本博客是在Jupyter Notebook下进行的编译。
MNIST
MNIST数据集,这是一组由美国高中生和人口调查局员工手写的70000个数字的图片。每张图像都用其代表的数字标记。这个数据集被广为使用,因此也被称作是机器学习领域的“Hello World”。
首先,我们使用sklearn的函数来获取MNIST数据集,代码如下:
# 使用sklearn的函数来获取MNIST数据集from sklearn.datasetsimport fetch_openmlimport numpyas npimport os# to make this notebook's output stable across runs
np.random.seed(42)# To plot pretty figures%matplotlib inlineimport matplotlibas mplimport matplotlib.pyplotas plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)# 为了显示中文
mpl.rcParams['font.sans-serif']=[u'SimHei']
mpl.rcParams['axes.unicode_minus']=False# 耗时巨大defsort_by_target(mnist):
reorder_train=np.array(sorted([(target,i)for i, targetinenumerate(mnist.target[:60000])]))[:,1]
reorder_test=np.array(sorted([(target,i)for i, targetinenumerate(mnist.target[60000:])]))[:,1]
mnist.data[:60000]=mnist.data[reorder_train]
mnist.target[:60000]=mnist.target[reorder_train]
mnist.data[60000:]=mnist.data[reorder_test+60000]
mnist.target[60000:]=mnist.target[reorder_test+60000]
mnist=fetch_openml('mnist_784',version=1,cache=True)#获取数据
mnist.target=mnist.target.astype(np.int8)
sort_by_target(mnist)获取数据这部分,运行起来可能会稍微有点慢,可以加个定时器,看看运行的时间。
代码如下:
import time
y1= time.time()
mnist=fetch_openml('mnist_784',version=1,cache=True)
mnist.target=mnist.target.astype(np.int8)
sort_by_target(mnist)
y2= time.time()
display(y2-y1)运行结果如下:
我的电脑性能一般,时间是33秒。如果电脑性能较好的会比较快一些。
添加下面这句代码,可对数据集进行排序。
mnist["data"], mnist["target"]运行结果如下:
使用下面这三种方法,可以查看维度。
方法一:
mnist.data.shape方法二:
X,y=mnist["data"],mnist["target"]
X.shape方法三:
y.shape28*28运行结果如下:
可以看到结果都一样的,是70000张图片,784维
展示单张图片,代码如下:
defplot_digit(data):
image= data.reshape(28,28)
plt.imshow(image, cmap= mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
some_digit= X[36000]
plot_digit(X[36000].reshape(28,28))运行结果如下: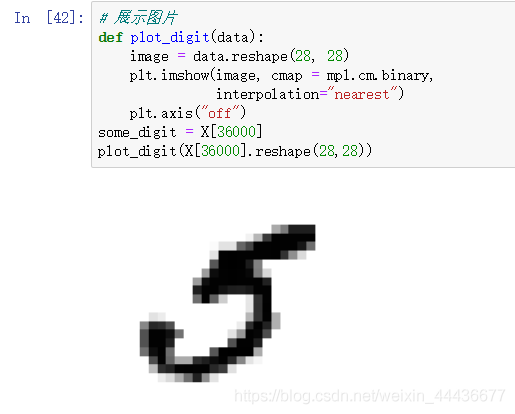
展示十行十列的图片,代码如下:
defplot_digits(instances,images_per_row=10,**options):
size=28# 每一行有一个
image_pre_row=min(len(instances),images_per_row)
images=[instances.reshape(size,size)for instancesin instances]# 有几行
n_rows=(len(instances)-1)// image_pre_row+1
row_images=[]
n_empty=n_rows*image_pre_row-len(instances)
images.append(np.zeros((size,size*n_empty)))for rowinrange(n_rows):# 每一次添加一行
rimages=images[row*image_pre_row:(row+1)*image_pre_row]# 对添加的每一行的额图片左右连接
row_images.append(np.concatenate(rimages,axis=1))# 对添加的每一列图片 上下连接
image=np.concatenate(row_images,axis=0)
plt.imshow(image,cmap=mpl.cm.binary,**options)
plt.axis("off")
plt.figure(figsize=(9,9))
example_images=np.r_[X[:12000:600],X[13000:30600:600],X[30600:60000:590]]
plot_digits(example_images,images_per_row=10)
plt.show()运行结果如下:
创建一个测试集,代码如下:
X_train, X_test, y_train, y_test= X[:60000], X[60000:], y[:60000], y[60000:]对训练集进行洗牌,这样是为了保证交叉验证的时候,所有的折叠都差不多。此外,有些机器学习算法对训练示例的循序敏感,如果连续输入许多相似的实例,可能导致执行的性能不佳。给数据洗牌,正是为了确保这种情况不会发生。
代码如下:
import numpyas np
shuffer_index=np.random.permutation(60000)
X_train,y_train=X_train[shuffer_index],y_train[shuffer_index]训练一个二分类器
我们先尝试识别一个数字,比如数字5,那么这个"数字5检测器",就是一个二分类器的例子,它只能区分两个类别:5和非5。
为此分类任务创建目录标量,代码如下:
y_train_5=(y_train==5)
y_test_5=(y_test==5)接着挑选一个分类器并开始训练。一个好的选择是随机梯度下降(SGD)分类器,使用sklearn的SGDClassifier类即可。这个分类器的优势是:能够有效处理非常大型的数据集。这部分是因为SGD独立处理训练实例,一次处理一个。
代码如下:
from sklearn.linear_modelimport SGDClassifier
sgd_clf=SGDClassifier(max_iter=5,tol=-np.infty,random_state=42)
sgd_clf.fit(X_train,y_train_5)运行结果如下:
然后可以在用它来预测一下前面的“数据5”,代码如下:
sgd_clf.predict([some_digit])运行结果如下:
输出了True,可以看到它预测出来了。
使用交叉验证测量精度
随机交叉验证和分层交叉验证效果对比
三折交叉验证,代码如下:
from sklearn.model_selectionimport cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")分3层交叉验证,代码如下:
# 类似于分层采样,每一折的分布类似from sklearn.model_selectionimport StratifiedKFold#分层from sklearn.baseimport clone
skfolds= StratifiedKFold(n_splits=3, random_state=42)#分3层for train_index, test_indexin skfolds.split(X_train, y_train_5):
clone_clf= clone(sgd_clf)#克隆分类器
X_train_folds= X_train[train_index]#训练
y_train_folds=(y_train_5[train_index])
X_test_fold= X_train[test_index]
y_test_fold=(y_train_5[test_index])
clone_clf.fit(X_train_folds, y_train_folds)
y_pred= clone_clf.predict(X_test_fold)
n_correct=sum(y_pred== y_test_fold)print(n_correct/len(y_pred))运行结果如下:
我们可以看到两种交叉验证的准确率都达到了95%上下。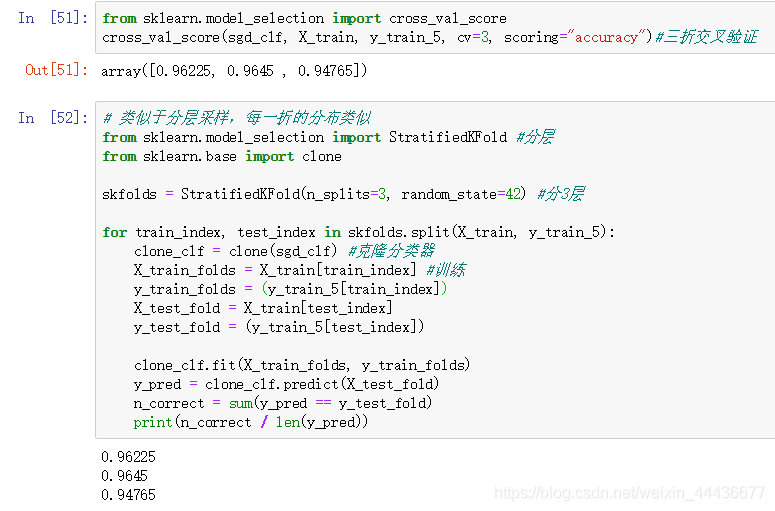
我们可以再用一个分类器来进行比较,代码如下:
from sklearn.baseimport BaseEstimator# 随机预测模型classNever5Classifier(BaseEstimator):deffit(self, X, y=None):passdefpredict(self, X):return np.zeros((len(X),1), dtype=bool)
never_5_clf= Never5Classifier()
cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring="accuracy")运行结果如下:
它的准确率也超过了90%,这是因为我们只有大约10%的图像是数字5,所以只要猜一张图片不是5,那么有90%的时间都是正确的。也就是说,准确率通常无法成为分类器的首要性能指标,特别是当我们处理偏斜数据集的时候(也就是某些类别比其他类更加频繁的时候)。
混淆矩阵
评估分类器性能的更好的方法是混淆矩阵。总体思路就是统计A类别实例被分成B类别的次数。例如,要想知道分类器将数字3和数字5混淆多少次,只需要通过混淆矩阵的第5行第3列来查看。
要计算混淆矩阵,需要一组预测才能将其与实际目标进行比较。当然可以通过测试集来进行预测,但是现在我们不动它(测试集最好保留到项目的最后,准备启动分类器时再使用)。最为代替,可以使用cross_val_predict()函数。cross_val_predict 和 cross_val_score 不同的是,前者返回预测值,并且是每一次训练的时候,用模型没有见过的数据来预测
代码如下:
from sklearn.model_selectionimport cross_val_predict
y_train_pred= cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)#获取预测值from sklearn.metricsimport confusion_matrix
confusion_matrix(y_train_5, y_train_pred)#预测值与实际值的混淆矩阵构建输出结果如下图所示:
结果表明第一行所有’非5’(负类)的图片中,有53417被正确分类(真负类),1162,错误分类成了5(假负类);第二行表示所有’5’(正类)的图片中,有1350错误分类成了非5(假正类),有4071被正确分类成5(真正类)。也就是说,实际不是5预测也不是5的个数53417,实际不是5预测是5的个数1162,实际是5预测不是5的个数1350,实际为5预测是5的个数4071。
一个完美的分类器只有真正类和真负类,所以其混淆矩阵只会在其对角线(左上到右下)上有非零值。代码如下:
y_train_perfect_predictions= y_train_5
confusion_matrix(y_train_5, y_train_perfect_predictions)运行结果如下:
精度和召回率
混淆矩阵能提供大量信息,但有时我们可能会希望指标简洁一些。正类预测的准确率也称为分类器的精度。
P
r
e
c
i
s
i
o
n
(
精
度
)
=
T
P
T
P
+
F
P
Precision(精度)=\frac{TP}{TP+FP}Precision(精度)=TP+FPTP
其中TP是真正类的数量,FP是假正类的数量。
做一个简单的正类预测,并保证它是正确的,就可以得到完美的精度(精度=1/1=100%)
分类器会忽略这个正实例之外的所有内容。因此,精度通常会与另一个指标一起使用,这就是召回率,又称为灵敏度或者真正类率(TPR):它是分类器正确检测到正类实例的比率(如下):
R
e
c
a
l
l
(
召
回
率
)
=
T
P
T
P
+
F
N
Recall(召回率)=\frac{TP}{TP+FN}Recall(召回率)=TP+FNTP
FN是假负类的数量。
例如有一个二分类问题的算法。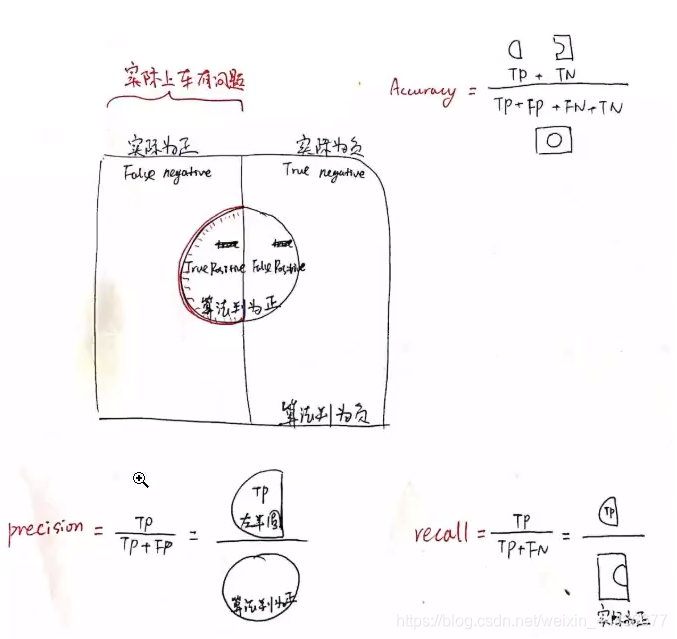
图中的圆圈里面代表算法判定为正的一些样本,圆圈的外面代表算法判定为负的一些样本。
但实际上算法它是会有一些误判的,例如方形的左边一半,是实际上为正的样本。右边-半,是实际上为负的样本。那除了算法判断正确的,以外就是判断错误的样本。
可以对照这个图,看一下准确率,精度,和召回率的定义。
右上角是准确率的公式。意思就是,算法的所有预测结果中,预测正确的有多少。
左下角为precision精度查准率就是对于所有机器判定为正的里面,有多大的比例是真的正样本。
右下角为recall召回率查全率,顾名思义,就是实际的正样本中,有多大比例被检出了。
在图中有标记,阴阳,真假。真/假阴/阳性中,阴阳性是指的分类器的判断结果是阴性还是阳性,而真假指代的是是否和真是答案相符。不同的问题,他需要用的指标,希望达到的目标是不一样的。
回到我们原先的数字5检测器
使用sklearn的工具度量精度和召回率。代码如下:
from sklearn.metricsimport precision_score, recall_score
precision_score(y_train_5, y_train_pred)recall_score(y_train_5, y_train_pred)运行结果如下:
这个数字5检测器,并不是那么完美,大多时候,它说一张图片为5时,只有77%的概率是准确的,并且也只有75%的5被检测出来了。
我们可以将精度和召回率组合成单一的指标,称为F1分数。
F
1
=
2
1
P
r
e
c
i
s
i
o
n
+
1
R
e
c
a
l
l
=
2
∗
P
r
e
∗
R
e
c
P
r
e
+
R
e
c
=
T
P
T
P
+
F
N
+
F
P
2
F_1=\frac{2}{\frac{1}{Precision}+\frac{1}{Recall}}=2*\frac{Pre*Rec}{Pre+Rec}=\frac{TP}{TP+\frac{FN+FP}{2}}F1=Precision1+Recall12=2∗Pre+RecPre∗Rec=TP+2FN+FPTP
要计算F1分数,只需要调用f1_score()即可。代码如下:
from sklearn.metricsimport f1_score
f1_score(y_train_5, y_train_pred)运行结果如下:
F1分数对那些具有相近的精度和召回率的分类器更为有利。这不一定一直符合预期,因为在某些情况下,我们更关心精度,而另一些情况下,我们可能真正关系的是召回率。
精度/召回率权衡
在分类中,对于每个实例,都会计算出一个分值,同时也有一个阈值,大于为正例,小于为负例。通过调节这个阈值,可以调整精度和召回率。
得到召回率的代码如下:
y_scores= sgd_clf.decision_function([some_digit])
y_scores运行结果如下:
调整阈值为0和20000时,代码如下:
threshold=0#调整阈值为0
y_some_digit_pred=(y_scores> threshold)
y_some_digit_pred运行结果如下:
可以看到当阈值为0时,前面计算的分值大于0,返回True;它小于20000,返回False。
交叉验证。要注意它返回的是决策分数,而不是预测结果。
y_scores= cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")
y_scores.shape运行结果如下:
画图:精度和召回率的曲线图
代码如下:
from sklearn.metricsimport precision_recall_curve#画图
precisions, recalls, thresholds= precision_recall_curve(y_train_5, y_scores)defplot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1],"b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1],"g-", label="Recall", linewidth=2)
plt.xlabel("Threshold", fontsize=16)
plt.title("精度和召回率VS决策阈值", fontsize=16)
plt.legend(loc="upper left", fontsize=16)
plt.ylim([