上一篇:Java并发容器之ConcurrentHashMap详解
本文目录:
2.3、ArrayBlockingQueue的(阻塞)添加的实现原理
2.3.1、add(E e)方法 和 offer(E e)方法
2.4、ArrayBlockingQueue的(阻塞)移除实现原理
3.2、LinkedBlockingQueue的实现原理概论
3.3.1、add(E e) 和 offer(E e) 方法
4、 LinkedBlockingQueue和ArrayBlockingQueue迥异
推荐几篇不错的文章:
1、深入剖析java并发之阻塞队列LinkedBlockingQueue与ArrayBlockingQueue
本文大部分内容转载自:https://blog.csdn.net/javazejian/article/details/77410889。还有一小部分出自于《Java并发编程的艺术》书中。
本文在开篇介绍了Java提供的7种阻塞队列的基本概念,源码分析中只对ArrayBlockingQueue和LinkedBlockingQueue做了分析,如果想了解其他五种阻塞队列的源码分析,可以阅读这篇文章:解读 Java 阻塞队列 BlockingQueue
1、阻塞队列的基本概念
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加操作支持阻塞的插入和移除方法。
1、支持阻塞的插入方法:当队列满时,队列会阻塞插入元素的线程,直到队列不满;
2、支持阻塞的移除方法:在队列为空时,获取元素的线程会等待队列变为非空。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
Java中的阻塞队列接口BlockingQueue继承自Queue接口,先来看看Queue接口的情况:
public interface Queue<E> extends Collection<E> {
boolean add(E e); // 插入方法
boolean offer(E e); // 插入方法
E remove(); // 删除方法
E poll(); // 删除方法
E element(); // 检查方法
E peek(); // 检查方法
}再来看看阻塞队列接口为我们提供的主要方法:
public interface BlockingQueue<E> extends Queue<E> {
boolean add(E e);
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
void put(E e) throws InterruptedException;
E take() throws InterruptedException;
E poll(long timeout, TimeUnit unit) throws InterruptedException;
boolean remove(Object o);
}总结下上诉方法,可以分为以下三类:
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
1、抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出IllegalStateException(“Queue full”)异常。当队列为空时,从队列里获取元素时会抛出NoSuchElementException异常 。
2、返回特殊值:插入方法会返回是否成功,成功则返回true。移除方法,则是从队列里拿出一个元素,如果没有则返回null
3、一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里take元素,队列也会阻塞消费者线程,直到队列可用。
4、超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
- 插入方法:
add(E e) : 添加成功返回true,失败抛IllegalStateException异常;
offer(E e) : 成功返回 true,如果此队列已满,则返回 false;
put(E e) :将元素插入此队列的尾部,如果该队列已满,则一直阻塞。
- 删除方法:
remove(Object o) :移除指定元素,成功返回true,失败返回false;
poll() : 获取并移除此队列的头元素,若队列为空,则返回 null;
take():获取并移除此队列头元素,若没有元素则一直阻塞。
- 检查方法:
element() :获取但不移除此队列的头元素,没有元素则抛异常;
peek() :获取但不移除此队列的头;若队列为空,则返回 null。
- 需要注意的几个点:
BlockingQueue 不接受 null 值的插入,相应的方法在碰到 null 的插入时会抛出 NullPointerException 异常。null 值在这里通常用于作为特殊值返回(表格中的第三列),代表 poll 失败。所以,如果允许插入 null 值的话,那获取的时候,就不能很好地用 null 来判断到底是代表失败,还是获取的值就是 null 值。
一个 BlockingQueue 可能是有界的,如果在插入的时候,发现队列满了,那么 put 操作将会阻塞。通常,在这里我们说的无界队列也不是说真正的无界,而是它的容量是 Integer.MAX_VALUE(21亿多)。
BlockingQueue 是设计用来实现生产者-消费者队列的。当然,你也可以将它当做普通的 Collection 来用,前面说了,它实现了 java.util.Collection 接口。例如,我们可以用 remove(x) 来删除任意一个元素,但是,这类操作通常并不高效,所以尽量只在少数的场合使用,比如一条消息已经入队,但是需要做取消操作的时候。
BlockingQueue 的实现都是线程安全的,但是批量的集合操作:如 addAll、containsAll、retainAll和 removeAll 不一定是原子操作。如 addAll(c) 有可能在添加了一些元素后中途抛出异常,此时 BlockingQueue 中已经添加了部分元素,这个是允许的,取决于具体的实现。
BlockingQueue 不支持 close 或 shutdown 等关闭操作,此特性取决于具体的实现,不做强制约束。
最后,BlockingQueue 在生产者-消费者的场景中,是支持多消费者和多生产者的,说的其实就是线程安全问题。
-
Java里的阻塞队列
JDK7提供了7个阻塞队列。分别是:
1、ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
2、LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
3、PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
4、DelayQueue:一个使用优先级队列实现的无界阻塞队列。
5、SynchronousQueue:一个不存储元素的阻塞队列。
6、LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
7、LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
ArrayBlockingQueue是一个用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。
默认情况下不保证访问者公平的访问队列,所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。
-
LinkedBlockingQueue
LinkedBlockingQueue是一个用链表实现的有界阻塞队列。此队列的默认和最大长度为Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
PriorityBlockingQueue是一个支持优先级的无界队列。默认情况下元素采取自然顺序排列,也可以通过比较器comparator来指定元素的排序规则。元素按照升序排列。
-
DelayQueue
DelayQueue是一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将
DelayQueue运用在以下应用场景:
1、缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
2、定时任务调度:使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。
-
SynchronousQueue
SynchronousQueue是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。
SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合传递性场景。
SynchronousQueue的吞吐量高于 LinkedBlockingQueue 和 ArrayBlockingQueue。
-
LinkedTransferQueue
