1.结果映射ResultMap
resultMap 元素有很多子元素和一个值得深入探讨的结构。
- constructor - 用于在实例化类时,注入结果到构造方法中
idArg- ID 参数;标记出作为 ID 的结果可以帮助提高整体性能arg- 将被注入到构造方法的一个普通结果
id– 一个 ID 结果;标记出作为 ID 的结果可以帮助提高整体性能result– 注入到字段或 JavaBean 属性的普通结果- association – 一个复杂类型的关联;许多结果将包装成这种类型
- 嵌套结果映射 – 关联可以是
resultMap元素,或是对其它结果映射的引用
- 嵌套结果映射 – 关联可以是
- collection – 一个复杂类型的集合
- 嵌套结果映射 – 集合可以是
resultMap元素,或是对其它结果映射的引用
- 嵌套结果映射 – 集合可以是
- discriminator – 使用结果值来决定使用哪个 resultMap
- case – 基于某些值的结果映射
- 嵌套结果映射 –
case也是一个结果映射,因此具有相同的结构和元素;或者引用其它的结果映射
- 嵌套结果映射 –
- case – 基于某些值的结果映射
1.1、解决问题
- 解决属性名和字段名不一致的问题
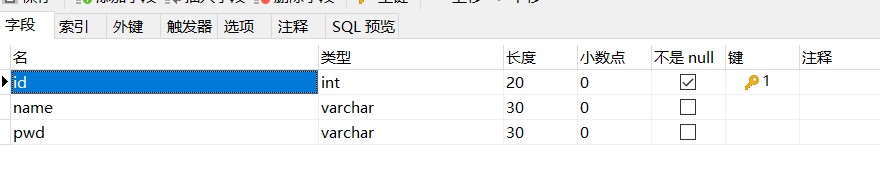
新建一个项目,参考之前第一个mybatis程序的代码,原来属性名和字段是对应的,现在我们把它改的不一样。
publicclassUser{privateint id;private String name;private String password;测试出现问题(password为null)
select* from mybatis.user where id= #{id}//类型处理器 如何让pwd传进password
select id,`name`,pwd from mybatis.user where id= #{id}解决方法:
- 起别名
<selectid="getUserById"resultMap="UserMap">
select id,`name`,pwd as password from mybatis.user where id = #{id}</select>这种方式比较low,建议使用下面这种方式
1.2、result
结果集映射
id name pwd
id name password- column数据库中的字段,property实体类中的属性
<!--结果集映射--><resultMapid="UserMap"type="User"><!--<result column="id" property="id"/>--><!--<result column="name" property="name"/>--><!--什么不一样转什么--><resultcolumn="pwd"property="password"/></resultMap><selectid="getUserById"resultMap="UserMap">
select * from mybatis.user where id = #{id}</select>- 可以让你从 90%的 JDBC
ResultSets数据提取代码中解放出来,并在一些情形下允许你进行一些 JDBC 不支持的操作。 - ResultMap 的设计思想是,对简单的语句做到零配置,对于复杂一点的语句,只需要描述语句之间的关系就行了。
ResultMap的优秀之处——你完全可以不用显式地配置它们。 (什么不一样转什么,都一样就可以不转)- 如果这个世界总是这么简单就好了。
1.3、多对一处理
多对一:
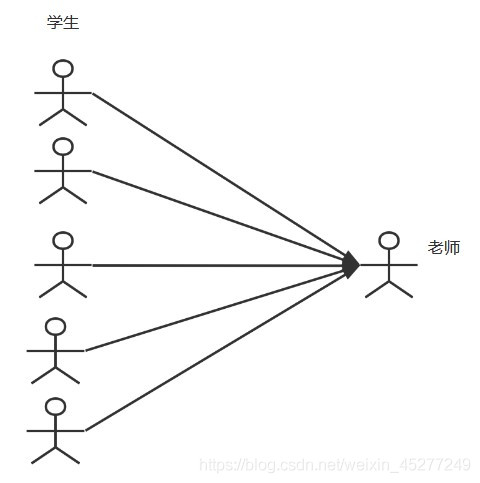
- 多个学生,对应一个老师
- 对于学生这边而言,关联----多个学生关联一个老师
- 对应老师而言,集合-----一个老师有很多学生
SQL:
CREATETABLE`teacher`(`id`INT(10)NOTNULLPRIMARYKEY,`name`VARCHAR(30)DEFAULTNULL)ENGINE=InnoDBDEFAULTCHARSET=utf8;INSERTINTO teacher(`id`,`name`)VALUES(1,'李老师');CREATETABLE`student`(`id`INT(10)NOTNULL,`name`VARCHAR(30)DEFAULTNULL,`tid`INT(10)DEFAULTNULL,PRIMARYKEY(`id`),KEY`fktid`(`tid`),CONSTRAINT`fktid`FOREIGNKEY(`tid`)REFERENCES`teacher`(`id`))ENGINE=INNODBDEFAULTCHARSET=utf8INSERTINTO student(`id`,`name`,`tid`)VALUES(1,'小明',1);INSERTINTO student(`id`,`name`,`tid`)VALUES(2,'小红',1);INSERTINTO student(`id`,`name`,`tid`)VALUES(3,'熊大',1);INSERTINTO student(`id`,`name`,`tid`)VALUES(4,'熊二',1);INSERTINTO student(`id`,`name`,`tid`)VALUES(5,'喜羊羊',1);测试环境搭建
- 新建实体类Teacher,Student
- 建立Mapper接口
- 建立Mapper.xml文件
- 在核心配置文件中绑定注册我们的Mapper接口或者文件!【方式很多,随心选】
- 测试查询是否能够成功!
