没什么办法。同时,在调整batch_size时不要忘了调整学习率,学习率衰减等参数。
注意一点,如果你使用的batch_size相当大,最好选用一些专门为大batch_size设计的optimizer,详情请看文前第一个链接
技巧四:梯度累加(Gradient Accumulation)
严格来说,这个不算加速训练的方法,但是,在我们batch_size比较小的时候,这是一种提高我们训练表现的方法。
受显存限制,运行一些预训练的large模型时,batch-size往往设置的比较小1-4,否则就会‘CUDA out of memory’,但一般batch-size越大(一定范围内)模型收敛越稳定效果相对越好,这时梯度累加(Gradient Accumulation)就可以发挥作用了,梯度累加可以先累加多个batch的梯度再进行一次参数更新,相当于增大了batch-size。
我们以Pytorch为例,一个神经网络的训练过程通常如下:
for i,(inputs, labels)inenumerate(trainloader):
optimizer.zero_grad()# 梯度清零
outputs= net(inputs)# 正向传播
loss= criterion(outputs, labels)# 计算损失
loss.backward()# 反向传播,计算梯度
optimizer.step()# 更新参数if(i+1)% evaluation_steps==0:
evaluate_model()从代码中可以很清楚地看到神经网络是如何做到训练的:
1.将前一个batch计算之后的网络梯度清零
2.正向传播,将数据传入网络,得到预测结果
3.根据预测结果与label,计算损失值
4.利用损失进行反向传播,计算参数梯度
5.利用计算的参数梯度更新网络参数
下面来看梯度累加是如何做的:
for i,(inputs, labels)inenumerate(trainloader):
outputs= net(inputs)# 正向传播
loss= criterion(outputs, labels)# 计算损失函数
loss= loss/ accumulation_steps# 损失标准化
loss.backward()# 反向传播,计算梯度if(i+1)% accumulation_steps==0:
optimizer.step()# 更新参数
optimizer.zero_grad()# 梯度清零if(i+1)% evaluation_steps==0:
evaluate_model()1.正向传播,将数据传入网络,得到预测结果
2.根据预测结果与label,计算损失值
3.利用损失进行反向传播,计算参数梯度
4.重复1-3,不清空梯度,而是将梯度累加
5.梯度累加达到固定次数之后,更新参数,然后将梯度清零
总结来讲,梯度累加就是每计算一个batch的梯度,不进行清零,而是做梯度的累加,当累加到一定的次数之后,再更新网络参数,然后将梯度清零。
通过这种参数延迟更新的手段,可以实现与采用大batch size相近的效果。在平时的实验过程中,我一般会采用梯度累加技术,大多数情况下,采用梯度累加训练的模型效果,要比采用小batch size训练的模型效果要好很多。
参考:Gradient Accumulation in PyTorch
技巧五:卷积层后面跟batch normalization层时不要偏置b
在跟了batchnorm层的卷积层设置偏置是多此一举
技巧六:使用parameter.grad = None 代替 model.zero_grad()
model.zero_grad()
optimizer.zero_grad()首先,这两种方式都是把模型中参数的梯度设为0。当optimizer = optim.Optimizer(net.parameters())时,二者等效。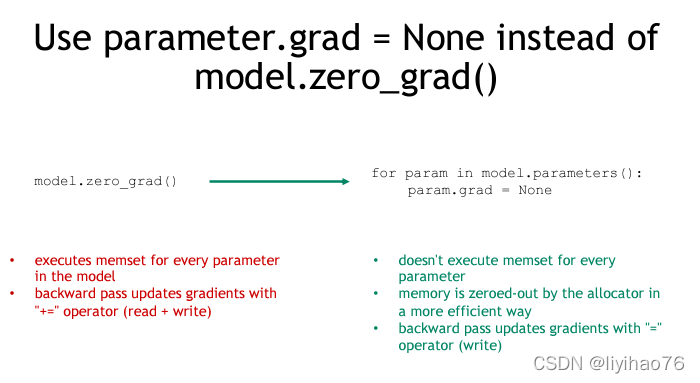
for paramin model.parameters():
param.grad=None技巧七:使用lr_scheduler.CyclicLR
CyclicLR循环学习率出自于论文《Cyclical Learning Rates for Training Neural Networks》;与之前的固定或者单调递减的学习率不同,这是周期性变化。有三个参数:上边界max_lr,下边界base_lr,补长stepsize。如下所示,学习率在base_lr和max_lr震荡更新。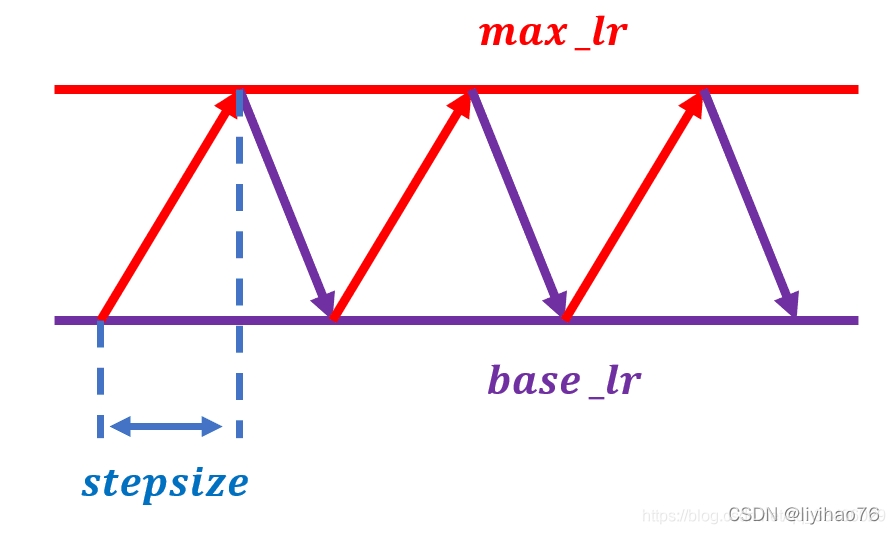
参数介绍
base_lr:基础学习率
max_lr:学习率上限
step_size_up:学习率上升的步数
step_size_down:学习率下降的步数
mode:共三种模式分别为triangular,triangular2和exp_range
gamma:exp_range中的常量gamma**(cycle iterations)
scale_fn:自定义缩放策略保证所有 x ≥ 0 x\geq 0 x≥0的情况下 s c a l e _ f n ( x ) scale_fn(x) scale_fn(x)的值域为 [ 0 , 1 ] [0,1] [0,1]