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列,LinkedBlockingQueue多了tryTransfer和transfer方法。
-
LinkedBlockingDeque
LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列。所谓双向队列指的是可以从队列的两端插入和移除元素。
双向队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。
在初始化LinkedBlockingDeque时可以设置容量防止其过度膨胀。另外,双向阻塞队列可以运用在“工作窃取”模式中。
2、ArrayBlockingQueue
下面源码部分的讲解都是基于JDK1.8。
2.1、ArrayBlockingQueue的基本使用
ArrayBlockingQueue 是一个用数组实现的有界阻塞队列,其内部按先进先出的原则对元素进行排序,其中put方法和take方法为添加和删除的阻塞方法,下面我们通过ArrayBlockingQueue队列实现一个生产者消费者的案例,通过该案例简单了解其使用方式。
package com.zju.BlockingQueue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.TimeUnit;
public class ArrayBlockingQueueDemo {
private final static ArrayBlockingQueue<Apple> queue = new ArrayBlockingQueue<>(1);
public static void main(String[] args) {
new Thread(new Producer(queue)).start();
new Thread(new Producer(queue)).start();
new Thread(new Consumer(queue)).start();
new Thread(new Consumer(queue)).start();
}
}
// 产品类:苹果
class Apple{
public Apple(){
}
}
// 生产者线程
class Producer implements Runnable{
private ArrayBlockingQueue<Apple> mAbq;
public Producer(ArrayBlockingQueue<Apple> arrayBlockingQueue) {
this.mAbq = arrayBlockingQueue;
}
@Override
public void run() {
while(true){
produce();
}
}
private void produce(){
try {
Apple apple = new Apple();
mAbq.put(apple);
System.out.println("生产苹果:" + apple);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// 消费者线程
class Consumer implements Runnable{
private ArrayBlockingQueue<Apple> mAbq;
public Consumer(ArrayBlockingQueue<Apple> arrayBlockingQueue) {
this.mAbq = arrayBlockingQueue;
}
@Override
public void run() {
while(true){
try {
TimeUnit.MICROSECONDS.sleep(1000);
consume();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private void consume() throws InterruptedException{
Apple apple = mAbq.take();
System.out.println("消费苹果:" + apple);
}
}
代码比较简单, Consumer 消费者和 Producer 生产者,通过ArrayBlockingQueue 队列获取和添加元素,其中消费者调用了take()方法获取元素当队列没有元素就阻塞,生产者调用put()方法添加元素,当队列满时就阻塞,通过这种方式便实现生产者消费者模式。比直接使用等待唤醒机制或者Condition条件队列来得更加简单。执行代码,打印部分Log如下:
有点需要注意的是ArrayBlockingQueue内部的阻塞队列是通过重入锁ReenterLock和Condition条件队列实现的,所以ArrayBlockingQueue中的元素存在公平访问与非公平访问的区别。对于公平访问队列,被阻塞的线程可以按照阻塞的先后顺序访问队列,即先阻塞的线程先访问队列。而非公平队列,当队列可用时,阻塞的线程将进入争夺访问资源的竞争中,也就是说谁先抢到谁就执行,没有固定的先后顺序。创建公平与非公平阻塞队列代码如下:
// 默认非公平阻塞队列
ArrayBlockingQueue queue = new ArrayBlockingQueue(2);
// 公平阻塞队列
ArrayBlockingQueue queue1 = new ArrayBlockingQueue(2,true);
// 构造方法源码
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}除了常用的put、take等方法外,其他方法如下:
// 自动移除此队列中的所有元素。
void clear()
// 如果此队列包含指定的元素,则返回 true。
boolean contains(Object o)
// 移除此队列中所有可用的元素,并将它们添加到给定collection中。
int drainTo(Collection<? super E> c)
// 最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定collection 中。
int drainTo(Collection<? super E> c, int maxElements)
// 返回在此队列中的元素上按适当顺序进行迭代的迭代器。
Iterator<E> iterator()
// 返回队列还能添加元素的数量
int remainingCapacity()
// 返回此队列中元素的数量。
int size()
// 返回一个按适当顺序包含此队列中所有元素的数组。
Object[] toArray()
// 返回一个按适当顺序包含此队列中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。
<T> T[] toArray(T[] a)2.2、ArrayBlockingQueue原理概要
BlockingQueue的接口信息,上面已经表诉的很清楚了,为了后文中更好的理解ArrayBlockingQueue,现在我们来看看它和Queue以及AbstractQueue之间的关系。
public abstract class AbstractQueue<E> extends AbstractCollection<E> implements Queue<E> {
protected AbstractQueue() {
}
public boolean add(E e) {
...省略
}
public E remove() {
...省略
}
public E element() {
...省略
}
public void clear() {
...省略
}
public boolean addAll(Collection<? extends E> c) {
...省略
}
}ArrayBlockingQueue继承了AbstractQueue、实现了BlockingQueue接口,其内部是通过一个可重入锁ReentrantLock和两个Condition条件对象来实现阻塞,这里先看看其内部成员变量。
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
// 存储数据的数组
final Object[] items;
// 获取数据的索引,主要用于take,poll,peek,remove方法
int takeIndex;
// 添加数据的索引,主要用于 put, offer, or add 方法
int putIndex;
// 队列元素的个数
int count;
// 控制并发访问的锁
final ReentrantLock lock;
// notEmpty条件对象,用于通知take方法队列已有元素,可执行获取操作
private final Condition notEmpty;
// notFull条件对象,用于通知put方法队列未满,可执行添加操作
private final Condition notFull;
// 迭代器
transient Itrs itrs = null;
......
