引言:前一阵子学习python网络爬虫,于是拿“支-部-工作”的网站练练手,初步实现了自动登录,cookie管理,阅读n条新闻并发表评论,学习未学习过的内容并发表评论。
关键字:网络爬虫,OCR,
开发环境:
Python3.6, Chromedriver/ (PhantomJS),
依赖库: BeautifulSoup4, openCV-python, PIL, pickle, pyocr, random, re, selenium, sys, time
0.设置浏览器
0.1. selenium + PhantomJS
PhantomJS需要设置头userAgent,不然会被直接拦截下来,包装头的写法可以直接打开浏览器查看,以Chrome浏览器为例,在地址栏输入about://version就可以看到。selenium提供了包装头的功能,具体实现如下:
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilitiesdcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/63.0.3239.132")
driver = webdriver.PhantomJS(executable_path='/usr/local/Cellar/phantomjs/2.1.1/bin/phantomjs',
desired_capabilities=dcap)
print('PhantomJS is adopted') PhantomJS已经年久失修,现在运行的时候会warning,可以不用理会。
UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
0.2. selenium + Chrome浏览器
Chrome浏览器安装好以后,需要下载对应版本的Chromedriver. ChromeDriver对应版本及下载地址如下:
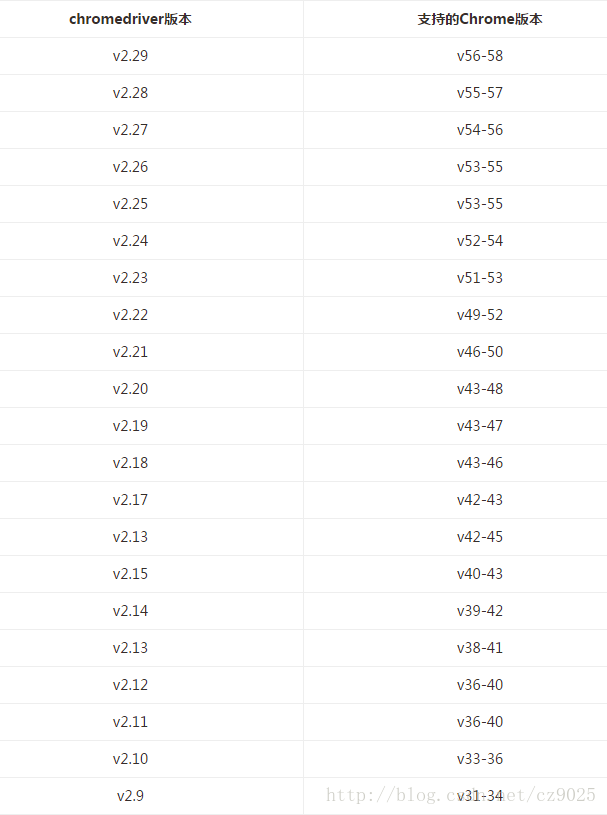
点击打开链接:http://npm.taobao.org/mirrors/chromedriver/
Chrome不需要设置UserAgent,因为本身就是一个真实的浏览器。
from selenium import webdriverdriver = webdriver.Chrome()无头版的Chrome浏览器也非常容易实现,实现方法如下
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options = chrome_options)至此,浏览器已经设置好了。
1. 登陆界面:
driver.get("https://www.zhibugongzuo.com/site/login")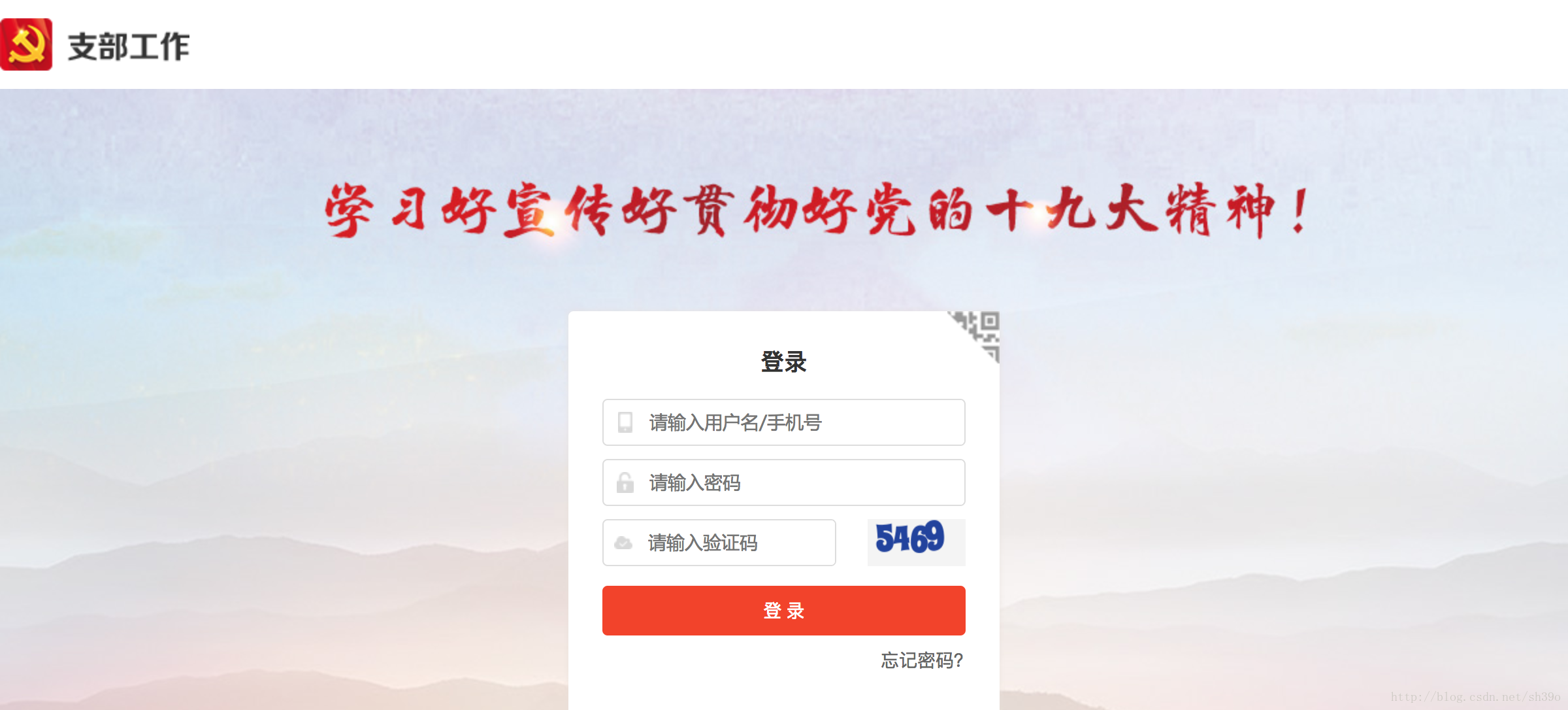
对应用户名,密码,验证码的网络源代码如下:
<input id="username" autocomplete="off" maxlength="18" placeholder="请输入用户名/手机号" tabindex="1" name="LoginForm[username]" type="text">
<input id="password" autocomplete="off" maxlength="18" placeholder="请输入密码" tabindex="2" name="LoginForm[password]" type="password">
<input id="verifyCode" autocomplete="off" maxlength="18" style="width:143px;" placeholder="请输入验证码" tabindex="3" name="LoginForm[verifyCode]" type="text">这几项都有id,使用find_element_by_id('')找到对应元素,然后使用element.send_keys()实现填写内容。
user = driver.find_element_by_id('username')
user.send_keys(username)
passwd = driver.find_element_by_id('password')
passwd.send_keys(password)
verify = driver.find_element_by_id('verifyCode')
verify.send_keys(verify_code)登陆按钮的html代码如下:
<button>登 录</button>通过tagname找到该元素并进行鼠标单击操作
driver.find_element_by_tag_name("button").click()就可以完成登陆了。
2. 验证码识别
上面登陆操作需要手动识别验证码,还不够自动化,自动化识别验证码OCR(Optical Character Recognition, 光学字符识别)的一些内容。
我采取的策略如下直接截图浏览器页面,抠出验证码那部分的策略获取验证码,然后使用opencv进行图片前处理,最后使用Tesseract进行识别。
2.1 浏览器截图
selenium下的get_screen_as_file()可以完成浏览器截图的内容
driver.get_screenshot_as_file('01.png')2.2 获取验证码的元素
验证码图片html代码如下:
<img alt="看不清?点击我试试" title="看不清?点击我试试" style="cursor:pointer" width="75" height="36" id="login-captcha" class="login-captcha code-img fr" src="/site/captcha?v=5a94bed21042e">同样使用find_element_by_id()获取元素
verifyImage = driver.find_element_by_id('login-captcha')获取验证码图片的位置信息
left = int(verifyImage.location['x'])
right = int(verifyImage.location['y'])
top = left + int(verifyImage.size['width'])
bottom = top + int(verifyImage.size['height'])注:对于带有Retina 屏幕的Mac系统和使用Chrome的情况下,由于其分辨率问题,left right width height都需要乘2才能得到正确的结果,Mac系统下PhantomJS未发现此问题。
读取截图,并截取验证码图片部分,然后转为灰度图保存
from PIL import Image
im = Image.open('01.png')
im = im.crop((left, top, right, bottom)).convert('L')
im.save('verify.png')
verify.png
2.3 验证码前处理
由于验证码图片里面的数字存在很严重的粘连,pytesseract基本不能成功识别出文字,所以我先把图片转换为2黑白图,然后用腐蚀操作图片,将数字变细,达到提高识别率的效果。
tools = pyocr.get_available_tools()[:]
cap = cv2.imread('verify.png', 0)
cap[:] = 255 - cap[:]
ret, thresh = cv2.threshold(cap, 100, 255, cv2.THRESH_BINARY)
kernel = np.ones((3,3), dtype = np.uint8)
erosion = cv2.erode(thresh, kernel, iteration = 2)
cv2.imwrite('ocr_input.png', erosion)
verify_code = tools[0].image_to_string(cv2.imread('input-ocr.png'), lang = 'eng')

得到验证码以后使用element.send_keys()就可以完成自动提交验证码的工作。
3. selenium + cookies
使用cookie可以实现下次登陆不需要输入用户名密码,直接进入网页内容,selenium提供了非常便利的cookie的管理方法。
3.1 写入cookies
selenium的get_cookies()直接将所有的cookies返回为一个列表,利用python提供的pickle库可以很方便的保存它们
cookie_list = driver.get_cookies()
f = open('cookies.zhibu', 'wb')
pickle.dump(cookie_list, f)
f.close()3.2 读取cookies
selenium提供了add_cookie()来加载cookie,不过与存储不同,一次加载一个。
cookie_list = pickle.load(open('cookies.zhibu', 'rb'))
for cookie in cookie_list:
driver.add_cookie(cookie)