目录
第一步:数据导入
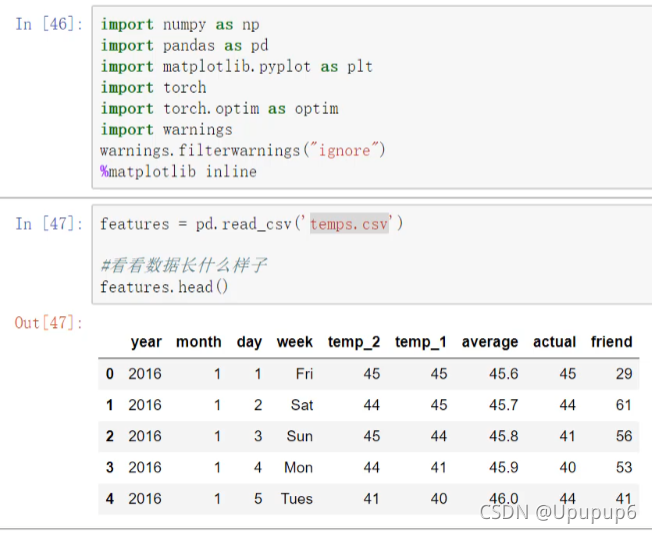

第二步:将时间转换成标准格式(比如datatime格式)
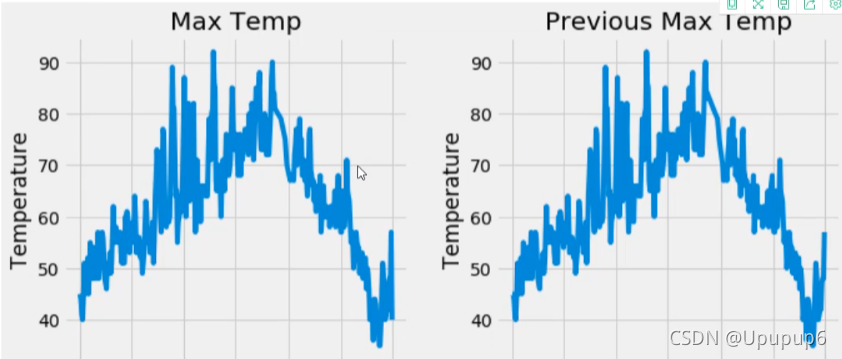
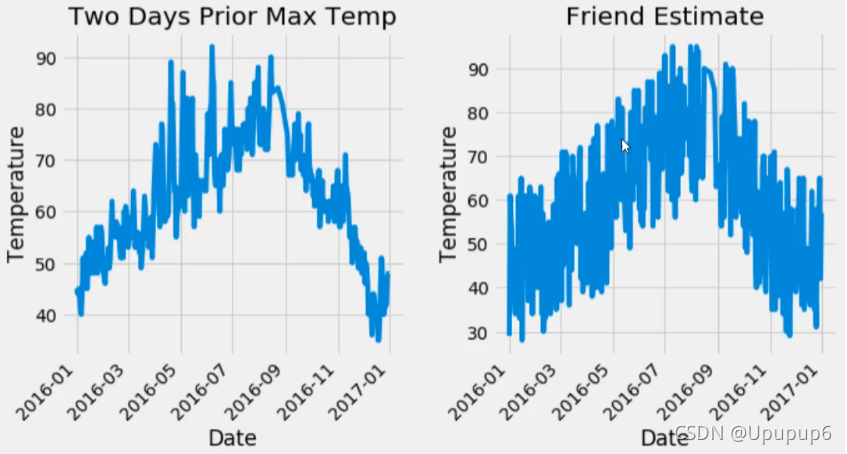
第三步: 展示数据:(画了4个子图)

第四步:做独热编码
Q1:为什么做独热编码?