}从成员变量可看出,ArrayBlockingQueue内部确实是通过数组对象items来存储所有的数据,值得注意的是ArrayBlockingQueue通过一个ReentrantLock来同时控制添加线程与移除线程的并发访问,这点与LinkedBlockingQueue区别很大(稍后会分析)。而对于notEmpty条件对象则是用于存放等待或唤醒调用take方法的线程,告诉他们队列已有元素,可以执行获取操作。同理notFull条件对象是用于等待或唤醒调用put方法的线程,告诉它们,队列未满,可以执行添加元素的操作。takeIndex代表的是下一个方法(take,poll,peek,remove)被调用时获取数组元素的索引,putIndex则代表下一个方法(put, offer, or add)被调用时元素添加到数组中的索引。图示如下 :

2.3、ArrayBlockingQueue的(阻塞)添加的实现原理
2.3.1、add(E e)方法 和 offer(E e)方法
- 第1步:调用ArrayBlockingQueue中的add(E e)方法
public boolean add(E e) {
return super.add(e);
}可以看到add方法实际上调用的是ArrayBlockingQueue中的add(E e)方法。
- 第2步:调用AbstractQueue中的add(E e)方法
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}可以发现ArrayBlockingQueue中的add方法又调用了其子类ArrayBlockingQueue中的offer(E e)方法。
- 第3步:调用ArrayBlockingQueue中的offer(E e)方法
public boolean offer(E e) {
checkNotNull(e); // 检查元素是否为null
final ReentrantLock lock = this.lock;
lock.lock(); // 加锁
try {
if (count == items.length) // 判断队列是否满
return false;
else {
enqueue(e); // 添加元素到队列
return true;
}
} finally {
lock.unlock();
}
}- 第4步:调用ArrayBlockingQueue中的enqueue(E e)方法,入队操作
private void enqueue(E x) {
// 获取当前数组
final Object[] items = this.items;
// 通过putIndex索引对数组进行赋值
items[putIndex] = x;
// 索引自增,如果已是最后一个位置,重新设置 putIndex = 0;
if (++putIndex == items.length)
putIndex = 0;
count++; // 队列中元素数量加1
// 唤醒调用take()方法的线程,执行元素获取操作。
notEmpty.signal();
}这里的add方法和offer方法实现比较简单,其中需要注意的是enqueue(E x)方法,其方法内部通过putIndex索引直接将元素添加到数组items中。
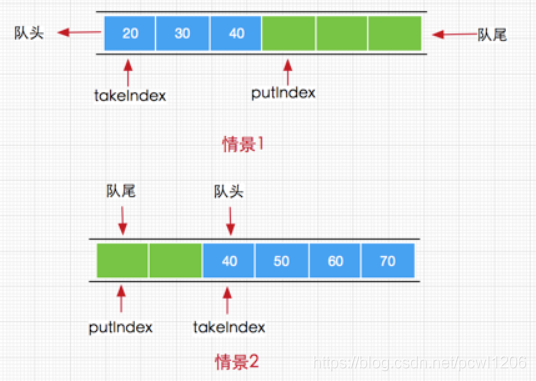
这里可能会疑惑的是:当putIndex索引大小等于数组长度时,需要将putIndex重新设置为0,这是因为当前队列执行元素获取时总是从队列头部获取,而添加元素从中从队列尾部获取,所以当队列索引(从0开始)与数组长度相等时,下次我们就需要从数组头部开始添加了,如下图演示 :
2.3.2、put(E e)方法
put方法是一个阻塞添加方法,即阻塞时可中断。
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 该方法可中断
try {
// 当队列元素个数与数组长度相等时,无法添加元素
while (count == items.length)
// 将当前调用线程挂起,添加到notFull条件队列中等待唤醒
notFull.await();
enqueue(e); // 如果队列没有满直接添加。。
} finally {
lock.unlock();
}
}put方法是一个阻塞的方法,如果队列元素已满,那么当前线程将会被notFull条件对象挂起加到等待队列中,直到队列有空位才会唤醒添加操作。但如果队列没有满,那么就直接调用enqueue(e)方法将元素加入到数组队列中。
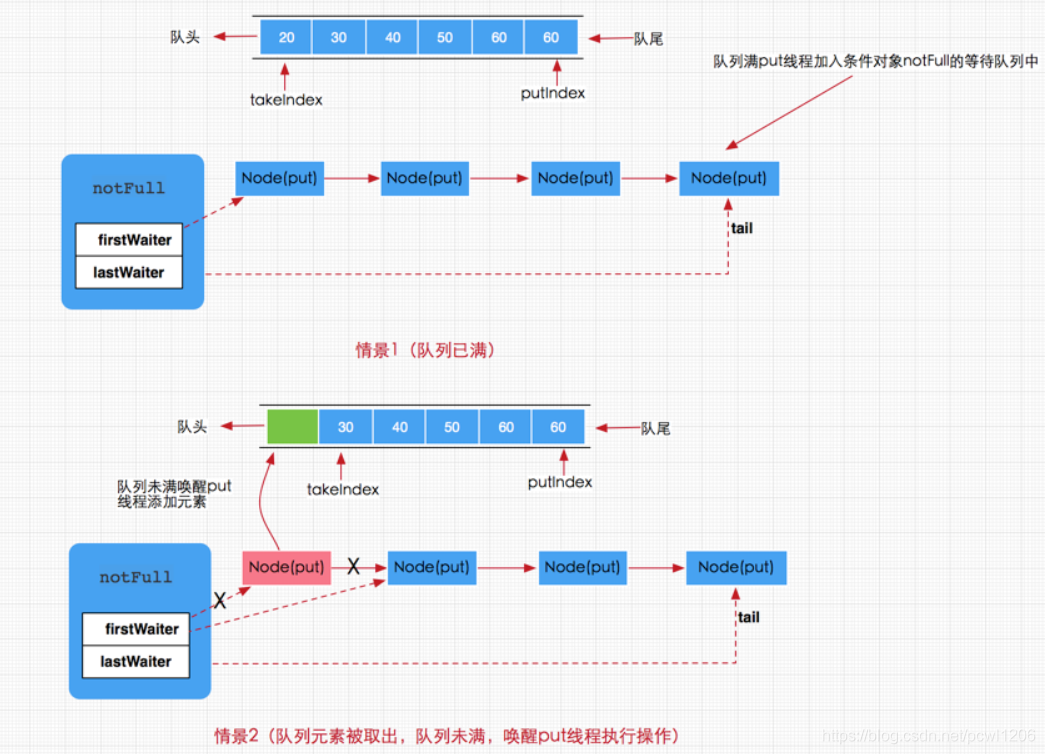
到此我们对三个添加方法即put,offer,add都分析完毕,其中offer,add在正常情况下都是无阻塞的添加,而put方法是阻塞添加。这就是阻塞队列的添加过程。说白了就是当队列满时通过条件对象Condtion来阻塞当前调用put方法的线程,直到线程又再次被唤醒执行。总得来说添加线程的执行存在以下两种情况:
1、队列已满,那么新到来的 put 线程将添加到 notFull 的条件队列中等待;
2、有移除线程执行移除操作,移除成功同时唤醒 put 线程。
如下图所示 :
2.4、ArrayBlockingQueue的(阻塞)移除实现原理
2.4.1、poll()方法
poll:该方法获取并移除此队列的头元素,若队列为空,则返回 null 。
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 判断队列是否为null,不为null执行dequeue()方法,否则返回null
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
// 删除队列头元素并返回
private E dequeue() {
// 拿到当前数组的数据
final Object[] items = this.items;
@SuppressWarnings("unchecked")
// 获取要删除的对象
E x = (E) items[takeIndex];
// 将数组中takeIndex索引位置设置为null
items[takeIndex] = null;
// takeIndex索引加1并判断是否与数组长度相等,
// 如果相等说明已到尽头,恢复为0
if (++takeIndex == items.length)
takeIndex = 0;
count--; // 队列个数减1
if (itrs != null)
itrs.elementDequeued(); // 同时更新迭代器中的元素数据
// 删除了元素说明队列有空位,唤醒notFull条件对象添加线程,执行添加操作
notFull.signal();
return x;
}poll():获取并删除队列头元素,队列没有数据就返回null,内部通过dequeue()方法删除头元素,注释很清晰,这里不重复了。
2.4.2、remove(Object o)方法
public boolean remove(Object o) {
if (o == null) return false;
// 获取数组数据
final Object[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock(); // 加锁
try {
// 如果此时队列不为null,这里是为了防止并发情况
if (count > 0) { // count为队列中元素的个数
// 获取下一个要添加元素时的索引
final int putIndex = this.putIndex;
// 获取当前要被删除元素的索引
int i = takeIndex;
// 执行循环查找要删除的元素
do {
// 找到要删除的元素
if (o.equals(items[i])) {
removeAt(i); // 执行删除
return true; // 删除成功返回true
}
// 当前删除索引执行加1后判断是否与数组长度相等
// 若为true,说明索引已到数组尽头,将i设置为0
if (++i == items.length)
i = 0;
} while (i != putIndex); // 继承查找
}
return false;
} finally {
lock.unlock();
}
}
// 根据索引删除元素,实际上是把删除索引之后的元素往前移动一个位置
void removeAt(final int removeIndex) {
final Object[] items = this.items;
// 先判断要删除的元素是否为当前队列头元素
if (removeIndex == takeIndex) {
// 如果是直接删除
