*德地图笔试题分享
题1):
实现单词翻转。例如:I am a student ---->student a am I
算法:这个很简单,就是列表与字符串的转换,然后切片反转。
s = "I am a student"
new_s = " ".join(s.split()[::-1])
print(new_s)题2):
本地存在文件access.log,内部格式为:
//a.log
http://www.baidu.com
http://www.taobao.com
http://www.qq.com
http://www.taobao.com
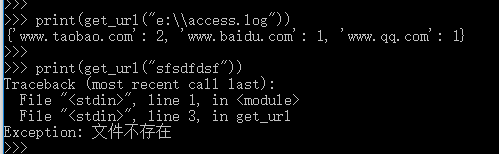
获取所有域名,去重后按出现次数由大到小排序,并输出次数,如:
www.taobao.com :2
www.baidu.com : 1
www.qq.com : 1
算法:
1、读取文件;
2、匹配文件内容,提取域名,这个方法很多,可以使用字符串的切割,也可以使用正则等等;
3、统计并排序。
翻译成代码如下:
import os , re
def get_url(file_path):
if not os.path.exists(file_path):
raise Exception("文件不存在")
try:
# 先默认以gbk格式读取文件
with open(file_path) as fp:
content = fp.readlines()
except:
# gbk读取出错时,再尝试以utf8格式读取
with open(file_path,encoding="utf-8") as fp:
content = fp.readlines()
d = {}
for line in content:
# 利用正则匹配URL的全路径
match_url = re.match(r"http://(.*)",line.strip())
# print(match_url)
# 假如匹配到了值,进入如下程序入口
if match_url:
# 提取全路径中的域名
url = match_url.group(1)
# print(url)
# 统计数量并生成字典
if url in d:
d[url] +=1
else:
d[url] = 1
# print(d)
# 对字典按value值排序,并生成新字典
new_d =dict(sorted(d.items(),key = lambda x:x[1],reverse=True))
return new_d
if __name__ =="__main__":
print(get_url("e:\\access.log"))
print(get_url("sfsdfdsf"))返回结果: