用python处理csv格式文件
在各种平台上获取数据时,我们常常获得的是csv格式的文件。csv格式是一种逗号分隔值的文件格式,它并不是非常reader-friendly。所幸,python标准库中的csv模块可以帮助我们轻松处理csv格式文件。下面将以分析我国2010-2019年gdp为例简单介绍用python处理csv格式文件的过程。
数据准备
本例中使用的csv格式数据可以在国家统计局官网上获得,有兴趣的小伙伴可以下载下来,实战一下。数据源分析csv文件头
为了在python中处理csv文件,我们需要导入csv模块,并创建一个阅读器(reader)对象。具体代码如下。import csvdefmain(): filename='GDP_data.csv'withopen(filename)as f: reader= csv.reader(f)# 创建一个与该文件相关的阅读器next(reader)next(reader)# 跳过表头 header_row=next(reader)# 用next()读取一行print(header_row)执行main()函数,就可以看到

拆分文件头
有时候文件头中的条目较多,一个一个核对非常麻烦,这时候就可以用enumerate函数将文件头拆分成索引序列
# 拆分文件头for index, column_headerinenumerate(header_row):print(index, column_header)执行代码后,就可以轻松看到每个条目的指标对应。

提取并读取数据
下面考察国内生产总值和时间的关系,在前一步中已经知道,国内生产总值在第二列,时间在第零列。由于数据集末尾有注释项,并不是我们关心的数据,所以这里用到了正则表达式来匹配我们关心的数据。详见代码(注意使用正则表达式需要导入re模块)。
# 从文件中获取时间和国民总收入 GDP=[] year=[]for rowin reader:# 利用正则表达式排除末尾注释段,只提取需要的数据if re.match(r'\d{4}', row[0])isNone:break year.append(row[0]) GDP.append(row[2])print(year)print(GDP)执行代码就可以看到我们已经提取出了需要的数据。

将字符串转换为数字并绘图
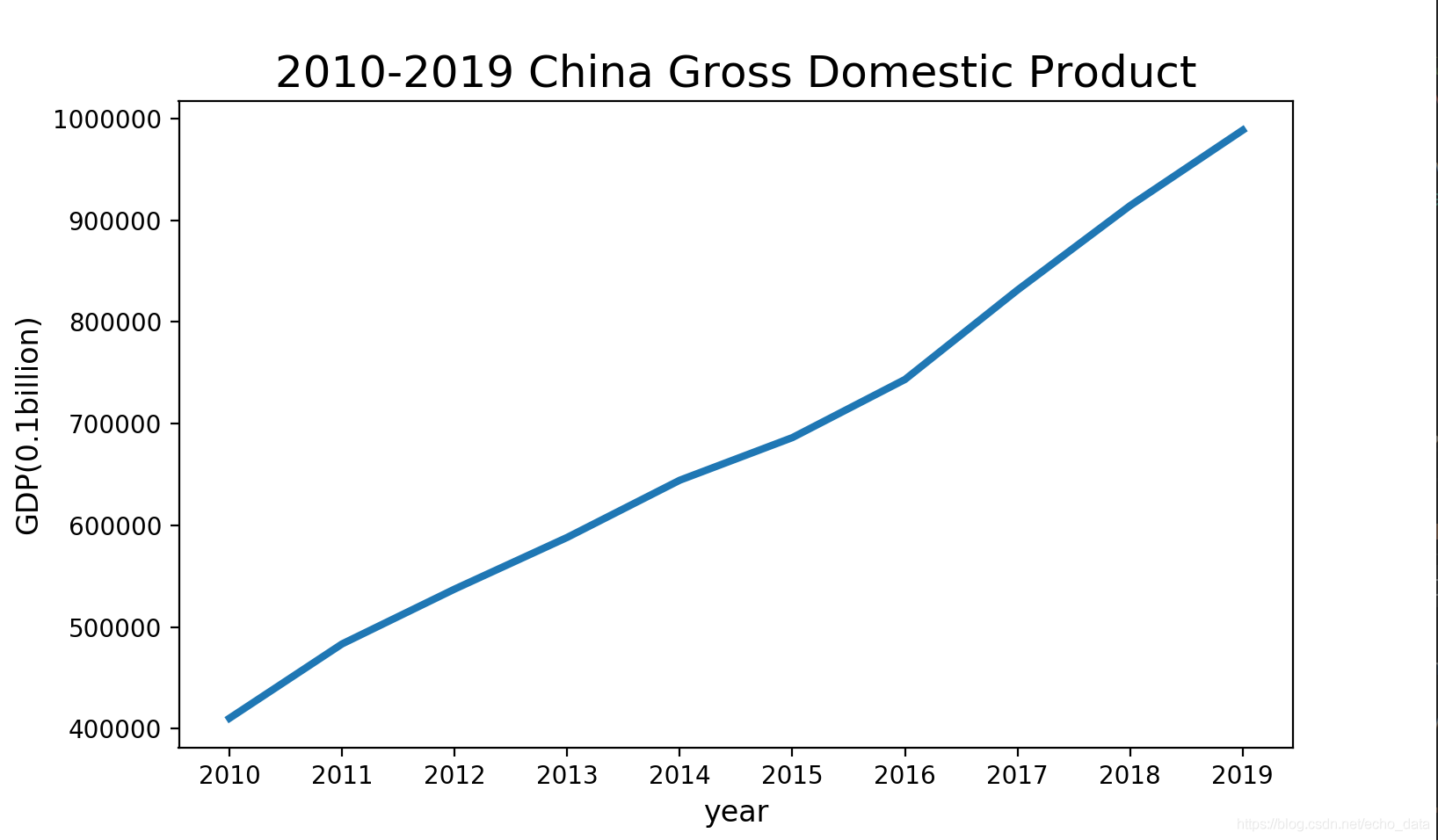
利用float(row[2])可直接实现类型转换,完成转换后我们接著matplotlib模块来画图(如果缺少此模块,需先用pip安装)。
year.reverse() GDP.reverse()# 用matplotlib画图 plt.plot(year, GDP, linewidth=3)# 设置图形格式 plt.title('2010-2019 China Gross Domestic Product', fontsize=18) plt.xlabel('year', fontsize=12) plt.ylabel('GDP(0.1billion)', fontsize=12) plt.show()效果如下:
进一步丰富图形内容
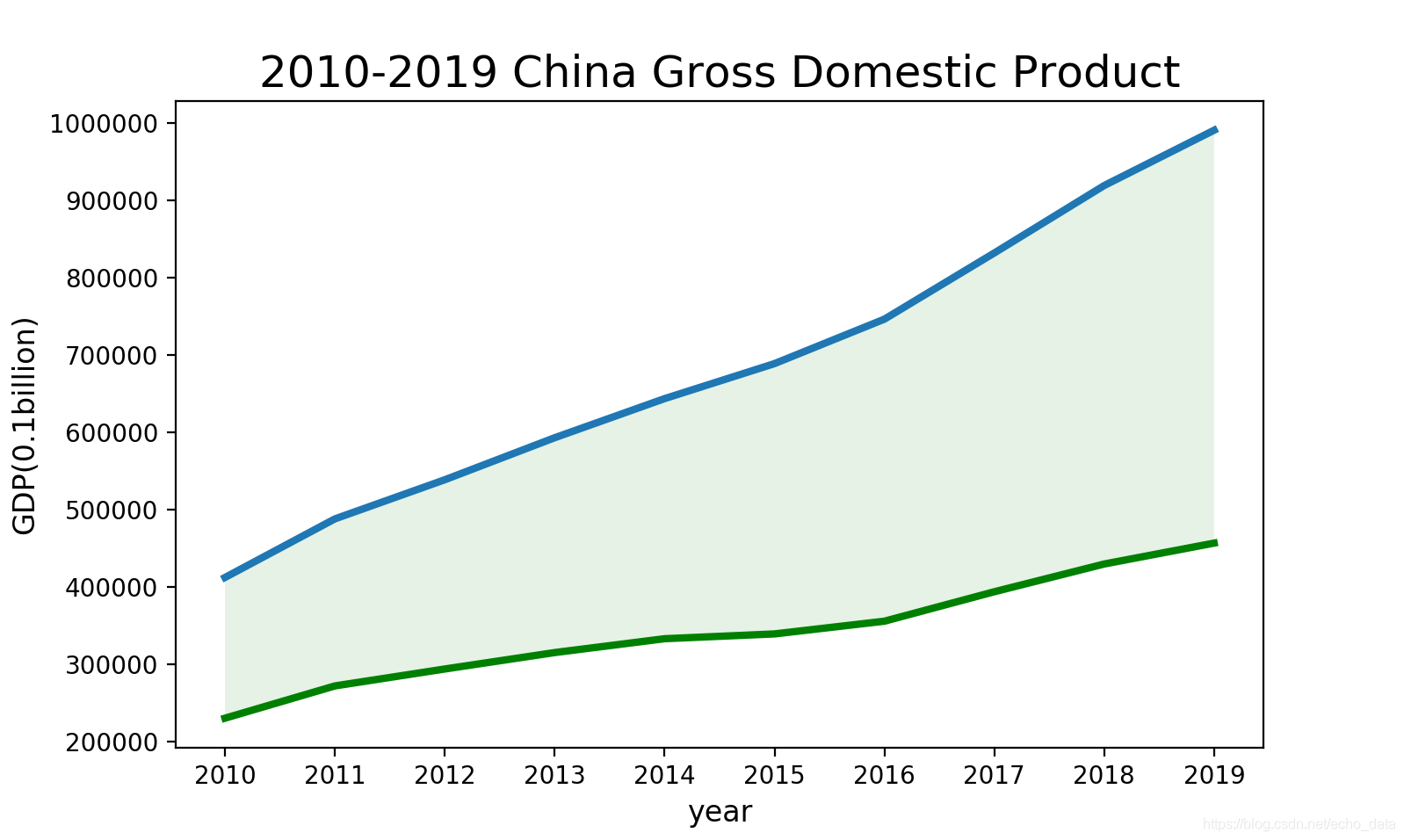
如果我们希望突出第三产业增加值对gdp的贡献,可以做进一步的处理。
# 用matplotlib画图 plt.plot(year, GDP, linewidth=3) plt.plot(year, first_second_industry, c='green', linewidth=3)# 对第三产业增加值的部分着色突出(参数alpha控制透明度) plt.fill_between(year, GDP, first_second_industry, facecolor='green', alpha=0.1)# 设置图形格式 plt.title('2010-2019 China Gross Domestic Product', fontsize=18) plt.xlabel('year', fontsize=12) plt.ylabel('GDP(0.1billion)', fontsize=12) plt.show()这样我们就可以得到一张非常好看且含义鲜明的图表了。