目录
mmdetection版本:2.0
mmcv版本:0.5.5
mmdetection和mmcv的关系是,mmdetection一些功能代码是直接通过调用mmcv的api实现的。
============================================================================
mmdetection的main()函数就在 tool/train.py里,在代码详解(一) 中说过,看train.py的代码,看不懂的地方最先遇到的是 build_xxx(),build_xxx()已经在代码详解(一) 中讲过了,然后现在就说第二个比较难懂的地方,就是训练的过程。
mmdetection的训练过程,只用调用一个接口,就是 train_detector(),这个接口被定义在mmdetection项目代码的 mmdet/apis/train.py里,注意这里的train.py和 tool/train.py是不同的,前者主要是 提供接口,后者是训练的顺序代码。
train_detector():
train_detector()主要接受三个参数,分别是model,cfg,dataset:
model:通过build_detector()实例化出来的某个目标检测网络类的对象。
cfg:cfg是来自配置文件的配置信息,这些配置文件一般都在mmdetection项目里的 config/_base_/
cfg是由4个配置文件组成的,以maskrcnn网络来训练COCO数据集为例,如下图,下图中只有第一个配置文件会随着选择的网络改变而改变,第二个随着你选择的数据集而改变,其余两个是不会变的。

上图中第一个配置文件:包含了Maskrcnn的配置信息以及训练、测试这个网络的训练、测试信息。
上图中第二个配置文件:包含了训练阶段和测试阶段如何处理COCO数据集的信息,如归一化参数,Resize的尺寸。当然还有指定COCO数据集的路径,也是在这个配置文件中指定的。还有batchsize也是在这里指定,只不过名字变成了samples_per_gpu。
上图中第三个配置文件:包含了训练模式的优化器、学习率、epoch的信息,当然是可以在这个配置文件里修改这些参数的。
上图中第四个配置文件:包含了训练过程中保存模型的间隔,日记记录的配置信息。
dataset:dataset通过build_dataset()实例化出来的数据集类的对象。
过程:
解析完train_detector()的参数之后,就可以看看train_detector()的过程了。
主要流程如下,后面会逐一讲解:
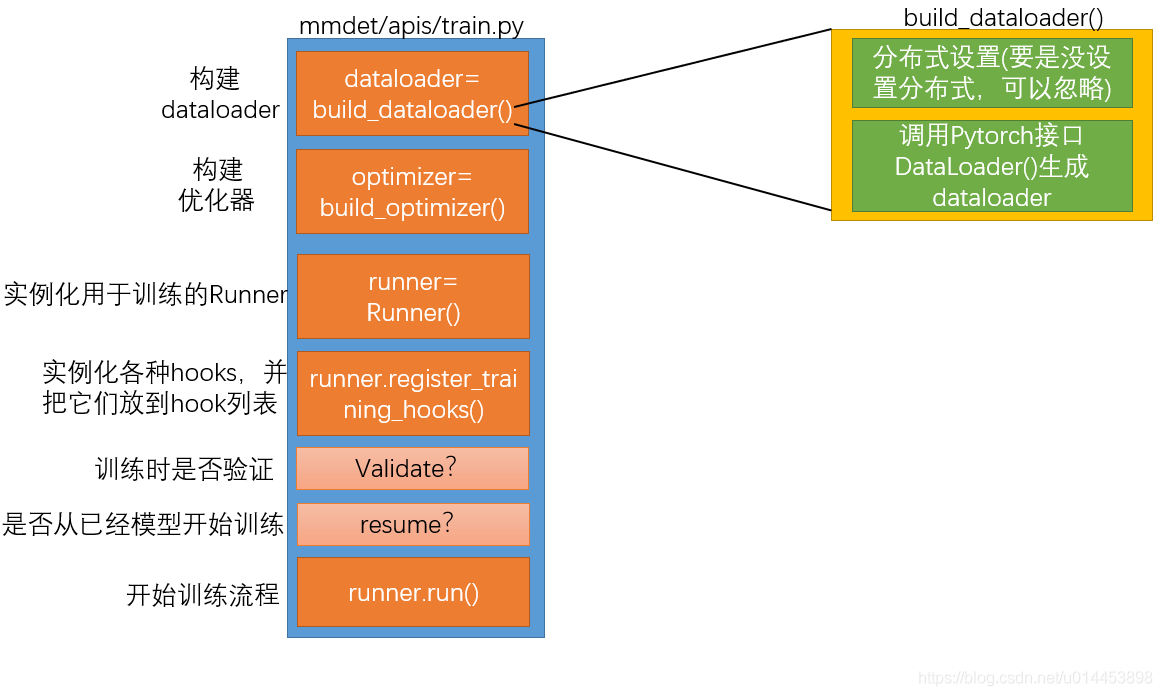
以上是train_detector()的大致代码流程,其中最重要的是 最后的 runner.run(),因为它控制的就是训练的流程。
为了更好地了解,下面会着重讲一下最重要的 Runner类 和 HOOK的使用。
Runner类:
Runner类位于mmcv.runner里,同样是不属于mmdetection的项目代码,但是要运行mmdetection就需要用到mmcv的包。Runner类主要包含 保存模型的过程、train训练的过程、val验证的过程、各种HOOK的管理过程(HOOK下面会详细介绍)。有人可能会疑惑了,为什么那么多train?有 tool/train.py、mmdet/api/train.py ,现在又有一个train(),关系是这样的:
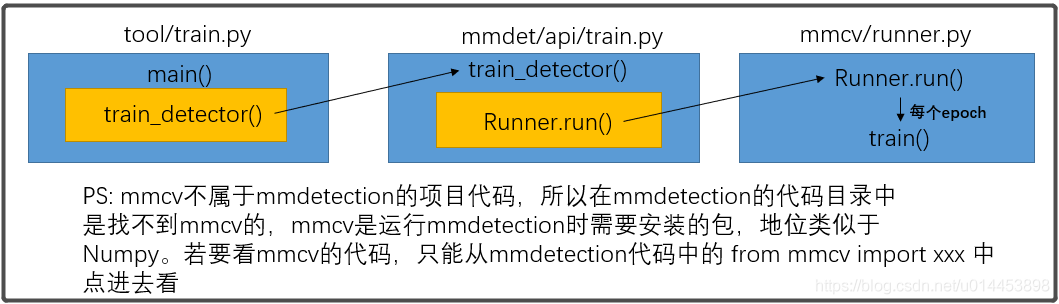
从上图可以看到,训练的接口调来调去,其实最终是在 mmcv/runner.py 的train.py方法里实现较为底层的训练代码,在这个train()中是已经到了从data_loader里取出数据进行训练的地步了。但如果你觉得到这里就没什么tricks(骚操作)你就错了,尽管是简单的训练代码,都分了几块,如下图:
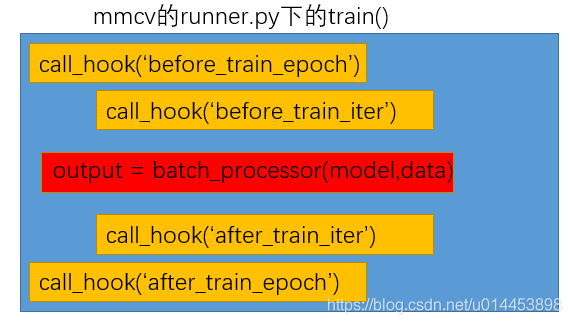
从上图可以看到:
模型的输出结果其实是经过 batch_processor()得到的。在模型进行输出之前,会经过几个HOOK,call_hook()就是调用HOOK的函数,call_hook中 有字符,表示,具体的操作,例如 call_hook('before_train_epoch') 就表示在训练一个 epoch前需要进行的操作。然后下面就讲讲HOOK。
HOOK类:
我们先来看看HOOK这个类是怎么定义的:
位置:mmcv/runner/hooks/hook.py
HOOKS = Registry('hook')
class Hook(object):
def before_run(self, runner):
pass
def after_run(self, runner):
pass
def before_epoch(self, runner):
pass
def after_epoch(self, runner):
pass
def before_iter(self, runner):
pass
def after_iter(self, runner):
pass
def before_train_epoch(self, runner):
self.before_epoch(runner)
def before_val_epoch(self, runner):
self.before_epoch(runner)
def after_train_epoch(self, runner):
self.after_epoch(runner)
def after_val_epoch(self, runner):
self.after_epoch(runner)
def before_train_iter(self, runner):
self.before_iter(runner)
def before_val_iter(self, runner):
self.before_iter(runner)
def after_train_iter(self, runner):
self.after_iter(runner)
def after_val_iter(self, runner):
self.after_iter(runner)
def every_n_epochs(self, runner, n):
return (runner.epoch + 1) % n == 0 if n > 0 else False
def every_n_inner_iters(self, runner, n):
return (runner.inner_iter + 1) % n == 0 if n > 0 else False
def every_n_iters(self, runner, n):
return (runner.iter + 1) % n == 0 if n > 0 else False
def end_of_epoch(self, runner):
return runner.inner_iter + 1 == len(runner.data_loader)可视化结果如下图:

很多方法的名字都挺有意思,例如 “before_epoch”就表示这个方法会在训练每个epoch之前执行。
同样也可以看到这个类里面定义了很多空的方法(都是pass),这个是给我们重载 用的,就是说继承HOOK类的类,可以拥有这些方法,这就衍生了xxxHOOK的类了。其次我们看到了HOOKS,这是什么?就是在上一篇(一)的注册表全局变量,这是HOOK的注册表全局变量,这就暗示了注册表里肯定有很多不同的 HOOKS类。
那我们能不能看一下,一共有多少种HOOKS被定义呢?在mmcv/runner/hooks/__init__.py下,有定义:
__all__ = [
'HOOKS', 'Hook', 'CheckpointHook', 'ClosureHook', 'LrUpdaterHook',
'OptimizerHook', 'IterTimerHook', 'DistSamplerSeedHook', 'EmptyCacheHook',
'LoggerHook', 'MlflowLoggerHook', 'PaviLoggerHook', 'TextLoggerHook',
'TensorboardLoggerHook', 'WandbLoggerHook', 'MomentumUpdaterHook'
]可以从HOOK的名字看出来,每个HOOK都对应着一些特定的功能。
我们先看看调用HOOK的函数 call_hook()是怎么定义的:
(这位于mmcv/runner/runner.py,不属于mmdetection项目代码,属于mmcv)
def call_hook(self, fn_name):
for hook in self._hooks:
getattr(hook, fn_name)(self)可以看到,call_hook()先遍历hooks的列表中的每个不同类型的hook,由于每个hook都是从HOOK 类实例化出来的,所以都有
before_run(),after_run(),before_epoch(),after_epoch()....等方法。我们主要看看 call_hook调用的是什么HOOK,通过调试可以看到 self._hooks里的变量值(即hook),里面有:
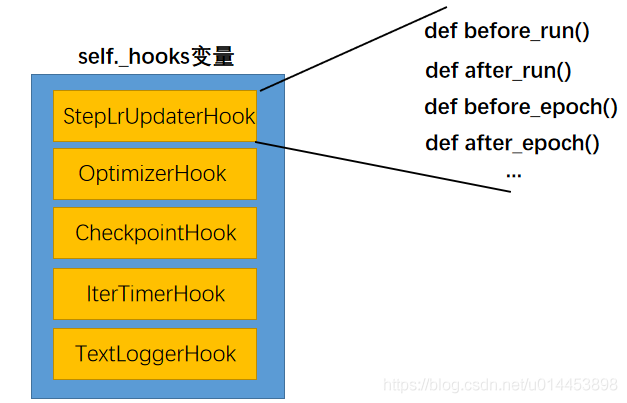
self.hooks 里hook的功能分别是:
1. 调整学习率
2. 调整优化器(如参数的回传)
3. 保存模型
4. 迭代时间
5. 日志记录。
可以看到每个hook都有一堆“before xxx”,“after xxx”的方法。所以在某个阶段时(例如训练每个epoch前),代码会调用call_hook()来遍历self.hooks 里的hook,每个hook都会被调用一次,然后每个hook里面的before_epoch()方法也会被调用。其他阶段也类似。
我们来看一个例子:
我们知道,pytorch训练网络,loss回传肯定有backward(),参数更新肯定有 step(),按照常理,loss是在每个batch训练后得到的,所以参数更新也是在每个batch训练后进行的,所以猜测,loss回传的backward()和参数更新的step()都应该在OptimizerHook的 after_train_iter()方法中,那我们看看OptimizerHook的代码,(OptimizerHook属于mmcv,所以要到mmcv的库上看)
(mmcv代码地址:https://github.com/open-mmlab/mmcv/tree/master/mmcv)
![]()
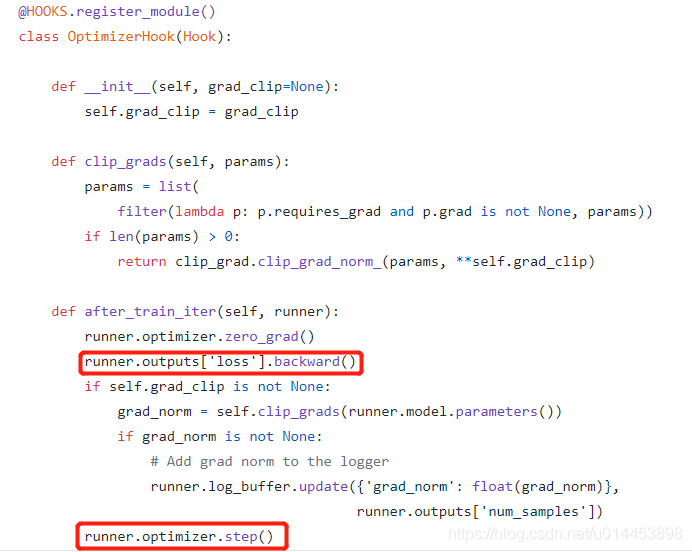
可以看到,确实能在OptimizerHook的 after_train_iter()方法中找到backward()和step()。
batch_processor:
我们看完HOOK之后,就回到Runner的主要训练过程train()上,回到这张图上:
我们从上图可以知道,每训练一个batch(即一次迭代iter),都会调用一次batch_processor,并且从batch_processor的输入参数可以看出,这个函数是把一个batch的数据放入模型训练的代码。按照这个想法,我们去看看batch_processor的代码:
batch_processor不属于mmcv,所以是可以在mmdetection项目代码中找到的,它位于:mmdet/apis/train ,一共就4行代码,最主要的就是:
losses = model(**data)所以batch_processor 的作用就是把一个batch的数据放入模型,然后返回损失值loss。
到此,mmdetection的训练过程就介绍完毕了。