文章目录
前言
目前需求需要将两张表的数据拼接成新数据并存入新的数据库,由于数据量较大(大概是几亿条数据),经过讨论决定采用多线程的方式迁移,并通过线程池来实现。
一、迁移设计?
1.迁移方案
因为要采用多线程迁移,因此需要有一个统一的数据管理的地方,这里采用redis存储迁移的页码,每个线程都从这里获取页码,保证数据不会重复迁移。同时,需要记录成功和失败的页码,也放在redis中,通过两个list存储。设计两个不同的线程池,一个负责数据的正常迁移,另一个负责失败数据的重试。正常迁移的线程池我们这里采用的是定长线程池,通过ThreadPoolExecutor类自己创建,而失败重试的线程池,考虑到失败的数据不会很多,这里只用了一个单线程线程池。同时,在数据插入的时候,还要考虑重复数据的插入更新,这个通过主键判断,存在就更新。
2.迁移流程图
整体流程如下图,所有线程去同一个地方获取当前页,然后将页码自增,带着获取的页码去分页查询,插入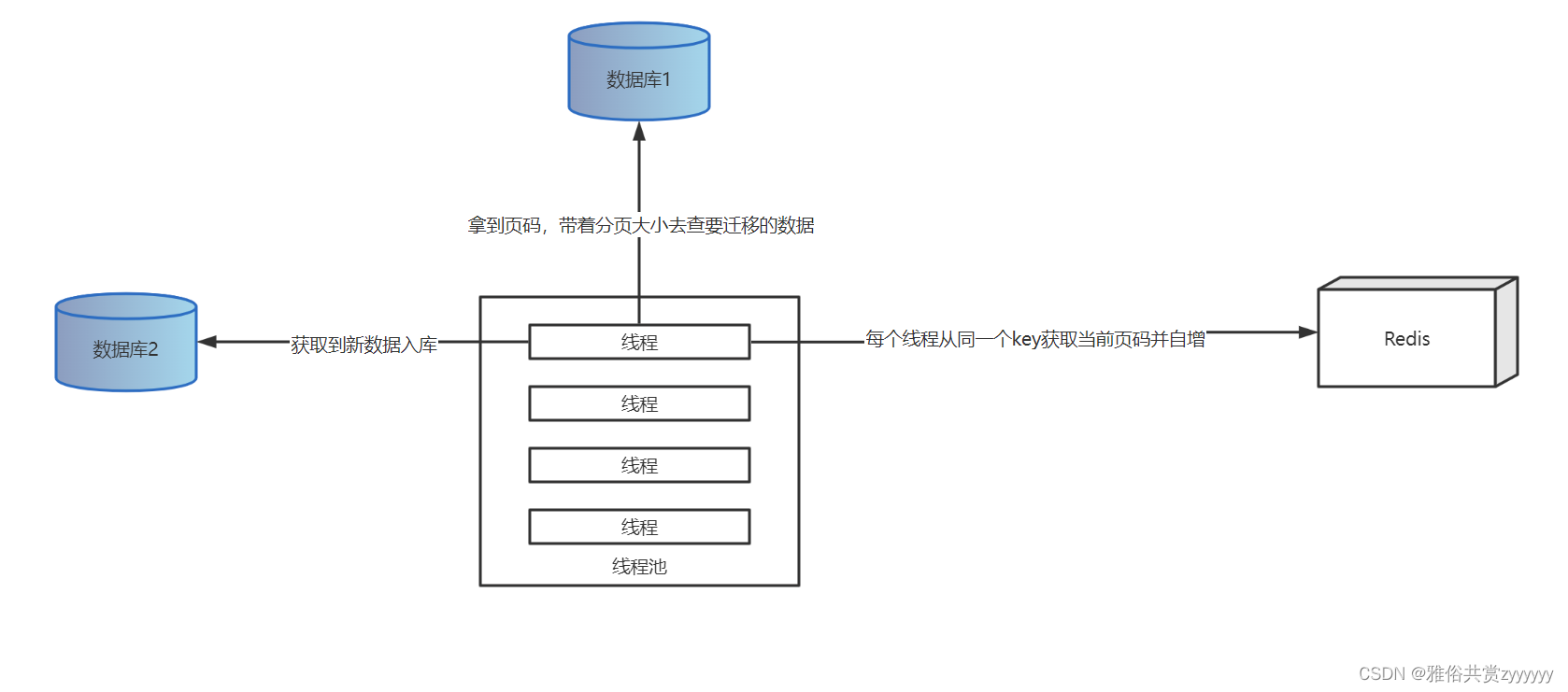
3.线程池的设计
正常数据迁移采用的10个线程的定长线程池,可以看到实现了一个CommandLineRunner接口,并且配合了@Order注解,通过实现CommandLineRunner接口实现数据预先加载,将数据库连接、redis连接等先预先加载,Order注解是标明第几个加载这个类,@ConditionalOnProperty(prefix = “config”,name=“threadpool”,havingValue = “move”)是在配置文件配置的值,因为有两个线程池,需要通过该配置值判断启动哪个线程池
@Slf4j
@Component
@Order(2)
@ConditionalOnProperty(prefix = "config",name="threadpool",havingValue = "move")
public class ThreadPoolConfig implements CommandLineRunner {
private ExecutorService executorService;
@Override
public void run(String... args) throws Exception {
this.executorService = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "数据迁移线程" + (int)((Math.random()*9+1)*100000));
}
});
int allDataNum;
if(!redisUtil.hExists(RedisKey.CORP_DATA_CONSTANT,RedisKey.DATA_NUM) || StringUtils.isEmpty(redisUtil.hGet(RedisKey.CORP_DATA_CONSTANT,RedisKey.DATA_NUM))){
allDataNum = corpDataService.countAllData();
redisUtil.hPut(RedisKey.CORP_DATA_CONSTANT,RedisKey.DATA_NUM,allDataNum);
}
String s1 = String.valueOf(redisUtil.hGet(RedisKey.CORP_DATA_CONSTANT,RedisKey.DATA_NUM));
allDataNum = Integer.valueOf(s1);
//初始化当前页
if(!redisUtil.hExists(RedisKey.CORP_DATA_CONSTANT,RedisKey.CUR_PAGE) || StringUtils.isEmpty(redisUtil.hGet(RedisKey.CORP_DATA_CONSTANT,RedisKey.CUR_PAGE))){
redisUtil.hPut(RedisKey.CORP_DATA_CONSTANT,RedisKey.CUR_PAGE,-1);
}
//这里用来分配任务,CorpDataThread类只负责数据查询导入,线程池自动分配线程执行,注意,这里只有10个线程来跑,千万不要认为循环多少次就创建多少线程
for (int j=0;j<allDataNum/RedisKey.PAGE_SIZE+1;j++){
int curPageNum = corpDataService.getCurPageNum();
if(curPageNum*RedisKey.PAGE_SIZE< allDataNum){
CorpDataThread corpDataThread = new CorpDataThread(corpDataService,curPageNum,RedisKey.PAGE_SIZE);
