From:https://blog.csdn.net/weixin_37947156/article/details/74436333
使用 PyCharm 打开下载好的 Scrapy 源码(github:https://github.com/scrapy/scrapy)
scrapy命令
当用 scrapy 写好一个爬虫后,使用scrapy crawl <spider_name>命令就可以运行这个爬虫,那么这个过程中到底发生了什么?scrapy命令 从何而来?
实际上,当你成功安装scrapy后,使用如下命令,就能找到这个命令:
$ which scrapy
/usr/local/bin/scrapy使用vim或其他编辑器打开它:$ vim /usr/local/bin/scrapy
其实它就是一个 python 脚本,而且代码非常少。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import re
import sys
from scrapy.cmdline import execute
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0])
sys.exit(execute())安装 scrapy 后,为什么入口点是这里呢? 原因是在 scrapy 的安装文件setup.py中,声明了程序的入口处:
from os.path import dirname, join
from pkg_resources import parse_version
from setuptools import setup, find_packages, __version__ as setuptools_version
with open(join(dirname(__file__), 'scrapy/VERSION'), 'rb') as f:
version = f.read().decode('ascii').strip()
def has_environment_marker_platform_impl_support():
"""Code extracted from 'pytest/setup.py'
https://github.com/pytest-dev/pytest/blob/7538680c/setup.py#L31
The first known release to support environment marker with range operators
it is 18.5, see:
https://setuptools.readthedocs.io/en/latest/history.html#id235
"""
return parse_version(setuptools_version) >= parse_version('18.5')
extras_require = {}
if has_environment_marker_platform_impl_support():
extras_require[':platform_python_implementation == "PyPy"'] = [
'PyPyDispatcher>=2.1.0',
]
setup(
name='Scrapy',
version=version,
url='https://scrapy.org',
description='A high-level Web Crawling and Web Scraping framework',
long_description=open('README.rst').read(),
author='Scrapy developers',
maintainer='Pablo Hoffman',
maintainer_email='pablo@pablohoffman.com',
license='BSD',
packages=find_packages(exclude=('tests', 'tests.*')),
include_package_data=True,
zip_safe=False,
entry_points={
'console_scripts': ['scrapy = scrapy.cmdline:execute']
},
classifiers=[
'Framework :: Scrapy',
'Development Status :: 5 - Production/Stable',
'Environment :: Console',
'Intended Audience :: Developers',
'License :: OSI Approved :: BSD License',
'Operating System :: OS Independent',
'Programming Language :: Python',
'Programming Language :: Python :: 2',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
'Programming Language :: Python :: Implementation :: CPython',
'Programming Language :: Python :: Implementation :: PyPy',
'Topic :: Internet :: WWW/HTTP',
'Topic :: Software Development :: Libraries :: Application Frameworks',
'Topic :: Software Development :: Libraries :: Python Modules',
],
python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',
install_requires=[
'Twisted>=13.1.0',
'w3lib>=1.17.0',
'queuelib',
'lxml',
'pyOpenSSL',
'cssselect>=0.9',
'six>=1.5.2',
'parsel>=1.5',
'PyDispatcher>=2.0.5',
'service_identity',
],
extras_require=extras_require,
)entry_points 指明了入口是cmdline.py 的execute方法,在安装过程中,setuptools 这个包管理工具,就会把上述那一段代码生成放在可执行路径下。
这里也有必要说一下,如何用 python 编写一个可执行文件,其实非常简单,只需要以下几步即可完成:
- 编写一个带有 main 方法的 python 模块(首行必须注明 python 执行路径)
- 去掉.py后缀名
- 修改权限为可执行:chmod +x 脚本
这样,你就可以直接使用文件名执行此脚本了,而不用通过python <file.py> 的方式去执行,是不是很简单?
入口(execute.py)
既然现在已经知道了 scrapy 的入口是scrapy/cmdline.py的execute方法,我们来看一下这个方法。
主要的运行流程已经加好注释,这里我总结出了每个流程执行过程:
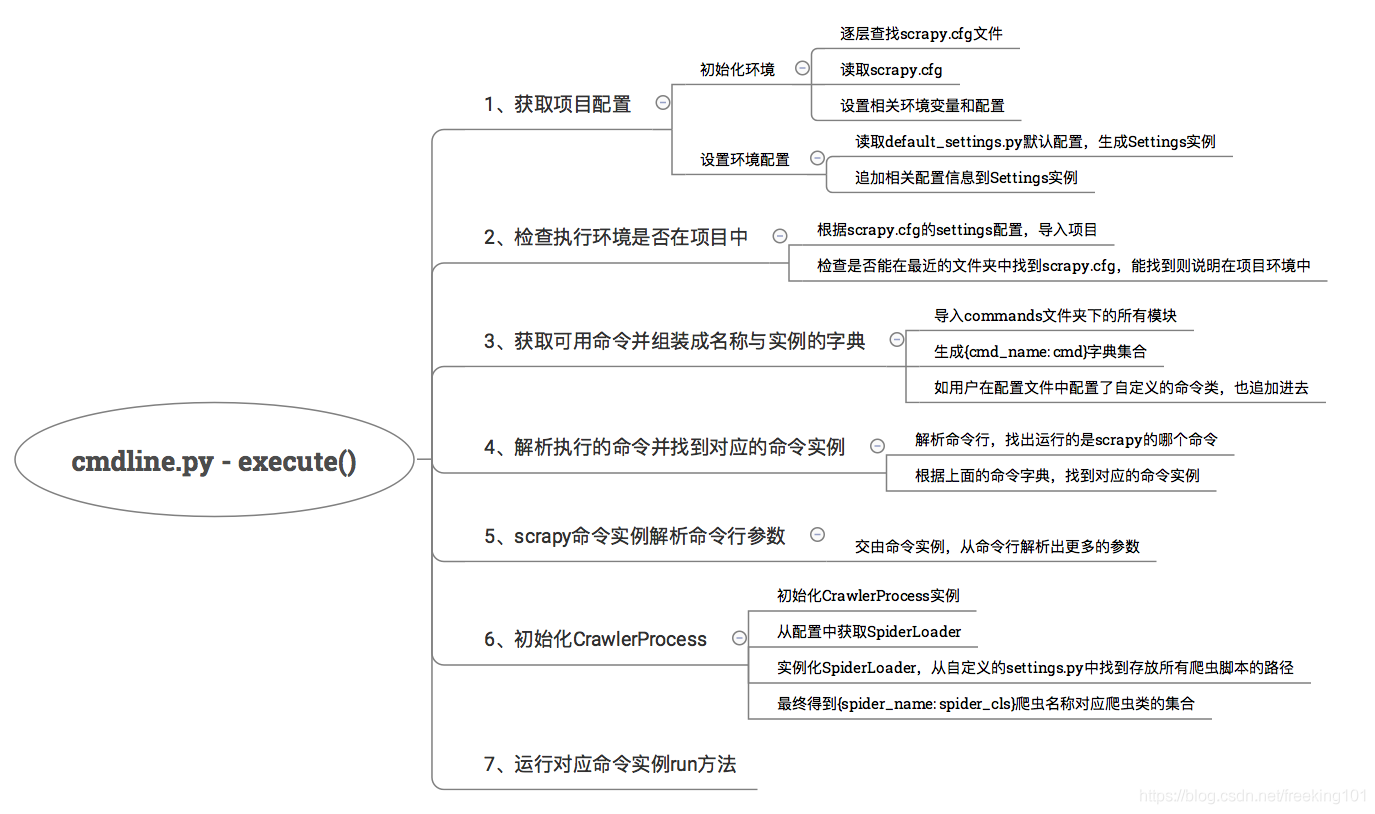
流程解析
初始化项目配置
这个流程比较简单,主要是根据环境变量和scrapy.cfg初始化环境,最终生成一个Settings实例,来看代码get_project_settings方法(from scrapy.utils.project import inside_project, get_project_settings):
def get_project_settings():
# 环境变量中是否有SCRAPY_SETTINGS_MODULE配置
if ENVVAR not in os.environ:
project = os.environ.get('SCRAPY_PROJECT', 'default')
# 初始化环境,找到用户配置文件settings.py,设置到环境变量SCRAPY_SETTINGS_MODULE中
init_env(project)
# 加载默认配置文件default_settings.py,生成settings实例
settings = Settings()
# 取得用户配置文件
settings_module_path = os.environ.get(ENVVAR)
# 更新配置,用户配置覆盖默认配置
if settings_module_path:
settings.setmodule(settings_module_path, priority='project')
# XXX: remove this hack
# 如果环境变量中有其他scrapy相关配置则覆盖
pickled_settings = os.environ.get("SCRAPY_PICKLED_SETTINGS_TO_OVERRIDE")
if pickled_settings:
settings.setdict(pickle.loads(pickled_settings), priority='project')
# XXX: deprecate and remove this functionality
env_overrides = {k[7:]: v for k, v in os.environ.items() if
k.startswith('SCRAPY_')}
if env_overrides:
settings.setdict(env_overrides, priority='project')
return settings这个过程中进行了Settings配置初始化(from scrapy.settings import Settings):
class Settings(BaseSettings):
"""
This object stores Scrapy settings for the configuration of internal
components, and can be used for any further customization.
It is a direct subclass and supports all methods of
:class:`~scrapy.settings.BaseSettings`. Additionally, after instantiation
of this class, the new object will have the global default settings
described on :ref:`topics-settings-ref` already populated.
"""
def __init__(self, values=None, priority='project'):
# Do not pass kwarg values here. We don't want to promote user-defined
# dicts, and we want to update, not replace, default dicts with the
# values given by the user
# 调用父类构造初始化
super(Settings, self).__init__()
# 把default_settings.py的所有配置set到settings实例中
self.setmodule(default_settings, 'default')
# Promote default dictionaries to BaseSettings instances for per-key
# priorities
# 把attributes属性也set到settings实例中
for name, val in six.iteritems(self):
if isinstance(val, dict):
self.set(name, BaseSettings(val, 'default'), 'default')
self.update(values, priority)程序 加载默认配置文件 default_settings.py 中的所有配置项设置到Settings中,且这个配置是有优先级的。
这个默认配置文件 default_settings.py 是非常重要的,个人认为还是有必要看一下里面的内容,这里包含了所有默认的配置,例如:调度器类、爬虫中间件类、下载器中间件类、下载处理器类等等。
在这里就能隐约发现,scrapy 的架构是非常低耦合的,所有组件都是可替换的。什么是可替换呢?
例如:你觉得默认的调度器功能不够用,那么你就可以按照它定义的接口标准,自己实现一个调度器,然后在自己的配置文件中,注册自己写的调度器模块,那么 scrapy 的运行时就会用上你新写的调度器模块了!(scrapy-redis 就是替换 scrapy 中的模块 来实现分布式)
只要在默认配置文件中配置的模块,都是可替换的。
检查环境是否在项目中
def inside_project():
# 检查此环境变量是否存在(上面已设置)
scrapy_module = os.environ.get('SCRAPY_SETTINGS_MODULE')
if scrapy_module is not None:
try:
import_module(scrapy_module)
except ImportError as exc:
warnings.warn("Cannot import scrapy settings module %s: %s" % (scrapy_module, exc))
else:
return True
# 如果环境变量没有,就近查找scrapy.cfg,找得到就认为是在项目环境中
return bool(closest_scrapy_cfg())scrapy 命令有的是依赖项目运行的,有的命令则是全局的,不依赖项目的。这里主要通过就近查找scrapy.cfg文件来确定是否在项目环境中。
获取可用命令并组装成名称与实例的字典
def _get_commands_dict(settings, inproject):
# 导入commands文件夹下的所有模块,生成{cmd_name: cmd}的字典集合
cmds = _get_commands_from_module('scrapy.commands', inproject)
cmds.update(_get_commands_from_entry_points(inproject))
# 如果用户自定义配置文件中有COMMANDS_MODULE配置,则加载自定义的命令类
cmds_module = settings['COMMANDS_MODULE']
if cmds_module:
cmds.update(_get_commands_from_module(cmds_module, inproject))
return cmds
def _get_commands_from_module(module, inproject):
d = {}
# 找到这个模块下所有的命令类(ScrapyCommand子类)
for cmd in _iter_command_classes(module):
if inproject or not cmd.requires_project:
# 生成{cmd_name: cmd}字典
cmdname = cmd.__module__.split('.')[-1]
d[cmdname] = cmd()
return d
def _iter_command_classes(module_name):
# TODO: add `name` attribute to commands and and merge this function with
# 迭代这个包下的所有模块,找到ScrapyCommand的子类
# scrapy.utils.spider.iter_spider_classes
for module in walk_modules(module_name):
for obj in vars(module).values():
if inspect.isclass(obj) and \
issubclass(obj, ScrapyCommand) and \
obj.__module__ == module.__name__ and \
not obj == ScrapyCommand:
yield obj这个过程主要是,导入commands文件夹下的所有模块,生成{cmd_name: cmd}字典集合,如果用户在配置文件中配置了自定义的命令类,也追加进去。也就是说,自己也可以编写自己的命令类,然后追加到配置文件中,之后就可以使用自己自定义的命令了。
解析执行的命令并找到对应的命令实例
def _pop_command_name(argv):
i = 0
for arg in argv[1:]:
if not arg.startswith('-'):
del argv[i]
return arg
i += 1这个过程就是解析命令行,例如scrapy crawl <spider_name>,解析出crawl,通过上面生成好的命令字典集合,就能找到commands模块下的crawl.py下的Command类 的实例。
scrapy命令实例解析命令行参数
找到对应的命令实例后,调用cmd.process_options方法(例如scrapy/commands/crawl.py):
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return "[options] <spider>"
def short_desc(self):
return "Run a spider"
def add_options(self, parser):
ScrapyCommand.add_options(self, parser)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
parser.add_option("-o", "--output", metavar="FILE",
help="dump scraped items into FILE (use - for stdout)")
parser.add_option("-t", "--output-format", metavar="FORMAT",
help="format to use for dumping items with -o")
def process_options(self, args, opts):
# 首先调用了父类的process_options,解析统一固定的参数
ScrapyCommand.process_options(self, args, opts)
try:
opts.spargs = arglist_to_dict(opts.spargs)
except ValueError:
raise UsageError("Invalid -a value, use -a NAME=VALUE", print_help=False)
if opts.output:
if opts.output == '-':
self.settings.set('FEED_URI', 'stdout:', priority='cmdline')
else:
self.settings.set('FEED_URI', opts.output, priority='cmdline')
feed_exporters = without_none_values(
self.settings.getwithbase('FEED_EXPORTERS'))
valid_output_formats = feed_exporters.keys()
if not opts.output_format:
opts.output_format = os.path.splitext(opts.output)[1].replace(".", "")
if opts.output_format not in valid_output_formats:
raise UsageError("Unrecognized output format '%s', set one"
" using the '-t' switch or as a file extension"
" from the supported list %s" % (opts.output_format,
tuple(valid_output_formats)))
self.settings.set('FEED_FORMAT', opts.output_format, priority='cmdline')
def run(self, args, opts):
if len(args) < 1:
raise UsageError()
elif len(args) > 1:
raise UsageError("running 'scrapy crawl' with more than one spider is no longer supported")
spname = args[0]
self.crawler_process.crawl(spname, **opts.spargs)
self.crawler_process.start()
if self.crawler_process.bootstrap_failed:
self.exitcode = 1这个过程就是解析命令行其余的参数,固定参数解析交给父类处理,例如输出位置等。其余不同的参数由不同的命令类解析。
初始化CrawlerProcess
最后初始化CrawlerProcess实例,然后运行对应命令实例的run方法。
cmd.crawler_process = CrawlerProcess(settings)
_run_print_help(parser, _run_command, cmd, args, opts)如果运行命令是scrapy crawl <spider_name>,则运行的就是commands/crawl.py的run:看上面代码中 run 方法
run方法中调用了CrawlerProcess实例的crawl和start,就这样整个爬虫程序就会运行起来了。
先来看CrawlerProcess初始化:(scrapy/crawl.py)
class CrawlerProcess(CrawlerRunner):
def __init__(self, settings=None, install_root_handler=True):
# 调用父类初始化
super(CrawlerProcess, self).__init__(settings)
# 信号和log初始化
install_shutdown_handlers(self._signal_shutdown)
configure_logging(self.settings, install_root_handler)
log_scrapy_info(self.settings)构造方法中调用了父类CrawlerRunner的构造:
class CrawlerRunner(object):
def __init__(self, settings=None):
if isinstance(settings, dict) or settings is None:
settings = Settings(settings)
self.settings = settings
# 获取爬虫加载器
self.spider_loader = _get_spider_loader(settings)
self._crawlers = set()
self._active = set()
self.bootstrap_failed = False初始化时,调用了_get_spider_loader方法:
def _get_spider_loader(settings):
""" Get SpiderLoader instance from settings """
# 读取配置文件中的SPIDER_MANAGER_CLASS配置项
if settings.get('SPIDER_MANAGER_CLASS'):
warnings.warn(
'SPIDER_MANAGER_CLASS option is deprecated. '
'Please use SPIDER_LOADER_CLASS.',
category=ScrapyDeprecationWarning, stacklevel=2
)
cls_path = settings.get('SPIDER_MANAGER_CLASS',
settings.get('SPIDER_LOADER_CLASS'))
loader_cls = load_object(cls_path)
try:
verifyClass(ISpiderLoader, loader_cls)
except DoesNotImplement:
warnings.warn(
'SPIDER_LOADER_CLASS (previously named SPIDER_MANAGER_CLASS) does '
'not fully implement scrapy.interfaces.ISpiderLoader interface. '
'Please add all missing methods to avoid unexpected runtime errors.',
category=ScrapyDeprecationWarning, stacklevel=2
)
return loader_cls.from_settings(settings.frozencopy())默认配置文件中的spider_loader配置是spiderloader.SpiderLoader:(scrapy/spiderloader.py)
@implementer(ISpiderLoader)
class SpiderLoader(object):
"""
SpiderLoader is a class which locates and loads spiders
in a Scrapy project.
"""
def __init__(self, settings):
# 配置文件获取存放爬虫脚本的路径
self.spider_modules = settings.getlist('SPIDER_MODULES')
self.warn_only = settings.getbool('SPIDER_LOADER_WARN_ONLY')
self._spiders = {}
self._found = defaultdict(list)
# 加载所有爬虫
self._load_all_spiders()
def _check_name_duplicates(self):
dupes = ["\n".join(" {cls} named {name!r} (in {module})".format(
module=mod, cls=cls, name=name)
for (mod, cls) in locations)
for name, locations in self._found.items()
if len(locations)>1]
if dupes:
msg = ("There are several spiders with the same name:\n\n"
"{}\n\n This can cause unexpected behavior.".format(
"\n\n".join(dupes)))
warnings.warn(msg, UserWarning)
def _load_spiders(self, module):
for spcls in iter_spider_classes(module):
self._found[spcls.name].append((module.__name__, spcls.__name__))
self._spiders[spcls.name] = spcls
def _load_all_spiders(self):
# 组装成{spider_name: spider_cls}的字典
for name in self.spider_modules:
try:
for module in walk_modules(name):
self._load_spiders(module)
except ImportError as e:
if self.warn_only:
msg = ("\n{tb}Could not load spiders from module '{modname}'. "
"See above traceback for details.".format(
modname=name, tb=traceback.format_exc()))
warnings.warn(msg, RuntimeWarning)
else:
raise
self._check_name_duplicates()
@classmethod
def from_settings(cls, settings):
return cls(settings)
def load(self, spider_name):
"""
Return the Spider class for the given spider name. If the spider
name is not found, raise a KeyError.
"""
try:
return self._spiders[spider_name]
except KeyError:
raise KeyError("Spider not found: {}".format(spider_name))
def find_by_request(self, request):
"""
Return the list of spider names that can handle the given request.
"""
return [name for name, cls in self._spiders.items()
if cls.handles_request(request)]
def list(self):
"""
Return a list with the names of all spiders available in the project.