items[takeIndex] = null;
// 当前队列头元素加1并判断是否与数组长度相等,若为true设置为0
if (++takeIndex == items.length)
takeIndex = 0;
count--; // 队列元素减1
if (itrs != null)
itrs.elementDequeued(); // 更新迭代器中的数据
} else {
// 如果要删除的元素不在队列头部,
// 那么只需循环迭代把删除元素后面的所有元素往前移动一个位置
// 获取下一个要被添加的元素的索引,作为循环判断结束条件
final int putIndex = this.putIndex;
// 执行循环
for (int i = removeIndex;;) {
// 获取要删除节点索引的下一个索引
int next = i + 1;
// 判断是否已为数组长度,如果是从数组头部(索引为0)开始找
if (next == items.length)
next = 0;
// 如果查找的索引不等于要添加元素的索引,说明元素可以再移动
if (next != putIndex) {
items[i] = items[next]; // 把后一个元素前移覆盖要删除的元
i = next;
} else {
// 在removeIndex索引之后的元素都往前移动完毕后清空最后一个元素
items[i] = null;
this.putIndex = i;
break; // 结束循环
}
}
count--; // 队列元素减1
if (itrs != null)
itrs.removedAt(removeIndex); // 更新迭代器数据
}
notFull.signal(); // 唤醒添加线程
}remove(Object o)方法的删除过程相对复杂些,因为该方法并不是直接从队列头部删除元素。首先线程先获取锁,再一步判断队列 count > 0, 这点是保证并发情况下删除操作安全执行。接着获取下一个要添加源的索引 putIndex 以及 takeIndex 索引 ,作为后续循环的结束判断,因为只要 putIndex 与 takeIndex 不相等就说明队列没有结束。然后通过while循环找到要删除的元素索引,执行 removeAt(i) 方法删除。
在 removeAt(i) 方法中实际上做了两件事,一是首先判断队列头部元素是否为删除元素,如果是直接删除,并唤醒添加线程;二是如果要删除的元素并不是队列头元素,那么执行循环操作,从要删除元素的索引removeIndex之后的元素都往前移动一个位置,那么要删除的元素就被removeIndex之后的元素替换,从而也就完成了删除操作。
2.4.3、take()方法
take()方法:是一个阻塞方法,直接获取队列头元素并删除。
// 从队列头部删除,队列没有元素就阻塞,可中断
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); //中断
try {
// 如果队列没有元素
while (count == 0)
// 执行阻塞操作
notEmpty.await(); // 等待notEmpty条件
return dequeue(); // 如果队列有元素执行删除操作
} finally {
lock.unlock();
}
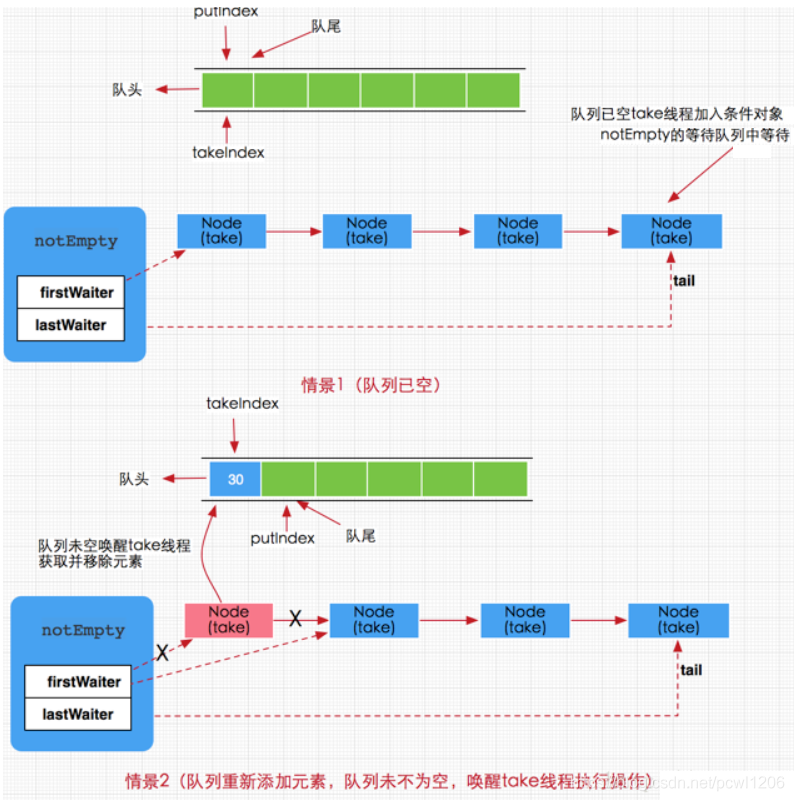
}take 方法其实很简单,有就删除,没有就阻塞。注意这个阻塞是可以中断的,如果队列没有数据那么就加入notEmpty条件队列等待(有数据就直接取走,方法结束),如果有新的 put 线程添加了数据,那么 put 操作将会唤醒 take 线程,执行 take 操作。图示如下:
2.4.4、peek()方法
public E peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 直接返回当前队列的头元素,但不删除
return itemAt(takeIndex);
} finally {
lock.unlock();
}
}
// 返回队列数组下标为i的元素
final E itemAt(int i) {
return (E) items[i];
}peek方法非常简单,直接返回当前队列的头元素但不删除任何元素。
ok~,到此对于ArrayBlockingQueue的主要方法就分析完了!
