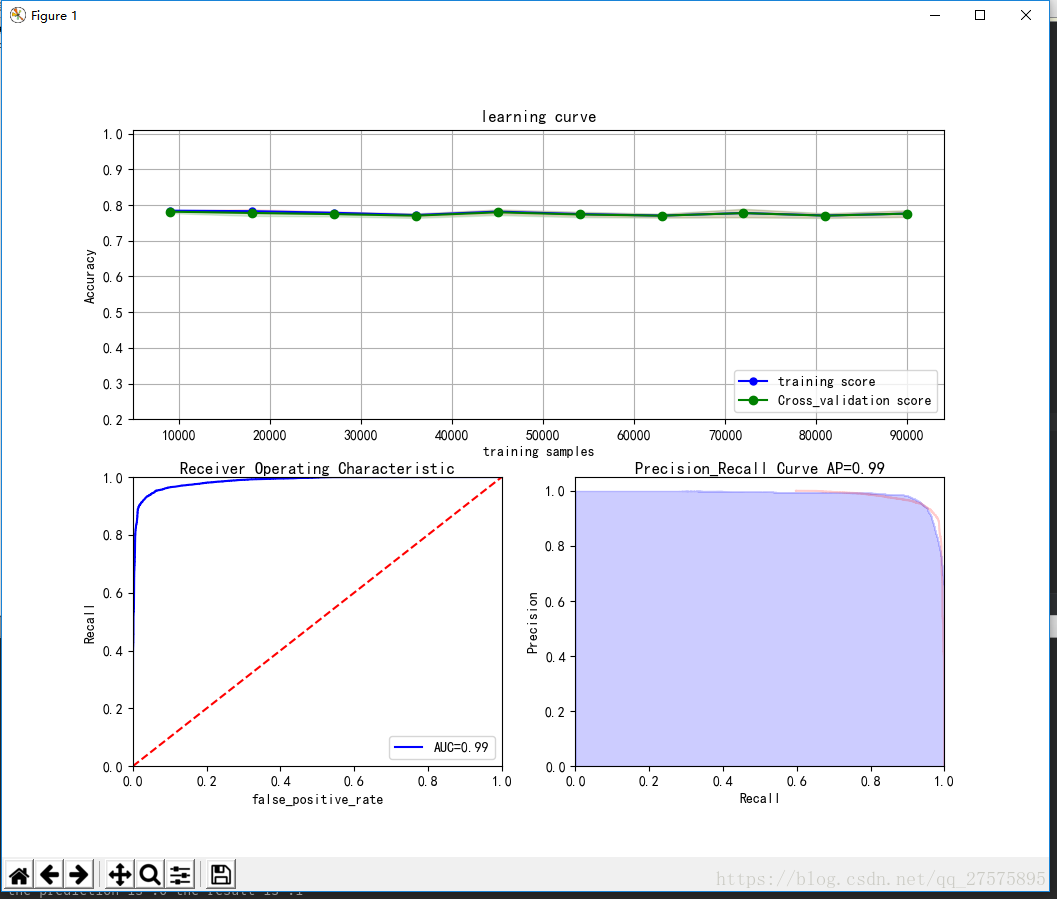
在机器学习中,当我们基于某个业务建立模型并训练后,接下来我们需要评判模型好坏的时候需要基于混淆矩阵,ROC和AUC等来进行辅助判断。
混淆矩阵也叫精度矩阵,是用来表示精度评价,为N *N的矩阵,用来判别分类好坏的指标。
混淆矩阵中有以下几个概念:
TP(True Positive): 被判定为正样本,实际也为正样本
FN(False Negative):伪阴性 ,被判定为负样本,实际为正样本
FP(False Positive):伪阳性,被判断为正样本,实际为负样本
TN(True Negative):被判断为负样本,实际为负样本
另外模型的评判的时候大家会谈到如下几个指标概念:
精确率(Precision):也称之为查准率,代指实际为正样本你预测也为正样本占整体你预测为正样本的比重
召回率(Recall):也称为查全率,代指实际为正样本你预测也为正样本占整体实际为正样本的比重 。换句话说可以认为,实际为正样本中你在预测中也正确预测为正样本的占比有多大。
这些概念很绕,建议多读几遍,多思考几次,慢慢的就有了一个印象。
所以在模型评判的时候我们需要把握最终看重的结果,比如在流失模型中,流失用户占比始终是小部分,那么我们要尽可能全的把这部分小样本数据找到,那么会更看重查全率,也就是Recall.
利用Python来定义混淆矩阵如下:
通过sklearn导入混淆矩阵
from sklearn.metrics import confusion_matrix,roc_curve,auc,precision_recall_curve,average_precision_score
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as pltdef confusion_metrix(y,y_p):
Confusion_matrix=confusion_matrix(y,y_p) #y代表真实值,y_p 代表预测值
plt.matshow(Confusion_matrix)
plt.title("混淆矩阵")
plt.colorbar()
plt.ylabel("实际类型")
plt.xlabel("预测类型")通过调用sklearn的confusion_matrix我们就可以得到混淆矩阵,通过画图来画出对应的图形
ROC(Receiver Operating Characteristic): 是一条曲线,由FPR和TPR的点连成。横轴是FPR,纵轴是TPR
AUC(Area Under the Curve):ROC的曲线面积就是AUC值。AUC主要用于衡量二分类问题中机器学习算法性能或者泛化能力。
下面截图ROC曲线
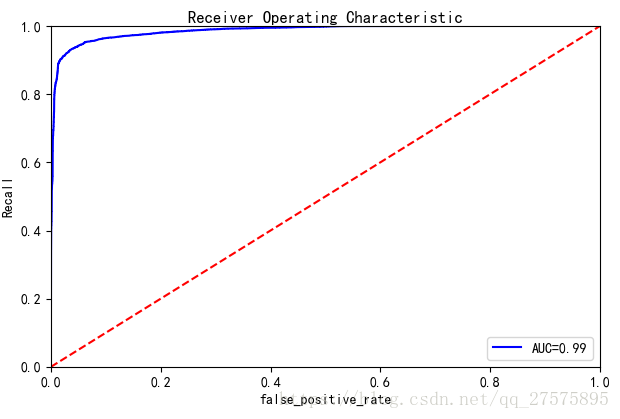
ROC曲线重点了解下这几个节点:
(0,1)点:代表FPR=0,TPR=1; 最好的情况,所有正样本都被正确的预测了,并且没有负样本被人为是正样本。
(1,0)点:代表FPR=1,TPR=0;最坏的情况,表明所有的正样本都被错误的认为是负样本
(0,0)点:代表FPR=0,TPR=0;分类器将所有的样本都判定为负样本
(1,1)点:代表FPR=1,TPR=1;分类器将所有的样本都判定为正样本
如上图,有一条红色的虚线,y=x ,这条曲线的面积为0.5 ,这里是代表的如果是随机猜测的话,AUC=0.5.如果我们得到的ROC曲线在y=x下面,AUC<0.5,则表明分类器不合格,还不如乱猜测。
在实际中由于侧重的点不同,所以我们需要明白侧重在哪,如果在实际中结果重在覆盖,我们应该更加注重True Positive高,如果是重在准确,我们则应该更加注重False Positive低
那么怎么通过ROC曲线来判断True Positive和False Positive呢? 这里我们如果看到曲线越往左上凸越好,这样得到的True Positive 就越高,对应的False Positive越低,
上图来自于我做的逻辑回归分类,最终得到的模型AUC=0.99。
PR曲线:是由精确率和召回率的点连成的线,横轴为Recall ,纵轴为Precision,
在PR曲线中越右上凸越好,PR想要Precision 和Recall同时高
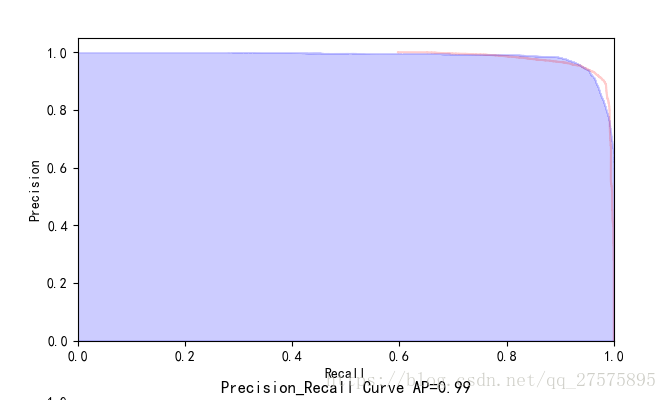
如果样本表现的极不均衡的时候,哪个曲线更好呢?通过ROC曲线和PR曲线的含义,我们事先假设正样本非常少,负样本非常多,这样TN会非常大,将FPR拉低,最后的曲线会表现的非常好,但是我们再反过来看PR曲线,我们会发现曲线反而表现的没那么好。所以我们在判断的时候不能由单一指标来下决定。
实现代码如下:
def plot_PR(model,x_test,y_test):#绘制PR曲线
y_pro=model.predict_proba(x_test)
precision,recall,thresholds=precision_recall_curve(y_test,y_pro[:,1])
average_precision = average_precision_score(y_test, y_pro[:, 1])
ax2 = plt.subplot(224)
ax2.set_title("Precision_Recall Curve AP=%0.2f"%average_precision,verticalalignment='center')
plt.step(precision, recall,where='post',alpha=0.2,color='r')
