(深度学习)Pytorch学习笔记之dropout训练
Dropout训练实现快速通道:点我直接看代码实现
Dropout训练简介
在深度学习中,dropout训练时我们常常会用到的一个方法——通过使用它,我们可以可以避免过拟合,并增强模型的泛化能力。
通过下图可以看出,dropout训练训练阶段所有模型共享参数,测试阶段直接组装成一个整体的大网络: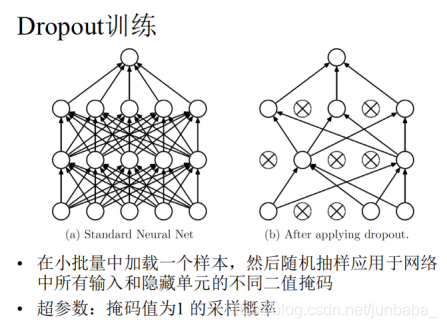
那么,我们在深度学习的有力工具——Pytorch中如何实现dropout训练呢?
易错大坑
网上查找到的很多实现都是这种形式的:
out= F.dropout(out, p=0.5)这种形式的代码非常容易误导初学者,给人带来很大的困扰:
- 首先,这里的F.dropout实际上是torch.nn.functional.dropout的简写(很多文章都没说清这一点,就直接给个代码),我尝试了一下我的Pytorch貌似无法使用,可能是因为版本的原因。
- 其次,torch.nn.functional.dropout()还有个大坑:F.dropout()相当于引用的一个外部函数,模型整体的training状态变化也不会引起F.dropout这个函数的training状态发生变化。因此,上面的代码实质上就相当于
out = out
因此,如果你非要使用torch.nn.functional.dropout的话,推荐的正确方法如下(这里默认你已经import torch.nn as nn了):
out= nn.functional.dropout(out, p=0.5, training=self.training)推荐代码实现方法
这里更推荐的方法是:nn.Dropout(p),其中p是采样概率。nn.Dropout实际上是对torch.nn.functional.dropout的一个包装, 也将self.training传入了其中,可以有效避免前面所说的大坑。
下面给出一个三层神经网络的例子:
import torch.nnas nn
input_size=28*28
hidden_size=500
num_classes=10# 三层神经网络classNeuralNet(nn.Module):def__init__(self, input_size, hidden_size, num_classes):super(NeuralNet, self).__init__()
self.fc1= nn.Linear(input_size, hidden_size)# 输入层到影藏层
self.relu= nn.ReLU()
self.fc2= nn.Linear(hidden_size, num_classes)# 影藏层到输出层
self.dropout= nn.Dropout(p=0.5)# dropout训练defforward(self, x):
out= self.fc1(x)
out= self.dropout(out)
out= self.relu(out)
out= self.fc2(out)return out
model= NeuralNet(input_size, hidden_size, num_classes)
model.train()
model.eval()另外还有一点需要说明的是,训练阶段随机采样时需要用model.train(),而测试阶段直接组装成一个整体的大网络时需要使用model.eval():
- 如果你二者都没使用的话,默认情况下实际上是相当于使用了model.train(),也就是开启dropout随机采样了——这样你如果你是在测试的话,准确率可能会受到影响。
- 如果你不希望开启dropout训练,想直接以一个整体的大网络来训练,不需要重写一个网络结果,而只需要在训练阶段开启model.eval()即可。