3、LinkedBlockingQueue
3.1、LinkedBlockingQueue的基本概要
LinkedBlockingQueue 是一个由链表实现的有界队列阻塞队列,但大小默认值为Integer.MAX_VALUE。所以我们在使用 LinkedBlockingQueue 时建议手动传值,让其提供我们所需的大小,避免队列过大造成机器负载或者内存爆满等情况。其构造函数如下:
// 默认大小为Integer.MAX_VALUE
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
// 创建指定大小为capacity的阻塞队列
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
// 创建大小默认值为Integer.MAX_VALUE的阻塞队列并添加c中的元素到阻塞队列
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock(); // Never contended, but necessary for visibility
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}从源码看,有三种方式可以构造LinkedBlockingQueue。通常情况下,我们建议创建指定大小的LinkedBlockingQueue阻塞队列,即上诉代码中的第2种。
LinkedBlockingQueue 队列也是按 FIFO(先进先出)排序元素。队列的头部是在队列中时间最长的元素,队列的尾部是在队列中时间最短的元素,新元素插入到队列的尾部,而队列执行获取操作会获得位于队列头部的元素。
在正常情况下,基于链表的队列的吞吐量要高于基于数组的队列(ArrayBlockingQueue),因为其内部实现添加和删除操作使用了两个ReenterLock来控制并发执行,而ArrayBlockingQueue内部只是使用一个ReenterLock控制并发,因此LinkedBlockingQueue的吞吐量要高于ArrayBlockingQueue。
注意LinkedBlockingQueue和ArrayBlockingQueue的 API 几乎是一样的,但它们的内部实现原理不太相同,这点稍后会分析。使用LinkedBlockingQueue,我们同样也能实现生产者消费者模式。只需把前面ArrayBlockingQueue案例中的阻塞队列对象换成LinkedBlockingQueue即可。这里限于篇幅就不贴重复代码了。接下来我们重点分析LinkedBlockingQueue的内部实现原理,最后我们将对ArrayBlockingQueue和LinkedBlockingQueue 做总结,阐明它们间的不同之处。
3.2、LinkedBlockingQueue的实现原理概论
LinkedBlockingQueue是一个基于链表的阻塞队列,其内部维持一个基于链表的数据队列,实际上我们对LinkedBlockingQueue的 API 操作都是间接操作该数据队列,这里我们先看看LinkedBlockingQueue的内部成员变量。
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
// 节点类,用于存储数据
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
// 阻塞队列的大小,默认为Integer.MAX_VALUE
private final int capacity;
// 当前阻塞队列中的元素个数
private final AtomicInteger count = new AtomicInteger();
// 阻塞队列的头结点
transient Node<E> head;
// 阻塞队列的尾节点
private transient Node<E> last;
// 获取并移除元素时使用的锁,如take, poll, etc
private final ReentrantLock takeLock = new ReentrantLock();
// notEmpty条件对象,当队列没有数据时,用于挂起执行删除的线程
private final Condition notEmpty = takeLock.newCondition();
// 添加元素时使用的锁如 put, offer, etc
private final ReentrantLock putLock = new ReentrantLock();
// notFull条件对象,当队列数据已满时,用于挂起执行添加的线程
private final Condition notFull = putLock.newCondition();
}从上述可看成,每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制。也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。
这里再次强调如果没有给LinkedBlockingQueue指定容量大小,其默认值将是Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出。这点在使用前希望慎重考虑。至于LinkedBlockingQueue的实现原理图与ArrayBlockingQueue是类似的,除了对添加和移除方法使用单独的锁控制外,两者都使用了不同的Condition条件对象作为等待队列,用于挂起take线程和put线程。
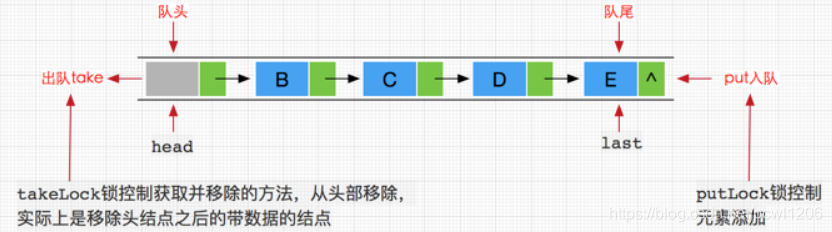
3.3、添加方法的实现原理
对于添加方法,主要指的是add,offer以及put。
3.3.1、add(E e) 和 offer(E e) 方法
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}从源码可以看出,add方法间接调用的是offer方法,如果add方法添加失败将抛出IllegalStateException异常,添加成功则返回true,那么下面我们直接看看offer的相关方法实现。