"""
return list(self._spiders.keys())爬虫加载器会加载所有的爬虫脚本,最后生成一个{spider_name: spider_cls}的字典。
执行 crawl 和 start 方法
CrawlerProcess初始化完之后,调用crawl方法:
class CrawlerRunner(object):
def __init__(self, settings=None):
if isinstance(settings, dict) or settings is None:
settings = Settings(settings)
self.settings = settings
self.spider_loader = _get_spider_loader(settings)
self._crawlers = set()
self._active = set()
self.bootstrap_failed = False
@property
def spiders(self):
warnings.warn("CrawlerRunner.spiders attribute is renamed to "
"CrawlerRunner.spider_loader.",
category=ScrapyDeprecationWarning, stacklevel=2)
return self.spider_loader
def crawl(self, crawler_or_spidercls, *args, **kwargs):
# 创建crawler
crawler = self.create_crawler(crawler_or_spidercls)
return self._crawl(crawler, *args, **kwargs)
def _crawl(self, crawler, *args, **kwargs):
self.crawlers.add(crawler)
# 调用Crawler的crawl方法
d = crawler.crawl(*args, **kwargs)
self._active.add(d)
def _done(result):
self.crawlers.discard(crawler)
self._active.discard(d)
self.bootstrap_failed |= not getattr(crawler, 'spider', None)
return result
return d.addBoth(_done)
def create_crawler(self, crawler_or_spidercls):
# 如果是字符串,则从spider_loader中加载这个爬虫类
if isinstance(crawler_or_spidercls, Crawler):
return crawler_or_spidercls
# 否则创建Crawler
return self._create_crawler(crawler_or_spidercls)
def _create_crawler(self, spidercls):
if isinstance(spidercls, six.string_types):
spidercls = self.spider_loader.load(spidercls)
return Crawler(spidercls, self.settings)
def stop(self):
"""
Stops simultaneously all the crawling jobs taking place.
Returns a deferred that is fired when they all have ended.
"""
return defer.DeferredList([c.stop() for c in list(self.crawlers)])
@defer.inlineCallbacks
def join(self):
"""
join()
Returns a deferred that is fired when all managed :attr:`crawlers` have
completed their executions.
"""
while self._active:
yield defer.DeferredList(self._active)这个过程会创建Cralwer实例,然后调用它的crawl方法:(scrapy/crawl.py 中 class Crawler )
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
# 到现在,才是实例化一个爬虫实例
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎
self.engine = self._create_engine()
# 调用爬虫类的start_requests方法
start_requests = iter(self.spider.start_requests())
# 执行引擎的open_spider,并传入爬虫实例和初始请求
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
# In Python 2 reraising an exception after yield discards
# the original traceback (see https://bugs.python.org/issue7563),
# so sys.exc_info() workaround is used.
# This workaround also works in Python 3, but it is not needed,
# and it is slower, so in Python 3 we use native `raise`.
if six.PY2:
exc_info = sys.exc_info()
self.crawling = False
if self.engine is not None:
yield self.engine.close()
if six.PY2:
six.reraise(*exc_info)
raise最后调用start方法:
def start(self, stop_after_crawl=True):
"""
This method starts a Twisted `reactor`_, adjusts its pool size to
:setting:`REACTOR_THREADPOOL_MAXSIZE`, and installs a DNS cache based
on :setting:`DNSCACHE_ENABLED` and :setting:`DNSCACHE_SIZE`.
If `stop_after_crawl` is True, the reactor will be stopped after all
crawlers have finished, using :meth:`join`.
:param boolean stop_after_crawl: stop or not the reactor when all
crawlers have finished
"""
if stop_after_crawl:
d = self.join()
# Don't start the reactor if the deferreds are already fired
if d.called:
return
d.addBoth(self._stop_reactor)
reactor.installResolver(self._get_dns_resolver())
# 配置reactor的池子大小(可修改REACTOR_THREADPOOL_MAXSIZE调整)
tp = reactor.getThreadPool()
tp.adjustPoolsize(maxthreads=self.settings.getint('REACTOR_THREADPOOL_MAXSIZE'))
reactor.addSystemEventTrigger('before', 'shutdown', self.stop)
# 开始执行
reactor.run(installSignalHandlers=False) # blocking callreactor 是个什么东西呢?它是 Twisted 模块的 事件管理器,只要把需要执行的事件方法注册到 reactor 中,然后调用它的 run 方法,它就会帮你执行注册好的事件方法,如果遇到 网络IO 等待,它会自动帮你切换可执行的事件方法,非常高效。
大家不用在意 reactor 是如何工作的,你可以把它想象成一个线程池,只是采用注册回调的方式来执行事件。
到这里,爬虫的之后调度逻辑就交由引擎ExecuteEngine处理了。
在每次执行 scrapy 命令 时,主要经过环境、配置初始化,加载命令类 和 爬虫模块,最终实例化执行引擎,交给引擎调度处理的流程,下篇文章会讲解执行引擎是如何调度和管理各个组件工作的。