scale_mode:两种模式cycle和iterations
cycle_momentum:如果为True,则动量与’base_momentum’和’max_momentum之间的学习率成反比
base_momentum:初始动量,即每个参数组的循环中的下边界。
max_momentum:每个参数组的循环中的上动量边界。
当优化器是adam时i, cycle_momentum=True改为 cycle_momentum=False
#设置优化器
optimizer= torch.optim.SGD(model.parameters(),lr=opt.lr,momentum=0.9)
base_lr=2e-3
max_lr=6e-3#设置学习率调节方法
scheduler= torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=500, step_size_down=500, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)for epochinrange(opt.num_epochs):
train(...)
validate(...)
scheduler.step()参考:PyTorch torch.optim.lr_scheduler.CyclicLR
model= torch.nn.Linear(2,1)
optimizer= torch.optim.Adam(model.parameters(), lr=1e-5)#scheduler = ExponentialLR(optimizer, gamma=0.99)
base_lr=1e-4
max_lr=1e-3
scheduler= torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=50, step_size_down=50, mode='triangular2', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=False, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)
lrs=[]for iinrange(800):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
技巧八:混合精度训练(Automatic Mixed Precision)
所谓的混合精度训练,即当你使用N卡训练你的网络时,混合精度会在内存中用FP16做储存和乘法从而加速计算,用FP32做累加避免舍入误差。它的优势就是可以使你的训练时间减少一半左右。它的缺陷是只能在支持FP16操作的一些特定类型的显卡上面使用,而且会存在溢出误差和舍入误差。
注意:小batch场景下混合精度并不能带来速度提升,甚至会更慢。因为小batch下的计算已经很快了,速度瓶颈在IO(在GPU和GPU间传送数据)。而混合精度需要进行FP16与FP32的转换,会消耗更多时间。
# Creates model and optimizer in default precision
model= Net().cuda()
optimizer= optim.SGD(model.parameters(),...)# Creates a GradScaler once at the beginning of training.
scaler= GradScaler()for epochin epochs:forinput, targetin data:
optimizer.zero_grad()# Runs the forward pass with autocasting.with autocast():
output= model(input)
loss= loss_fn(output, target)# Scales loss. Calls backward() on scaled loss to create scaled gradients.# Backward passes under autocast are not recommended.# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()# scaler.step() first unscales the gradients of the optimizer's assigned params.# If these gradients do not contain infs or NaNs, optimizer.step() is then called,# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)# Updates the scale for next iteration.
scaler.update()技巧九 : 减少GPU和CPU之间的数据传递
频繁的使用GPU 和 CPU之间的数据传递会占用大量的时间,这些操作包括 tensor.cpu() , tensor.cuda() , .item() , .numpy().
使用 .detach() 会好一些.
技巧十:使用 .as_tensor() 代替 .tensor()
torch.tensor()总是复制数据。如果您有要转换的 numpy 数组,请使用torch.as_tensor()或torch.from_numpy()避免复制数据。
技巧十一:validation时关闭梯度计算
使用torch.no_grad()
for epochinrange(num_epochs):
model.train()with torch.enable_grad():for x,labelin tqdm(train_loader):....
model.eval()with torch.no_grad():for x,labelin tqdm(val_loader):.....技巧十二:使用梯度剪裁(gradient clipping)
最初用于避免 RNN 中的梯度爆炸,有一些经验证据和理论支持表明剪裁梯度可以加速训练。
梯度裁剪原理:既然在BP过程中会产生梯度消失(就是偏导无限接近0,导致长时记忆无法更新)或梯度爆炸,那么最简单粗暴的方法就是,梯度截断Clip, 将梯度约束在某一个区间之内.
import torch.nnas nn
outputs= model(data)
loss= loss_fn(outputs, target)
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=20, norm_type=2)
optimizer.step()nn.utils.clip_grad_norm_ 的参数:
parameters:希望实施梯度裁剪的可迭代网络参数
max_norm:该组网络参数梯度的范数上限
norm_type:范数类型(一般默认为L2 范数, 即范数类型=2)
torch.nn.utils.clipgrad_norm() 的使用应该在loss.backward() 之后,optimizer.step()之前.
注意这个方法只在训练的时候使用,在测试的时候验证和测试的时候不用。
技巧十三: 使用DistributedDataParallel
使用 DistributedDataParallel 而不是 DataParallel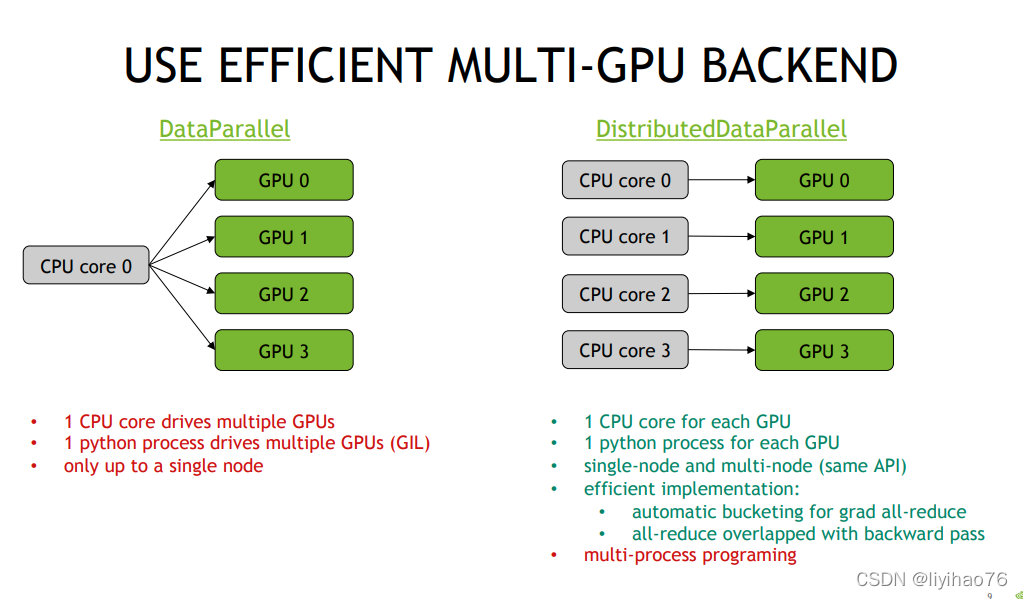
DP 只用于单机多卡,DDP 可以用于单机多卡也可用于多机多卡,后者现在也是Pytorch训练的主流用法,DP写法比较简单,但即使在单机多卡情况下也比 DDP 慢。DDP的用法比较复杂,我会再写一篇讲一讲怎么用。
技巧十四: 仅在实际需要时打开调试工具
PyTorch 提供了许多有用的调试工具,例如autograd.profiler、autograd.grad_check和autograd.anomaly_detection。确保在需要时使用它们,因为它们会减慢您的训练速度。如果不需要,请关闭调试 API。
综合使用
我们将上述的方法应用到我们的分类代码中。
from tqdmimport tqdmimport numpyas npimport torchimport torch.nnas nnimport torch.optimas optimimport torch.utils.dataas dataimport torchvision.transformsas transformsimport medmnistfrom medmnistimport INFO, Evaluatorimport osimport timeimport torch.nnas nnimport torchimport torchvision.transformsas transformsfrom PILimport Imagefrom matplotlibimport pyplotas pltimport torchvision.modelsas modelsimport torchsummaryimport timefrom torch.optim.lr_schedulerimport ExponentialLRfrom sklearn.metricsimport roc_curvefrom sklearn.metricsimport aucfrom sklearn.metricsimport accuracy_scoretorch.backends.cudnn.benchmark=Truefrom torch.utils.tensorboardimport SummaryWriter
summaryWriter= SummaryWriter("./BCE_opts/")batch_size=64data_flag='vesselmnist3d'# Binary-Class (2)
download=True
info= INFO[data_flag]
DataClass=getattr(medmnist, info['python_class'])# load the data
train_dataset= DataClass(split='train', download=download)
val_dataset= DataClass(split='val', download=download)
test_dataset= DataClass(split='test', download=download)x, y= train_dataset[0]print(x.shape, y,y[0])#(1, 28, 28, 28) [1] 1train_loader= data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,num_workers=8, pin_memory=True)
val_loader= data.DataLoader(dataset=val_dataset,
batch_size=batch_size,
shuffle=False,num_workers=8, pin_memory=True)
test_loader= data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False,num_workers=8, pin_memory=True)for x, yin train_loader:print(x.shape, y.shape)#torch.Size([64, 1, 28, 28, 28]) torch.Size([64, 1])breakdevice= torch.device('cuda:0'if torch.cuda.is_available()else'cpu')print('device =',device)print(torch.cuda.get_device_name(0))from modelsimport resnetdefgenerate_model(model_type='resnet', model_depth=50,
input_W=224, input_H=224, input_D=224, resnet_shortcut='B',
no_cuda=False, gpu_id=[0],
pretrain_path='pretrain/resnet_50.pth',
nb_class=1):assert model_typein['resnet']if model_type=='resnet':assert model_depthin[10,18,34,50,101,152,200]if model_depth==10:
model= resnet.resnet10(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input=256elif model_depth==18:
model= resnet.resnet18(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input=512elif model_depth==34:
model= resnet.resnet34(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input=512elif model_depth==50:
model= resnet.resnet50(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input=2048elif model_depth==101:
model= resnet.resnet101(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input=2048elif model_depth==152:
model= resnet.resnet152(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input=2048elif model_depth==200:
model= resnet.resnet200(
sample_input_W=input_W,
sample_input_H=input_H,
sample_input_D=input_D,
shortcut_type=resnet_shortcut,
no_cuda=no_cuda,
num_seg_classes=1)
fc_input=2048
model.conv_seg= nn.Sequential(nn.AdaptiveAvgPool3d((1,1,1)), nn.Flatten(),
nn.Linear(in_features=fc_input, out_features=nb_class, bias=True))ifnot no_cuda:iflen(gpu_id)>1:
model= model.cuda()
model= nn.DataParallel(model, device_ids=gpu_id)
net_dict= model.state_dict()else:import os
os.environ["CUDA_VISIBLE_DEVICES"]=str(gpu_id[0])
model= model.cuda()
model= nn.DataParallel(model, device_ids=None)
net_dict= model.state_dict()else:
net_dict= model.state_dict()print('loading pretrained model {}'.format(pretrain_path))
pretrain= torch.load(pretrain_path)
pretrain_dict={k: vfor k, vin pretrain['state_dict'].items()if kin net_dict.keys()}# k 是每一层的名称,v是权重数值
net_dict.update(pretrain_dict)#字典 dict2 的键/值对更新到 dict 里。
model.load_state_dict(net_dict)#model.load_state_dict()函数把加载的权重复制到模型的权重中去print("-------- pre-train model load successfully --------")return modelmodel= generate_model(model_type='resnet', model_depth=50,
input_W=28, input_H=28, input_D=28, resnet_shortcut='B',
no_cuda=False, gpu_id=[0],
pretrain_path='./resnet_50_23dataset.pth',
nb_class=1)optimizer= torch.optim.Adam(model.parameters(), lr=1e-4)
criterion= torch.nn.BCEWithLogitsLoss(pos_weight=torch.tensor([10.0])