public boolean offer(E e) {
// 添加元素为null直接抛出异常
if (e == null) throw new NullPointerException();
// 获取队列的个数
final AtomicInteger count = this.count;
// 判断队列是否已满
if (count.get() == capacity)
return false;
int c = -1;
// 构建节点
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
// 再次判断队列是否已满,考虑并发情况
if (count.get() < capacity) {
enqueue(node); // 添加元素
c = count.getAndIncrement(); // 拿到当前未添加新元素时的队列长度
//如果容量还没满
if (c + 1 < capacity)
notFull.signal(); // 唤醒下一个添加线程,执行添加操作
}
} finally {
putLock.unlock();
}
// 由于存在添加锁和消费锁,而消费锁和添加锁都会持续唤醒等待线程,因此count肯定会变化。
// 这里的if条件表示如果队列中还有1条数据
if (c == 0)
signalNotEmpty(); // 如果还存在数据那么就唤醒消费锁
return c >= 0; // 添加成功返回true,否则返回false
}
// 入队操作
private void enqueue(Node<E> node) {
// 队列尾节点指向新的node节点
last = last.next = node;
}
// signalNotEmpty方法
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
// 唤醒获取并删除元素的线程
notEmpty.signal();
} finally {
takeLock.unlock();
}
}这里的offer()方法做了两件事:
第一件事是:判断队列是否满,满了就直接释放锁,没满就将节点封装成Node入队,然后再次判断队列添加完成后是否已满,不满就继续唤醒等到在条件对象notFull上的添加线程;
第二件事是:判断是否需要唤醒等待在notEmpty条件对象上的消费线程。
这里我们可能会有点疑惑,为什么添加完成后是继续唤醒在条件对象notFull上的添加线程而不是像ArrayBlockingQueue那样直接唤醒notEmpty条件对象上的消费线程?而又为什么要当if (c == 0)时才去唤醒消费线程呢?
唤醒添加线程的原因:在添加新元素完成后,会判断队列是否已满,不满就继续唤醒在条件对象notFull上的添加线程,这点与前面分析的ArrayBlockingQueue很不相同。在ArrayBlockingQueue内部完成添加操作后,会直接唤醒消费线程对元素进行获取,这是因为ArrayBlockingQueue只用了一个ReenterLock同时对添加线程和消费线程进行控制,这样如果在添加完成后再次唤醒添加线程的话,消费线程可能永远无法执行。而对于LinkedBlockingQueue来说就不一样了,其内部对添加线程和消费线程分别使用了各自的ReenterLock锁对并发进行控制,也就是说添加线程和消费线程是不会互斥的,所以添加锁只要管好自己的添加线程即可,添加线程自己直接唤醒自己的其他添加线程,如果没有等待的添加线程,直接结束了。如果有就直到队列元素已满才结束挂起,当然offer方法并不会挂起,而是直接结束,只有put方法才会当队列满时才执行挂起操作。注意消费线程的执行过程也是如此。这也是为什么LinkedBlockingQueue的吞吐量要相对大些的原因。
为什么要判断if (c == 0)时才去唤醒消费线程呢?
这是因为消费线程一旦被唤醒是一直在消费的(前提是有数据),所以c值是一直在变化的,c值是添加完元素前队列的大小,此时c只可能是0或c>0。
如果是 c = 0,那么说明之前消费线程已停止,条件对象上可能存在等待的消费线程。添加完数据后应该是c+1,那么有数据就直接唤醒等待消费线程,如果没有就结束啦,等待下一次的消费操作。
如果 c > 0 那么消费线程就不会被唤醒,只能等待下一个消费操作(poll、take、remove)的调用。那为什么不是条件c > 0才去唤醒呢?我们要明白的是消费线程一旦被唤醒会和添加线程一样,一直不断唤醒其他消费线程,如果添加前c>0,那么很可能上一次调用的消费线程后,数据并没有被消费完,条件队列上也就不存在等待的消费线程了,所以c>0唤醒消费线程得意义不是很大,当然如果添加线程一直添加元素,那么一直c>0,消费线程执行的快就要等待下一次调用消费操作了(poll、take、remove)。
3.4、移除方法的实现原理
关于移除的方法主要是指remove和poll以及take方法,下面一一分析。
3.4.1、remove方法
public boolean remove(Object o) {
if (o == null) return false;
fullyLock(); // 同时对putLock和takeLock加锁
try {
// 循环查找要删除的元素
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
if (o.equals(p.item)) { // 找到要删除的节点
unlink(p, trail); // 直接删除
return true;
}
}
return false;
} finally {
fullyUnlock(); // 解锁
}
}
// 两个同时加锁
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}remove方法删除指定的对象,这里我们可能会诧异,为什么同时对putLock和takeLock加锁?