A1:因为数据中其中有一列比较特殊,其他列都是数值,但是week列是一些字符串,我们首先将字符串转换成一种数值的形式,比较简单的方法就是做一个独热编码,在pandas当中可以使用pd.get_dummies()不用把这个特征传进来,我直接features,因为features是我们传进来的一个数据他会自动的帮我们做判断,判断这个数据中哪一列是字符串,我自动对他做独热(one-hot)编码。
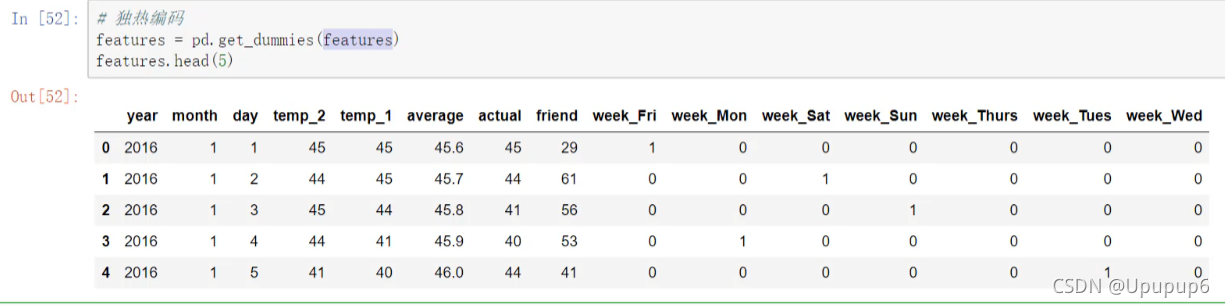
如上做完one-hot编码之后,week这一列就没有了,数据里边做了一个one-hot encoding,对我们当前需要的列做了一个额外的编码,并且还再次把他们拼接到我们的数据当中。
PS:这就是数据处理的第一步,先把数据都转换成数值的形式。
第五步:指定输入与输出
因为x和y都混在一起了,一会建模的时候我得知道我的输入是什么,我的输出是什么,所以需要指定好。
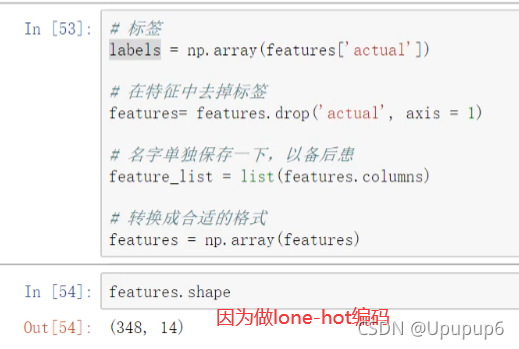
PS:上述代码中从features中剔除掉(.drop)标签actual,剩下的就是x了。
第六步:对数据做一个标准化
因为数据中有些数值比较大,有些数值比较小(做完标准化之后结果收敛的速度会更快一些,收敛的损失值相对于来说会更小一点)。所以做一个标准化预处理再用torch进行建模。
这里使用的是sklearn中的预处理模块,在预处理模块中有一个标准化的操作:
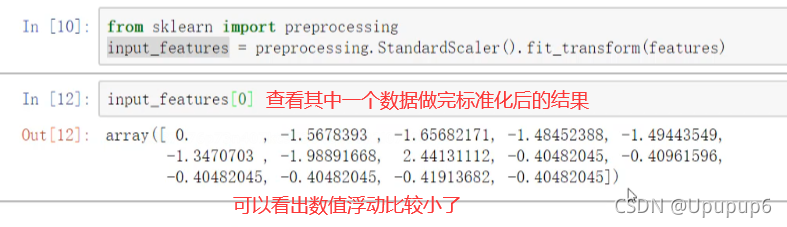 此时数据是ndarray格式。
此时数据是ndarray格式。
第七步:用torch来构建一个神经网络模型
构建网络模型有两种方法:第一种是比较麻烦的,一步步的去写;第二种简单一些。
第一种:基于Pytorch来构建神经网络模型。
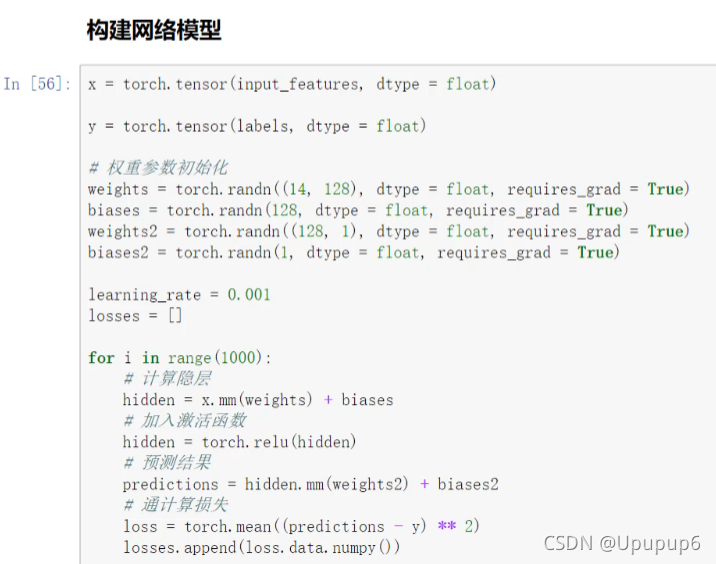
(1)首先将上述的ndarray格式的数据转换成tensor格式。
(2)权重参数初始化:一般使用随机的标准的正态分布比较合适。
- 准备w1和b1:
初始化w1:输入是[348,14],要把现在的14个输入特征,转换成128个隐层特征。w就是[14,128]。
初始化偏置参数b1:对于w1来说来说我得到了128个神经元特征,那b1就是微调,不是对整体做一个微调,而是对每一个特征都做一个微调。PS:偏置参数的个数永远是跟得到的特征结果个数是一致的。
第一个隐层得到了128个特征,我输出结果是一个回归任务,要得到一个实际的值,所以128肯定不行,我得再来个w2;
- 准备w2和b2:
初始化w2[128,1]前边连的是你中间的特征128个,我要把这128个特征转化成一个值,回归任务是一个值,所以说w2的矩阵维度就是128x1;
初始化偏置参数b2=1,因为最终结果得到的是一个值,所以b2为1,是对最终的结果进行一个微调。
PS:注意权重参数在接下来迭代过程当中要计算他的梯度,所以在初始化过程中,都带了参数requires_grad=True,都是需要计算梯度的。
(3)初始化学习率。
(4)把上述初始化的参数由前到后给它串起来。
- 计算第一个隐层结果:.mm就是矩阵乘法。
- 将结果经过激活函数:.relu激活函数。
- 计算最后一层的结果。
- ------------------至此前向传播计算出来了--------------------------
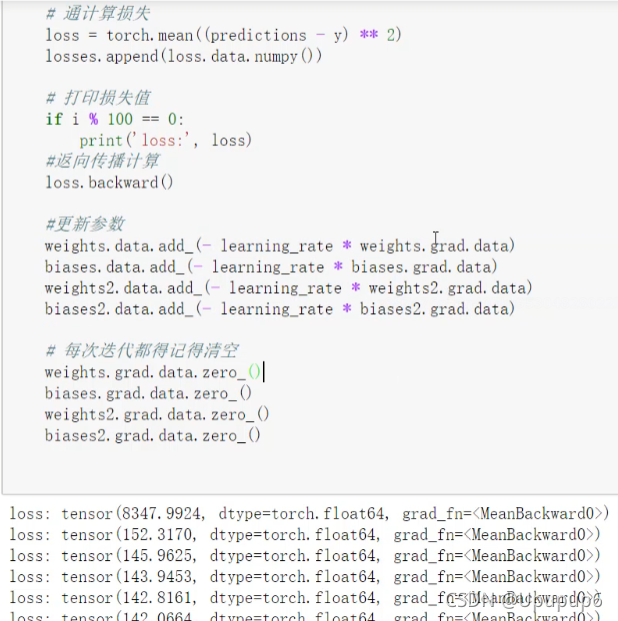
- 计算损失。
- 基于损失执行反向传播(计算梯度)、并更新w1、b1和w2、b2;(负的学习率表示我沿着梯度的反方向,把学习率乘过来,把梯度乘过来就完事了)PS:更新完一次梯度时,记得清空,要不然下次会累加在一起的。
第二种:更简单的构建网络模型
 retain_graph=True表示接下来要不要重复的执行这个cell的代码,指定为True,重复执行的话他不会报错。
retain_graph=True表示接下来要不要重复的执行这个cell的代码,指定为True,重复执行的话他不会报错。
