BN层和Dropout在训练与测试时的差别以及实现细节
1·BN层介绍及测试训练的差别
BN也即Batch Normalization,批规范化,是由谷歌的大佬们在2015年《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》提出的。文章指出,深度网络中每一层的输入分布都会因为前层的参数变化而改变,这会导致我们不得不采用更低的学习率以及更小心的初始化等方式,减慢了模型的训练。文中将这一现象称为internal covariate shift ,可以理解为内部的分布漂移吧。BN就是通过每一个mini batch的规范化解决这一问题。
BN层能够允许我们使用更大的学习率,不那么关注参数的初始化,也可以为模型提供正则化的功能。
BN层的原理如下: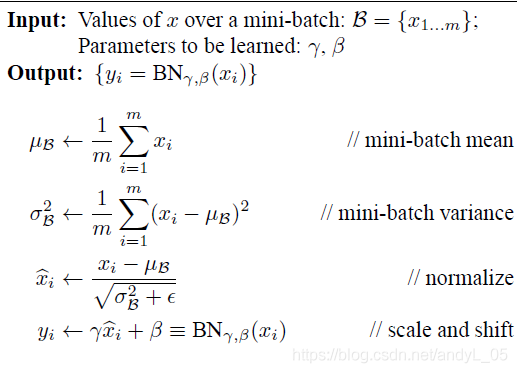
以CNN为例,每一层输入的数据多为 NWHC的张量,N表示batch size,WH是特征图大小,C指的是特征数或通道数。BN层对每个通道对应的NWH的数据进行归一化,并进行变化重构,变化重构参数
γ
\gammaγ和
β
\betaβ是可学习的,首先对输入数据取均值和标准差,并进行归一化,
ϵ
\epsilonϵ是防止除0的很小数值,然后对归一化后的数据进行变换重构。
BN层在训练阶段,对每一批mini-batch的数据分别求均值与方差用于规范化,但在测试阶段,这一值使用的是全期训练数据的均值方差,也即模型训练到当前状态所有数据的均值方差,这个数据是在训练过程中通过移动平均法得到的。
文中Training a Batch-Normalized Network 的算法流程图解释了这一部分的区别:
2·Dropout介绍及测试训练差别
Dropout提出的时间要更早一些,是由Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton 几位大神在2010年《ImageNet Classification with Deep Convolutional Neural Networks》一文中提出的(也就是提出AlexNet的文章)Dropout只被作为这篇文章的一个小章节。在文中作为了一种解决过拟合的方法,与数据扩增方法并列。事实上,dropout也确实有助于解决模型的过拟合问题。
Dropout的核心思想是训练时以一定的概率p(通常是50%)关闭隐藏层神经元的输出,也就是输出为0。这种策略可以从不同角度理解:首先这使得每次训练的模型并不是相同的结构,可以认为是原网络的子集,最终的输出是这些不同模型不同结构共同作用的结果(类似于集成学习中Bagging的策略);另外Dropout方法可以让神经元之间减小依赖性,因为随机的关闭可以使得神经元之间不会总是同时作用。
测试时,全部神经元都使用,但是他们的输出乘上了系数(1-p)。
Dropout作为解决过拟合的重要方法之一,历史更为悠久。不过BN层一文提到其正则化作用能够取代Dropout方法。目前来看,Dropout的使用确实越来越少。也有越来越多防止过拟合、提高训练效率的方法在不断被提出,我后续会继续关注并进行一些介绍的。
3·PyTorch实现时的注意事项
综合来看,BN层在训练和测试的主要区别在于:训练时的均值方差来源于当前的mini-batch数据,而测试时,则要使用训练使用过的全部数据的均值方差,这一点训练时就通过移动均值方法计算并保存下来了;Dropout方法的训练测试区别在于:训练时随机的关掉部分神经元,而测试时所有神经元都工作但都要乘上系数(可以理解为训练了很多子模型,测试时要求他们加权求和的结果,听起来更像bagging了,emmm)
PyTorch也提供了区分训练和测试的方法:
训练时
model.train()测试时
model.eval()实际上train()方法有默认的参数是(True)所以eval实际上也等价于
model.train(False)很简单,但不要忘记加上哦