按照查询嵌套处理
<!--
思路:
1.查询所有的学生信息
2.根据查询的学生的tid,寻找对应的老师
--><selectid="getStudent"resultMap="StudentTeacher">
SELECT * FROM student</select><resultMapid="StudentTeacher"type="Student"><resultproperty="id"column="id"/><resultproperty="name"column="name"/><!--
复杂的属性,我们需要单独处理 对象:association 集合:collection
--><associationproperty="teacher"column="tid"javaType="Teacher"select="getTeacher"/></resultMap><selectid="getTeacher"resultType="Teacher">
select * from teacher where id=#{id}</select>按照结果嵌套处理
<selectid="getStudent2"resultMap="StudentTeacher2">
select s.id sid,s.name sname,t.name tname
from student s,teacher t
where s.tid=t.id;</select><resultMapid="StudentTeacher2"type="Student"><resultproperty="id"column="sid"/><resultproperty="name"column="sname"/><associationproperty="teacher"javaType="Teacher"><resultproperty="name"column="tname"/></association></resultMap>回顾Mysql多对一查询方式:
- 子查询
- 联表查询
1.4、一对多处理
- 环境搭建,和上面多对一样。
实体类
publicclassStudent{privateint id;private String name;//学生需要关联一个老师privateint tid;}publicclassTeacher{privateint id;private String name;//一个老师拥有多个学生private List<Student> students;}按照结果嵌套处理
<selectid="getTeacher"resultMap="TeacherStudent">
SELECT s.id sid,s.name sname,t.name tname,t.id tid
FROM student s,teacher t
WHERE s.tid=t.id and t.id=#{tid}</select><resultMapid="TeacherStudent"type="Teacher"><resultproperty="id"column="tid"></result><resultproperty="name"column="tname"></result><!--复杂的属性,我们需要单独处理 对象:association 集合:collection
javaType="" 指定属性的类型
集合中的泛型信息,我们使用ofType获取
--><collectionproperty="students"ofType="Student"><resultproperty="id"column="sid"/><resultproperty="name"column="sname"/><resultproperty="tid"column="tid"/></collection></resultMap>按照查询处理
<selectid="getTeacher2"resultMap="TeacherStudent2">
select * from teacher where id=#{tid}</select><resultMapid="TeacherStudent2"type="Teacher"><collectionproperty="students"javaType="ArrayList"ofType="Student"select="getStudentByTeacherId"column="id"/></resultMap><selectid="getStudentByTeacherId"resultType="Student">
select * from student where tid=#{tid}</select>小结:
- 关联 - association【多对一】des
- 集合 - collection【一对多】
- javaType & ofType
- javaType用来指定实体类中的属性类型
- ofType用来指定映射到List或者集合的pojo类型,泛型中的约束类型!
注意点:
- 保证SQL的可读性,尽量保证通俗易懂
- 注意一对多和多对一中,属性名和字段的问题
- 如果问题不好排查错误,可以使用日志,建议使用Log4j
慢SQL 1s 1000s
面试高频
- Mysql引擎
- InnDB底层原理
- 索引
- 索引优化
2.Limit分页
思考:为什么要分页?
- 减少数据的处理量
2.1、使用Limit分页
语法:SELECT*fromuserlimit startIndex,pageSize;select*fromuserlimit3;#[0,n]使用Mybatis实现分页,核心SQL
- 接口
List<User>getUserByLimit(Map<String,Integer> map);- Mapper.xml
<!--分页--><selectid="getUserByLimit"parameterType="map"resultType="User"resultMap="UserMap">
select * from user limit #{startIndex},#{pageSize}</select>- 测试
@TestpublicvoidgetUserByLimit(){
SqlSession sqlSession= MybatisUtil.getSqlSession();
UserMapper userMapper= sqlSession.getMapper(UserMapper.class);
HashMap<String,Integer> map=newHashMap<String, Integer>();
map.put("startIndex",0);
map.put("pageSize",2);
List<User> userList= userMapper.getUserByLimit(map);for(User user:userList){
System.out.println(userList);}
sqlSession.close();}2.2、RowBounds分页(作为了解)
不再使用SQL实现分页
- 接口
List<User>getUserByRowBounds();- mapper.xml
<!--分页2--><selectid="getUserByRowBounds"resultType="User"resultMap="UserMap">
select * from user</select>- 测试
@TestpublicvoidgetUserByRowBounds(){//RowBounds实现
RowBounds rowBounds=newRowBounds(1,2);//通过java代码层面实现分页
List<User> userList= sqlSession.selectList("cn.cgz.dao.UserMapper.getUserByRowBounds",null,rowBounds);for(User user:userList){
System.out.println(user);}
sqlSession.close();}7.3、分页插件
了解即可,万一以后公司架构师说要使用,你要知道它是什么东西!