executorService.submit(corpDataThread);
}
}
log.debug("数据迁移结束!");
}
}
//线程任务类
public class CorpDataThread implements Runnable {
private CorpDataService corpDataService;
private int pageSize;
private int curPageNum;
public CorpDataThread(CorpDataService corpDataService, int curPageNum, int pageSize){
this.corpDataService = corpDataService;
this.curPageNum = curPageNum;
this.pageSize = pageSize;
}
@Override
public void run() {
//具体的实现,就是分页查表,然后插入
corpDataService.moveCorpData(curPageNum,pageSize);
}
}失败数据重试线程池如下,基本仿照前面写的,不同的就是一个单线程线程池,业务处理不同:
@Slf4j
@Component
@Order(3)
@ConditionalOnProperty(prefix = "config",name="threadpool",havingValue = "fail")
public class DealFailedData implements CommandLineRunner {
private ExecutorService executorService;
@Autowired
private RedisUtil redisUtil;
@Autowired
private CorpDataService corpDataService;
@Override
public void run(String... args) throws Exception {
this.executorService = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"迁移失败数据重试线程" + (int)((Math.random()*9+1)*100000));
}
});
List<Integer> failPageNums = new ArrayList<>();
while(redisUtil.lLen(RedisKey.FAIL_CORP_DATA)>0){
String pageNum = String.valueOf(redisUtil.lLeftPop(RedisKey.FAIL_CORP_DATA));
failPageNums.add(Integer.valueOf(pageNum));
}
if(failPageNums.size()>0){
FailDataThread failDataThread = new FailDataThread(failPageNums,corpDataService,RedisKey.PAGE_SIZE);
executorService.submit(failDataThread);
}else{
log.debug("不存在迁移失败数据!");
}
}
}
public class FailDataThread implements Runnable {
private List<Integer>failPageNums;
private CorpDataService corpDataService;
private int pageSize;
public FailDataThread(List<Integer> failPageNums, CorpDataService corpDataService, int pageSize) {
this.failPageNums = failPageNums;
this.corpDataService = corpDataService;
this.pageSize = pageSize;
}
@Override
public void run() {
corpDataService.dealFailData(failPageNums,pageSize);
}
}
页码自增方法
public int getCurPageNum() {
Long curPageL = redisUtil.hIncrBy(RedisKey.CORP_DATA_CONSTANT,RedisKey.CUR_PAGE,1);
String o = String.valueOf(curPageL);
return Integer.valueOf(o);
}二、出现的问题?
1.多数据源配置jdbcUrl is required with driverClassName问题
# 配置一
spring.datasource.type = com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name = com.mysql.cj.jdbc.Driver
spring.datasource.url = jdbc:mysql://00.00.00.0:3306/表1?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowMultiQueries=true&serverTimeZone=GMT
spring.datasource.username = 0000000000000000
spring.datasource.password = 0000000000000000
mybatis.mapper-locations = classpath:mapper/000/*.xml
# 配置二
spring.datasource.statistic.type = com.alibaba.druid.pool.DruidDataSource
spring.datasource.statistic.driver-class-name = com.mysql.cj.jdbc.Driver
spring.datasource.statistic.url = jdbc:mysql://00.00.0.00:3306/表2?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowMultiQueries=true&serverTimeZone=GMT
spring.datasource.statistic.username = 1111
spring.datasource.statistic.password = 1111111
spring.datasource.statistic.mapper-locations = classpath:mapper/1111/*.xml
注意,上面配置二中spring.datasource.statistic.url要改为spring.datasource.statistic.jdbc-url,官方解释的大概意思是spring.datasource.jdbc-url 用来重写自定义连接池
# 配置一
spring.datasource.type = com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name = com.mysql.cj.jdbc.Driver
spring.datasource.url = jdbc:mysql://00.00.00.0:3306/表1?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowMultiQueries=true&serverTimeZone=GMT
spring.datasource.username = 0000000000000000
spring.datasource.password = 0000000000000000
mybatis.mapper-locations = classpath:mapper/000/*.xml
# 配置二
spring.datasource.statistic.type = com.alibaba.druid.pool.DruidDataSource
spring.datasource.statistic.driver-class-name = com.mysql.cj.jdbc.Driver
spring.datasource.statistic.jdbc-url = jdbc:mysql://00.00.0.00:3306/表2?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&allowMultiQueries=true&serverTimeZone=GMT
spring.datasource.statistic.username = 1111
spring.datasource.statistic.password = 1111111
spring.datasource.statistic.mapper-locations = classpath:mapper/1111/*.xml2.数据插入更新
加上下面的代码即可
on DUPLICATE key update 非主键字段=VALUES(非主键字段)3.SQL查询不重复的数据
根据单个字段查询重复的数据:
SELECT userName from `User` GROUP BY userName HAVING count(*) > 1;根据多个字段查询重复的数据,需要注意字段要保证唯一性:
SELECT * FROM `User` GROUP BY userName,loginType HAVING count( * ) > 14.springboot无端口启动
这里就是上面为什么要实现CommandLineRunner接口,项目启动线程池就会提交任务,因此需要先将一些配置初始化加载
# SpringBoot无端口启动配置
spring.main.web-application-type=none三、优化过程?
前面的代码在跑少量数据(几万条)时,并没有显出速度的问题,但是在测试环境模拟了五百万条数据之后,问题暴露出来了,随着数据量的增大,分页查询的速度变得非常慢,因此,首先要优化的是分页查询。
1.sql优化
前面的分页是放在A表左连接B表之后的,而且还做了按时间排序,这样导致查询效率很慢,因此,经过分析,将排序和分页放到A表上,同时,由于A表的主键是自增的,因此不再通过时间排序,而是通过主键排序,sql如下:
-- 优化一、把排序和分页放到账户表
select c.creditKey,c.status,c.source,c.createTime,c.certKey from (
select d.*,b.certificate_key as creditKey from
(select corp_id,'1' as status,a.agent_certkey as certKey,a.agent_channel as source,a.create_date as createTime from uc_corporator_account_net a ORDER BY a.account_id asc limit 100,100)
d
LEFT JOIN uc_corporator_identity_net b on d.corp_id=b.corp_id)
c这样一来,速度得到了瞬间提升。但是,这样还是分页查询,只要分页查询,就会造成随着页码的增大,速度衰减,然后,又看了一下其他的优化分页查询的方案,通过分页查询主键,然后A表内连接(或者join)这些主键,也是会提升一些性能的,但是这次的提升肯定没有第一次那么大。sql如下:
-- 优化二、把排序和分页放到账户表的主键
select c.creditKey,c.status,c.source,c.createTime,c.certKey from (
select d.*,b.certificate_key as creditKey from
(select a.account_id,a.corp_id,'1' as status,a.agent_certkey as certKey,a.agent_channel as source,a.create_date as createTime from uc_corporator_account_net a INNER JOIN (select account_id from uc_corporator_account_net ORDER BY account_id asc limit 100,100) bb where a.account_id=bb.account_id)
d
LEFT JOIN uc_corporator_identity_net b on d.corp_id=b.corp_id)
c经过这两次优化,速度相比优化前提升很大。之前70分钟30多万,现在24分钟210多万,速度提升了20倍。2022.04.14修改。
2.线程池优化?
之前是固定10个核心线程和最大线程的线程池,今天改成了核心数量是2CPU,最大线程数是4CPU,通过测试,大概提升了20分钟速度。获取CPU数量代码如下:
int cpuNum = Runtime.getRuntime().availableProcessors();3.机器优化?
在设计迁移的方案时,考虑到了启动多个节点(多个机器跑服务)去迁移,由于使用的是同一个Redis,保证了当前页的唯一性,因此,在测试环境启动了两个节点,跑完500W数据用了40分钟。因此,节点越多,速度越快,所以,最好的优化方案很简单–加机器
总结
这两个线程池通过测试环境,测试插入7万条数据的时间不到一分钟,后续在生产上运行的结果也会继续更新,出现的问题也会继续更新。
更新:
在测试环境造了500W数据,经过优化,两节点跑完时间是40分钟,等后续看生产情况。