这是因为remove方法删除的数据的位置不确定,为了避免造成并非安全问题,所以需要对2个锁同时加锁。
3.4.2、poll方法
public E poll() {
// 获取当前队列的大小
final AtomicInteger count = this.count;
if (count.get() == 0) // 如果没有元素直接返回null
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
// 判断队列是否有数据
if (count.get() > 0) {
// 如果有,直接删除并获取该元素值
x = dequeue();
// 当前队列大小减一
c = count.getAndDecrement();
// 如果队列未空,继续唤醒等待在条件对象notEmpty上的消费线程
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
// 判断c是否等于capacity,这是因为如果满说明NotFull条件对象上
// 可能存在等待的添加线程
if (c == capacity)
signalNotFull();
return x;
}
private E dequeue() {
Node<E> h = head; // 获取头结点
Node<E> first = h.next; // 获取头结的下一个节点(要删除的节点)
h.next = h; // 自己next指向自己,即被删除
head = first; // 更新头结点
E x = first.item; // 获取删除节点的值
first.item = null; // 清空数据,因为first变成头结点是不能带数据的,这样也就删除队列的带数据的第一个节点
return x;
}poll方法也比较简单,如果队列没有数据就返回null,如果队列有数据,那么就取出来,如果队列还有数据那么唤醒等待在条件对象notEmpty上的消费线程。然后判断if (c == capacity)为true就唤醒添加线程,这点与前面分析if(c==0)是一样的道理。因为只有可能队列满了,notFull条件对象上才可能存在等待的添加线程。
3.4.3、take方法
public E take() throws InterruptedException {
E x;
int c = -1;
// 获取当前队列大小
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();//可中断
try {
// 如果队列没有数据,挂起当前线程到条件对象的等待队列中
while (count.get() == 0) {
notEmpty.await();
}
// 如果存在数据直接删除并返回该数据
x = dequeue();
c = count.getAndDecrement(); // 队列大小减1
if (c > 1)
notEmpty.signal(); // 还有数据就唤醒后续的消费线程
} finally {
takeLock.unlock();
}
// 满足条件,唤醒条件对象上等待队列中的添加线程
if (c == capacity)
signalNotFull();
return x;
}take方法是一个可阻塞可中断的移除方法,主要做了两件事:
一是:如果队列没有数据就挂起当前线程到 notEmpty 条件对象的等待队列中一直等待,如果有数据就删除节点并返回数据项,同时唤醒后续消费线程;
二是:尝试唤醒条件对象 notFull 上等待队列中的添加线程。
到此关于remove、poll、take的实现也分析完了,其中只有take方法具备阻塞功能。remove方法则是成功返回true失败返回false,poll方法成功返回被移除的值,失败或没数据返回null。
下面再看看两个检查方法,即peek和element。
3.5、检查方法的实现原理
两个检查方法,即peek和element。
// 构造方法,head 节点不存放数据
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
public E element() {
E x = peek(); // 直接调用peek
if (x != null)
return x;
else
throw new NoSuchElementException(); // 没数据抛异常
}
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
// 获取头结节点的下一个节点
Node<E> first = head.next;
if (first == null)
return null; // 为null就返回null
else
return first.item; // 返回值
} finally {
takeLock.unlock();
}
}
从代码来看,head头结节点在初始化时是本身是不带数据的,仅仅作为头部head方便我们执行链表的相关操作。
peek返回直接获取头结点的下一个节点返回其值,如果没有值就返回null,有值就返回节点对应的值。
element方法内部调用的是peek,有数据就返回,没数据就抛异常。
下面我们最后来看两个根据时间阻塞的方法,比较有意思,利用的Conditin来实现的。
3.6、时间阻塞的方法
3.6.1、offer(E e, long timeout, TimeUnit unit)
// 在指定时间内阻塞添加的方法,超时就结束
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
// 将时间转换成纳秒
long nanos = unit.toNanos(timeout);
int c = -1;
// 获取锁
final ReentrantLock putLock = this.putLock;
// 获取当前队列大小
final AtomicInteger count = this.count;
// 锁中断(如果需要)
putLock.lockInterruptibly();
try {
// 判断队列是否满
while (count.get() == capacity) {
if (nanos <= 0)
return false;
// 如果队列满了,则根据等待时间阻塞等待
nanos = notFull.awaitNanos(nanos);
}
// 队列没满直接入队
enqueue(new Node<E>(e));
c = count.getAndIncrement();
// 唤醒条件对象上等待的线程
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 唤醒消费线程
if (c == 0)
signalNotEmpty();
return true;
}对于这个offer方法,我们重点来看看阻塞的这段代码
// 判断队列是否满
while (count.get() == capacity) {
if (nanos <= 0)
return false;
// 如果队列满根据阻塞的等待
nanos = notFull.awaitNanos(nanos);
}
// CoditionObject(Codition的实现类)中的awaitNanos方法
public final long awaitNanos(long nanosTimeout) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// 这里是将当前添加线程封装成node节点加入Condition的等待队列中
// 注意这里的node是AQS的内部类Node
Node node = addConditionWaiter();
// 加入等待,那么就释放当前线程持有的锁
int savedState = fullyRelease(node);
// 计算过期时间
final long deadline = System.nanoTime() + nanosTimeout;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {
transferAfterCancelledWait(node);
break;
}
// 主要看这里!!由于是while 循环,这里会不断判断等待时间
// nanosTimeout 是否超时
// static final long spinForTimeoutThreshold = 1000L;
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout); // 挂起线程
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
// 重新计算剩余等待时间,while循环中继续判断下列公式
// nanosTimeout >= spinForTimeoutThreshold
nanosTimeout = deadline - System.nanoTime();
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTER