简介:
K8S是当前主流的容器编排系统, 服务编排系统要想实现服务的自动化部署和运行离不开容器编排系统.
容器目的是解决服务器的异构问题, 解决了部署的时候无需在考虑底层系统环境是否能够满足服务的需要. 但是单独的容器并没有生产的价值, 因为他只是提供了底层应用的托管程序, 并没有处理多个容器容器投入生产的问题, 而容器的编排则是处理多个容器投入生产的痛点问题
容器编排系统是在大范围,动态环境中管理容器生命周期的工具.
容器编排系统价值
- 容器的提供和部署
- 容器的冗余和可用性, 容器挂掉有自动恢复机制, 或者故障转移
- 应用规模的自动伸缩, 能依据实例的需求自动实现资源的扩容和释放. 提高资源利用率
- 容器资源紧缺的时候能够在用户 毫无感知的情况下资把容器迁移到其他宿主机的节点
- 容器之间实现资源分配
- 能够实现将容器的服务暴露到外部, 实现在外部进行访问
- 容器的负载均衡, 容器的服务注册和发现
- 宿主机和容器的健康状态检测
- 将应用之间的关系配置到容器
K8S是当前最主流的容器编排系统没有之一. (docker swarm被安在地上摩擦). K8S 是Google使用 Go语言按照自己十分成熟的容器编排系统 Borg 的思维重新做了一遍.
最后 K8S 是一个能够实现自动部署,伸缩并且实现应用容器跨主机集群和提供容器基础设施的开源平台
K8S架构
Master和Node
K8S中主机(可以是物理机或者虚拟机)主要分为两种 Master和Node
- Node 是运行具体容器的主机,负责提供后具体的服务,并且本身具有自我修复能力 --Data Plane 数据平面
- Master 负责管理Node, 控制Node 具体运行什么容器, 同时还承担外部数据访问的角色-- Control Plane 控制层面
Master和Node都有冗余但是冗余的, 但是目的不同
在容器集群运行中正在运行的Master(ETCD除外, 是一个强一致的分布式存储) 只能有一个,因为只能由一个Master去指挥它下面的多个Node, 所以Master的 冗余用于做灾备, 当Master挂掉, 会有另一个冗余的Master启用,替代原来的Master工作,所以生产环境应该有3个以上Master
集群中的Node的冗余是用于做负载均衡的, 多个Node需要同时工作负责不同的模块和任务, 其中某个Node万一挂掉, 这个Node的任务被分配到其他Node再次运行起来
K8S主体架构
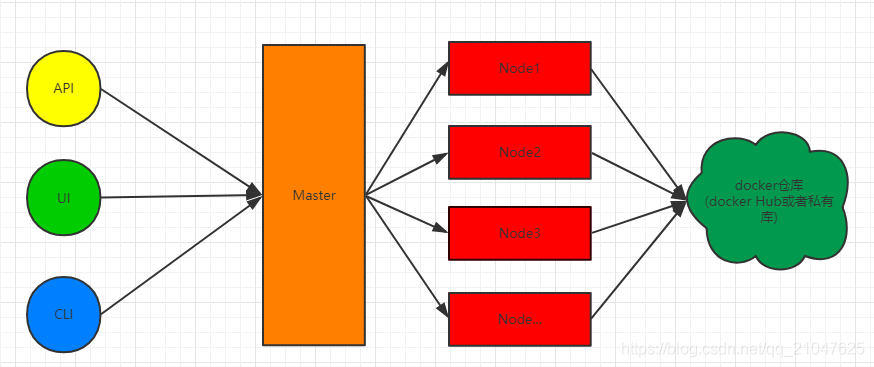
用户可以通过 API接口. UI界面和命令行来访问k8S 的Master, 之后Master依据接収的请求对Node上面的容器做新增,更新或者删除的操作, 同时容器的镜像又依赖于镜像仓库, 需要从镜像仓库拉取所需的镜像, 同时需要将自定义的镜像保存到镜像仓库供容器来使用, 镜像仓库可以考虑 Docker Hub或者搭建私有仓库, 由于Docker Hub 需要公网链接, 所以一般建议搭建私有仓库
Master详解.
Master节点是集群的控制节点,负责整个集群的管理和控制, 基本上所有的控制指令都是发给Master的, 并且他来负责调度Node来具体执行命令, 通常生产环境Master都是部署在单独的服务器, 建议使用3台以上的奇数服务器做冗余, 因为'首脑' 宕机整个集群都会崩溃.
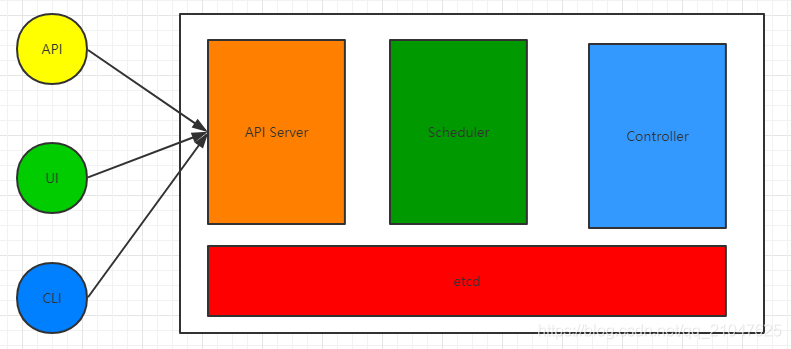
Mater由四个逻辑组件组成, 他们分别由四个独立的守护线程, API Server, Scheduler和Controller是K8S自己做的,etcd则是使用 Core OS的成果
- etcd:用户保存应用程序配置信息的守护进程,是一个k-v存储系统,存储内容为用用户发出的API请求中容器的具体要求, 是一个强一致性的
- API Server: 是K8S开放给用户的唯一入口,接受用户的指令.同时对指令进行规范检查, 将合乎规范的话将其放入etcd中
- Scheduler:是作为调度器 .负责的内容是寻找要部署的容器的最佳Node. 主从模式, 只能有一个正在执行的服务
- Controller: 是作为控制器, K8S提供的API是声明式API. 要运行一个redis容器, 只需要声明要运行一个redis容器即可, 具体的镜像来源以及挂掉后重启等等都有控制器完成. 控制器负责用户指令的具体运行以及保证资源运行一直符合用户的需求, 作为Master的大脑. 也只能有一个正在执行的服务
- Controller Loop 使用轮询的方式保证每个容器的运行正常, 当某个资源不可用, 会尝试重启, 要是还不行,会尝试初始化资源,比如尝试把容器铲掉,拉取镜像重启运行
各个组件关系如下
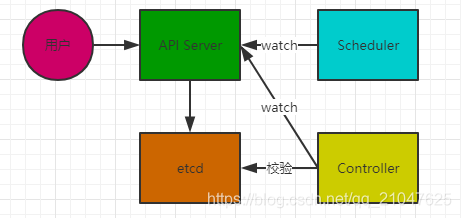
用户发起一个对容器的操作请求, API Server接受到之后会首先对用户发送的指令进行验证, 没有问题后会把指令存储到etcd. 同时Scheduler和Controller分别监听API Server请求验证成功后如果是新建容器, Scheduler会寻找最合适的Node用于运行容器, 而Controller通过监听获得指令之后会去完成指令的要求, 完成后会以轮询的方式校验资源(主要是容器)的状态和存储来etcd里面的指令要求的是否一致. 不一致的话进行重新部署资源(重启或者重新运行镜像)
Node
Node节点是作为K8S中的工作负载节点, Node节点接収Master节点分配的一些任务.同时当前Node节点
Node的关键组件
kubelet: 负责对pod(POD是一组 )对应容器的创建,启停等一系列的任务, kubelet时刻watch着Mater中的API Server中的资源变动, 当有和自己相关的任务的时候就会调用Docker执行具体的任务
kube-proxy: 用于实现 K8S Service(需要提供的服务) 的通信和负载均衡
Docker Engin: docker引擎, 负责Node于和容器有关的操作, K8S原生支持Docker作为容器引擎, 如果要使用其他容器引擎则需要使用对应接口集成
Pod : K8S不是直接运行的容器,而是操作Pod, 把Pod作为原子单元管理,一个Pod里面可能会运行多个容器, Pod里面运行的多个容器被捆绑在一起被统一调度不可分割. 一个Pod的所有容器只能同时运行在一个Node 上
结构图如下
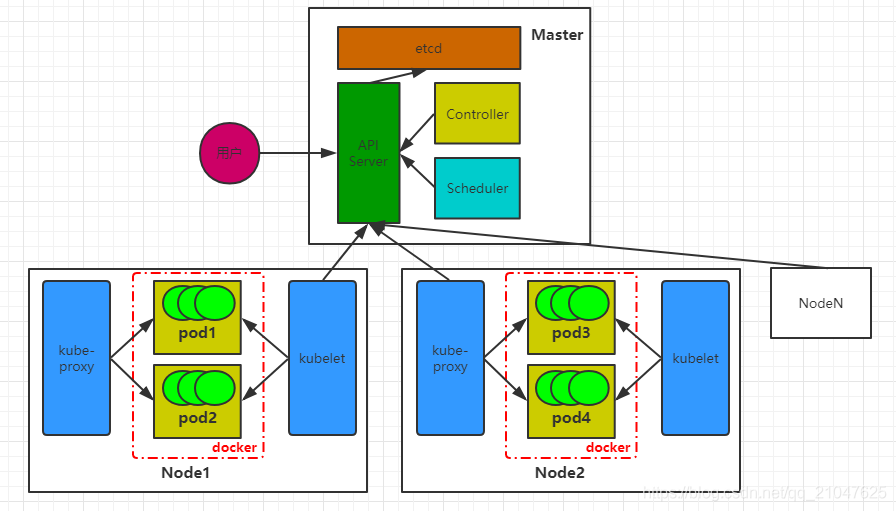
当用户发起一个创建Pod的请求,首先Pod的信息会被存储到 etcd, 随后Master调度器会分析最适合运行这个Pod的Node, 并将信息存储到etcd, 这个时候这个Node的kubelet在Master的API Server 上面 watch到自己有事干了, 就会调用docker引擎把这一组相关的容器启动起来.
这个时候Pod就运行起来了.
除此之外Node还会向Master汇报Pod的运行状况, Master中的控制器汇报运行状况和 etcd中存储的Pod的信息对比, 看看是不是期望的运行状况, 不是的话重启Pod的容器, 重启不行就拉群镜像重启运行.
在Node宕机的时候, Master还会吧这个Node上面的所有Pod通过执行调度器重新寻找适合运行的Node, 重启运行 Pod所包含的容器.
Pod
Pod是K8S里面操作容器的基本单元,是被K8S统一调度的, Pod一般是一组联系紧密的容器.
Pod都有一个特殊的Pause容器用于代表真个Pod的状态, Paus容器的镜像是来源于K8s的平台
结构如下
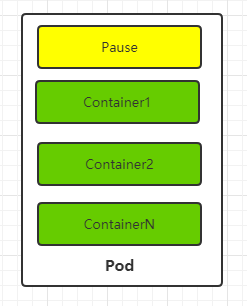
Pod主要要解决的问题有两个, 通常情况下一组容器的关联比较紧密, 可以看做一个在整体, 但是在管理上就出现了麻烦, 这一组业务容器无法进行统一的管理, 比如要求统一的运行启动部署, 引入Pod概念直接对Pod这组容器进行操作就更加简单, 还有运行状态的判断, 在这一组容器的运行的时候, 没有Pod就不能很好的判断整体的运行状态(一个容器挂掉算挂掉还是所有挂掉算挂掉,还是按比例), 引入Pod后, 用Pod的Pause容器状态代表整个Pod的状态, 当Pod挂掉, 重启pod包含的所有容器.
Pod运行的容器通常联系比较傲紧密, Pod的多个容器可以共享Pod中Pause容器的IP还有Pause容器挂载的 Volume, 这样就简化和业务容器之间的配置. 很简单的解决了容器的通信和文件共享文件问题.
同时K8S为每个Pod分配了了指定的唯一IP, 称为 Pod IP, Pod里面的容器共享这这个IP. 至于多个Pod之间跨主机的通信就要借助于虚拟二层网络, 例如Open vSwitch等等. 类似于docker使用Open vSwitch跨主机通信.