指定输入的样本数量;
隐层神经元的个数;
输出的结果;
加上batch_size;(加上batch_size之后,之前训练的时候是把数据全部读入进去,相当于批量梯度下降,这里我们不做批量梯度下降,使用mini_batch,指定一个batch)
构建网络模型;(之前构建模型是一步步写的wx+b,这样比较麻烦)
第一步:先把序列写好 ;按照torch.nn模块下序列去写。
第一层指定好它的输入与输出(hidden_size得到多少个隐层的神经元),中间加上激活函数;
第二层再连一个全连接层nn.Linear(hidden_size,output_size)。第一个参数表示写好前边连什么,第二个参数表示得到什么结果。
所以这样直接使用touch.nn模块下的序列结构,可以把这个网络直接的定义出来(这里按照两层全连接的模块去写,后续可以加卷积加池化等都可以torch.nn模块下你能想到的层别人都给你写好了,直接调用就行)。
第二步:损失函数直接调用现成的包。
第三步:把优化器拿进来。(之前是做一个梯度下降,每一次自己计算梯度,自己更新,自己再置0,这样比较麻烦;简单方法使用torch当中的优化器,优化器里边有挺多的,这里使用SGD梯度下降也行用Adm也行,Adm用的更多一些,他可以动态的去调整学习率,学习率一开始可能会比较大,他会加入一个衰减函数,让学习率随着迭代进行慢慢变小,所以这个应该是更合理一些的)
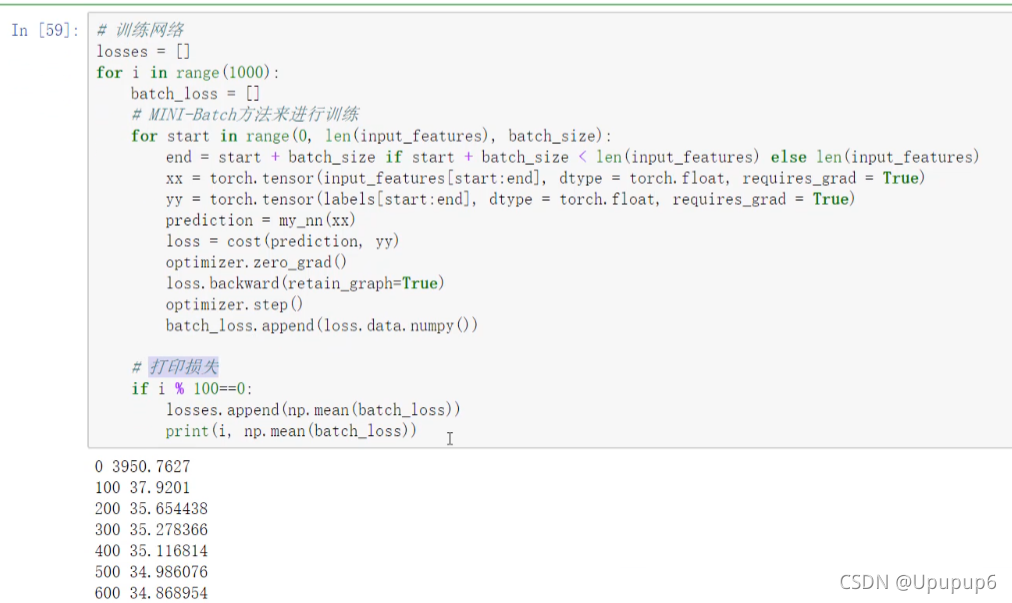
第四步:指定玩优化器之后开始训练网络。(训练网络的方法其实和之前是一样的,写一个循环,这里多做了一步,这里不是取全部的数据了,而是取其中部分的数据,在这里torch.tensor当中在构造它的输入数据的时候,这里传进来两个索引,一个是start索引,一个是end索引,表示我从原始数据当中一步步的每一次取16个数据,因为设置了batch=16,所以每次会取16个这样的x和y;接下来预测一个结果prediction,就是走一个前向传播,my_nn(xx)里边的xx就是我输入的一个batch的数据,然后刚才在定义序列的时候给他起的名字叫做my_nn,然后要得到一个结果你只需要在这个my_nn当中把实际的x给传进去,相当于这一块x来了之后,先走my_nn中的第一个torch.nn.Linear(),再走第二个torch.nn.Sigmoid(),再走第三个torch.nn.Linear()按照这个顺序得到一个输出结果,这就完事了;所以预测值比较简单,不需要一步步去写他是怎么计算的,只需要把它传入到我们刚才定义好的序列模块当中就可以了;然后计算损失值使用定义的cost方法MSELoss;然后做优化,优化过程中每次迭代一次要对梯度进行清0的操作optimizer.zero_grad()(这一步放到后边也行),然后进行一次反向传播,接下来optimizer.step()就是说我们要不要去做一个更新,.step相当于把前边的所有的更新操作放入到这一个函数当中了,直接调用就可以了;接下来为了一会把这个损失打印出来我把这个损失batch_loss给他读进来就完事了。之后就是打印损失)这一步对应上图中的第二个图。
第八步:预测结果

拿一个x,转化为tensor的格式,传到网络当中,其实传入到网络就是相当于走了一次前向传播,会得到实际的预测值,把实际结果的预测值拿到手就可以了,.data.numpy()相当于转化成array数组的形式(因为下边要使用myplot画图,不转化成numpy的格式的话tensor的格式画不了)。
第九步:画图
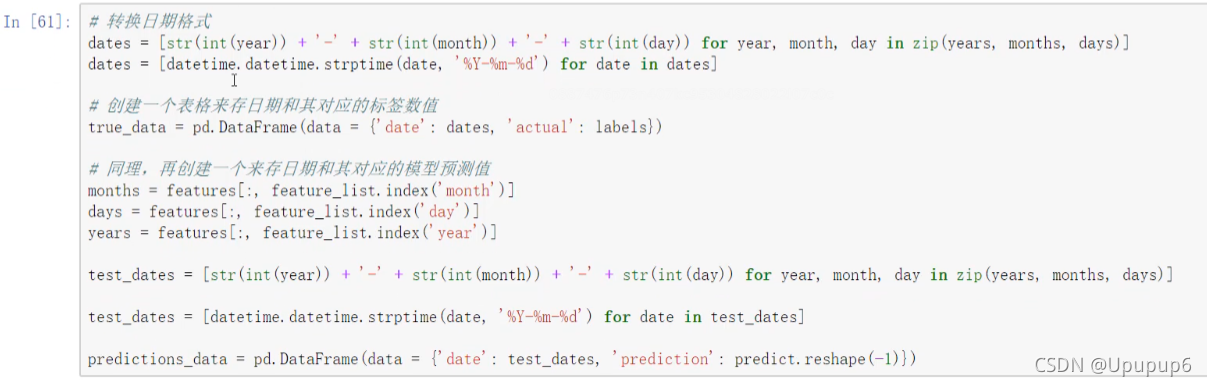

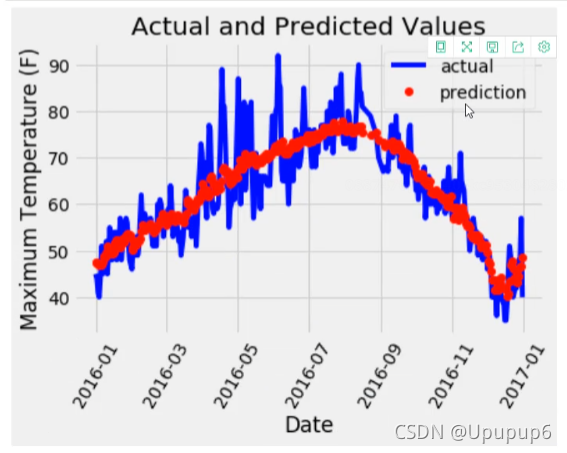
X轴定义为日期,所以先把日期都拿到手转化成标准的格式dates;
拿预测的结果值predictions_data(其中predict要reshape一下因为我们要的是一列的格式,不能是一个矩阵的格式。并要构建一个DataFrame,因为基于DataFrame画图比较简单,直接传进去就得了。)