一、名词解释
Analysis:文本分析是把全文本转换一系列单词(trem/token)的过程,也叫分词
Analysis是通过Analyzer来实现的
- 可以使用es内置分析器,或按需定制化分析器
除了在数据写入时转换词条,匹配query语句时也需要用相同的分析器对查询语句进行分析
- 可以使用es内置分析器,或按需定制化分析器
分词器时专门处理分词的组件,Analyzer又三部分组成
- Character Filters(针对原始文本处理,例如去除HTML)
- Tokenizer:按照规则切分单词
- Token Filter:将切分的单词进行加工,小写,删除stopwords,增加同义词
二、默认分词器
1、_analyzer API的使用
直接指定Analyzer进行测试
GET _analyze{"analyzer":"standard","text":"demo analyzer"}指定索引的字段进行测试
POST index_demo/_analyze{"field":"title","text":"demo analyzer"}自定义分词器进行测试
POST _analyze{"tokenizer":"standard","filter":["lowercase"],"text":"demo analyzer"}2、Standard Analyzer - 默认分词器,按词切分,小写处理
Tokenizer:Standard
Token Filters:Standard、Lower Case、Stop(默认关闭)
GET _analyze{"analyzer":"standard","text":"Learning a new course vue_4"}按照空格的方式拆分,转小写,忽略停用词
3、Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
Token Filters:Lower Case
GET _analyze{"analyzer":"simple","text":"Learning a new course vue_4."}非字母的方式切分,删除非字母,转小写
4、Stop Analyzer – 小写处理,停用词过滤(the,a,is)
Tokenizer:Lower Case
Token Filters:Stop
{"analyzer":"stop","text":"Learning a new course vue_4."}相比Simple Analyzer多了stop filter,会把the、a、is等修饰语 和标点符号数字去掉
分词小写处理,自动删除停用词,如果符号隔离的2个单词会分成2个单词
5、Whitespace Analyzer – 按照空格切分,不转小写
Tokenizer:Whitespace
GET _analyze{"analyzer":"whitespace","text":"Learning a new course vue_4."}按空格的方式切分
6、Keyword Analyzer – 不分词,直接将输入当作输出
Tokenizer:Keyword
GET _analyze{"analyzer":"keyword","text":"Learning a new course vue_4."}不分词,直接将输入当作输出
7、Patter Analyzer – 正则表达式,默认 \W+ (非字符分隔)
Tokenizer:Patter
Token Filters:Lower Case、Stop
GET _analyze{"analyzer":"pattern","text":"Learning a new course vue_4."}通过正则表达式的方式分词,默认按照非字母的符号拆分(不拆分"_"),去除标点符号,转小写
8、Language – 提供了30多种常见语言的分词器
支持不同国家的语言分词
arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english, estonian, finnish, french, galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, persian, portuguese, romanian, russian, sorani, spanish, swedish, turkish, thai.
english分词举例
GET _analyze{"analyzer":"english","text":"Learning a new course vue_4."}词转换,stop停用词
三、中文分词ik分词器
中文分词相对较难,因为需要根据不同的词意分词,不能按照一个字分词和一个词分词,不同的上下文中有不同的表述
ik分词优点:
- 支持自定义词库
- 支持热更新
- 支持停用词
1.进入官网下载地址
2.找到对应版本的插件,下载.zip文件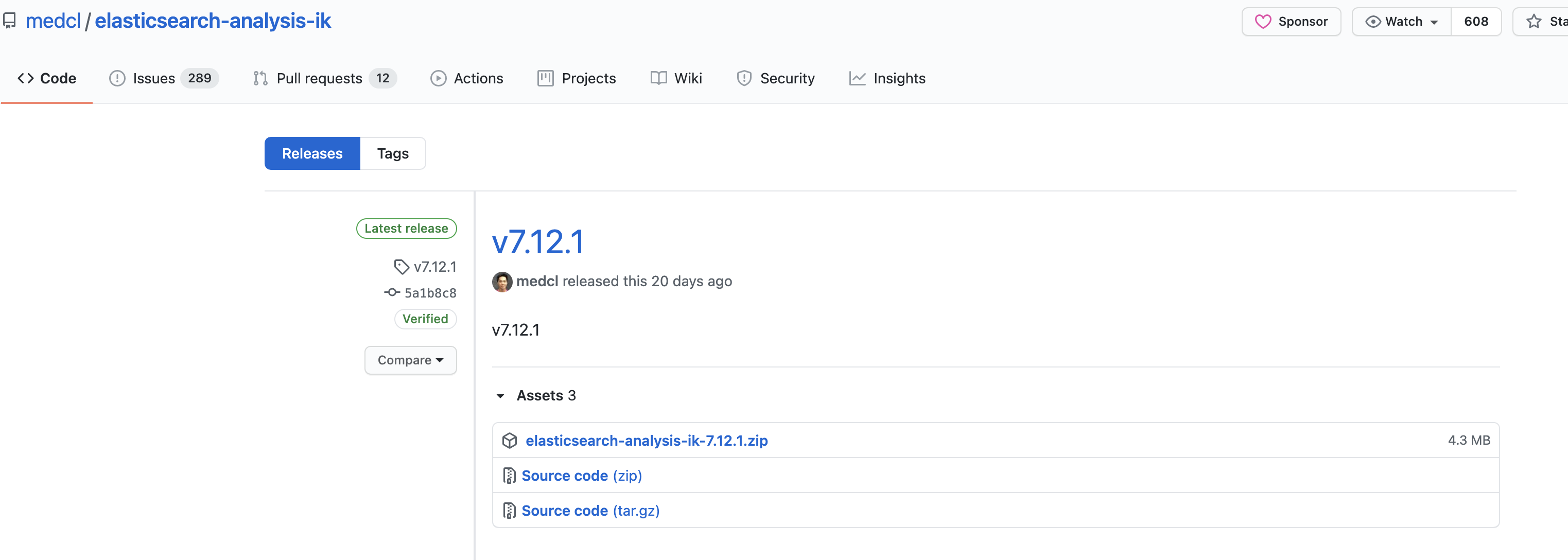
3.在es的plugins下创建一个目录例如“ik”,必须创建否则报错,如下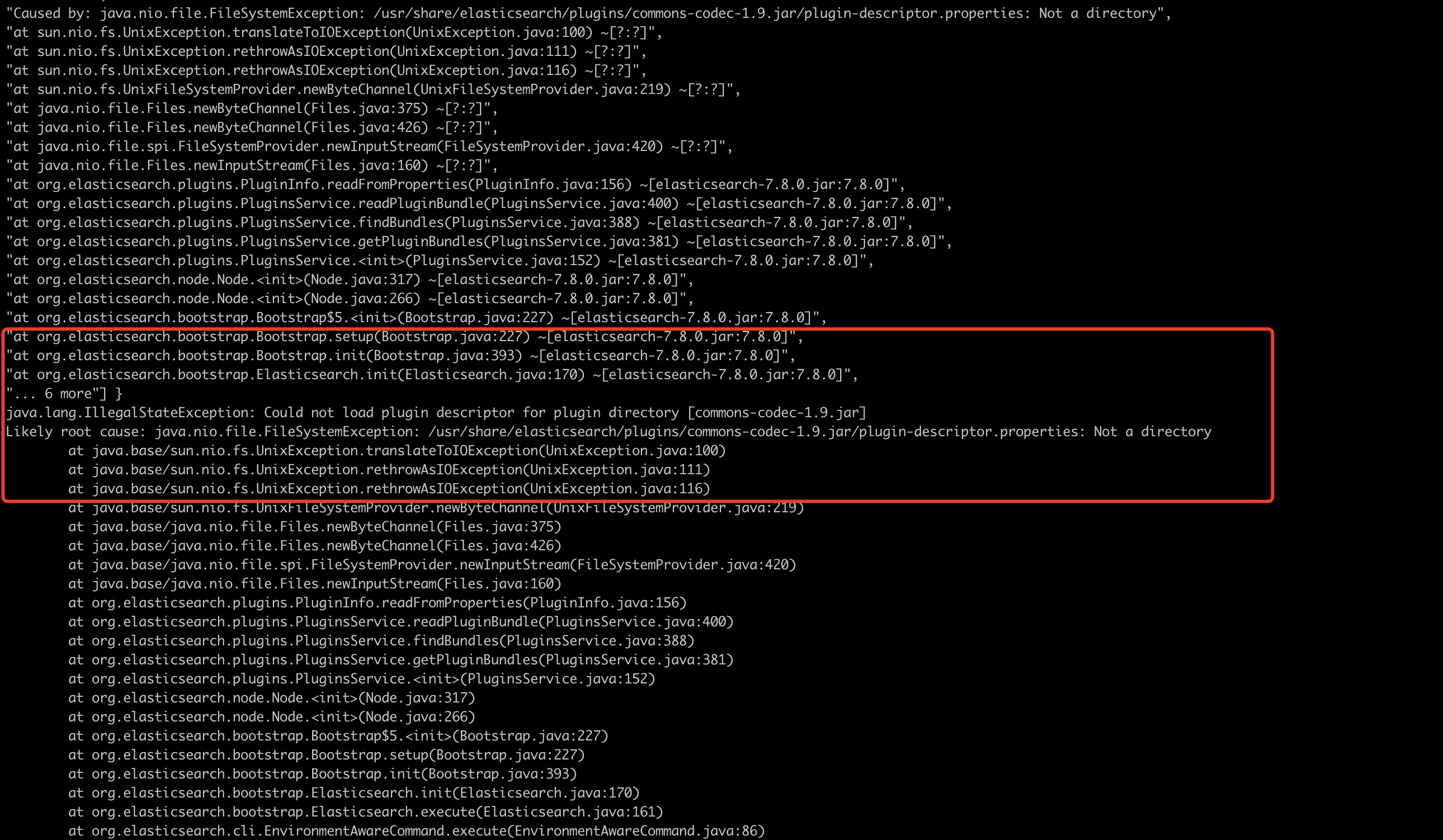
如果是docker启动挂载,则在挂载目录创建即可
4.将下载好ik zip文件移动到ik目录下并解压例如linux:unzip elasticsearch-analysis-ik-7.8.0.zip
5.重启es
6.plugins/ik/config/IKAnalyzer.cfg.xml:ik分词的配置文件,可以配置停用词,自定义扩展词,远程扩展词等
注意:远程词典域名访问可能会访问无法拉取词典,也可能是版本问题,ip方式访问没问题
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entrykey="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entrykey="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>远程扩展词java代码仅供参考
@RequestMapping("/ikDic")public String ikDic(HttpServletRequest request, HttpServletResponse response){
log.info("keyword/ikDic start");
String result="";
String eTag= request.getHeader("If-None-Match");
String modified= request.getHeader("If-Modified-Since");
String currentDate= DateUtil.formateDate(newDate(),"yyyyMMdd");// 发生改变更新 ik字典boolean redisKey=false;try{
String keyword_ikDic_key= redisUtil.get("keyword_ikDic_key");if(StringUtils.isBlank(keyword_ikDic_key)){
redisKey=true;}}catch(Exception e){
log.info("keyword/ikDic 无此key keyword_ikDic_key");}
log.info("加载ik分词,上次分词数:{},上次修改时间:{},当前日期:{},redisKey_ikDic={}",eTag,modified,currentDate,redisKey);//设置头if(!currentDate.equals(modified)|| redisKey){
Integer oldTag= ikService.getKeywordsByCreateTimeCount();
log.info("keyword/ikDic oldTag 加载ik分词,当前分词数:{},上次分词数={}",oldTag,eTag);if(!oldTag.equals(eTag)|| redisKey){
redisUtil.set("keyword_ikDic_key", oldTag);
result= ikService.ikDic();
log.info("keyword/ikDic success 加载ik分词");
eTag= oldTag;
modified= currentDate;}}//更新时间
response.setHeader("Last-Modified", modified);
response.setHeader("ETag", eTag);
log.info("keyword/ikDic end");return result;}