plt.fill_between(recall,precision,step='post',alpha=0.2,color='b')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.ylabel('Precision')
plt.xlabel('Recall')
def plot_ROC(model,x_test,y_test):#绘制ROC和AUC,来判断模型的好坏
y_pro=model.predict_proba(x_test)
false_positive_rate,recall,thresholds=roc_curve(y_test,y_pro[:,1])
roc_auc=auc(false_positive_rate,recall)
ax3=plt.subplot(223)
ax3.set_title("Receiver Operating Characteristic",verticalalignment='center')
plt.plot(false_positive_rate,recall,'b',label='AUC=%0.2f'%roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([0.0,1.0])
plt.ylim([0.0,1.0])
plt.ylabel('Recall')
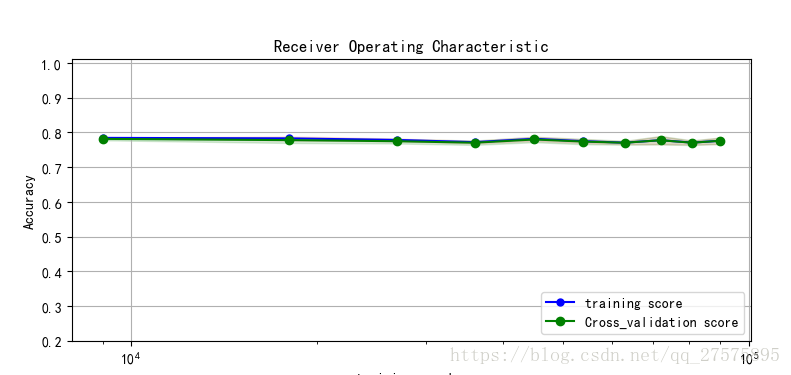
plt.xlabel('false_positive_rate')学习曲线:主要用来提高学习算法性能,通过对学习中的过程进行判断,来进一步调整学习参数。来判断模型是否过拟合。
我们通过绘制可以发现效果如下:
对应实现代码如下:
def plot_learning_cruve(model,x,y,train_sizes,n_jobs):#绘制学习曲线来判断模型的学习情况
#构建学习曲线评估器,train_size:控制用于生成学习曲线的样本的绝对或相对数量
cv=10 #ShuffleSplit(4,n_iter=3,test_size=0.2,random_state=0)
train_sizes,train_scores,test_scores=learning_curve(estimator=model,X=x,y=y,train_sizes=train_sizes,cv=cv,n_jobs=n_jobs)
#统计结果
train_score_mean=np.mean(train_scores,axis=1)
train_score_std=np.std(train_scores,axis=1)
test_score_mean=np.mean(test_scores,axis=1)
test_score_std=np.std(test_scores,axis=1)
#绘制效果图
ax1=plt.subplot(211)
ax1.set_title('learning curve')
plt.fill_between(train_sizes,train_score_mean-train_score_std,train_score_mean+train_score_std,alpha=0.1,color='r')
plt.fill_between(train_sizes,test_score_mean+test_score_std,test_score_mean-test_score_std,alpha=0.15,color='green')
plt.plot(train_sizes, train_score_mean, color='blue', marker='o', markersize=5, label='training score')
plt.plot(train_sizes,test_score_mean,'o-',color='g',label='Cross_validation score')
plt.grid()
plt.xlabel('training samples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim([0.2,1.01])最后作图如下: