(1)分类问题评估标准:
混淆矩阵:
| 真实结果\预测结果 | 正例 | 假例 |
|---|---|---|
| 正例 | 真正例TP(true positive) | 伪反例FN(false negative) |
| 假例 | 伪正例FP | 真反例TN |
准确率:
$$
accuracy =\frac{(TP + TN)}{ (TP+ FP + TN + FN)}
$$
精确率:
预测结果为正例样本中真实为正例的比例:
$$
precision=\frac{TP}{TP+FP}
$$
召回率:
真实为正例的样本中预测结果为正例的比例:
$$
recall=\frac{TP}{TP+FN}
$$
F1 Score
$$
F1 Score =\frac{P*R*2}{(P+R)},其中P和R分别为 precision 和 recall
$$
(2)模型的选择与调优:
交叉验证:
为了使模型评估更加准确
主要是对数据的处理:对训练集中的数据继续分为训练集和验证集
将训练集平均分为K组,称之为K折交叉验证
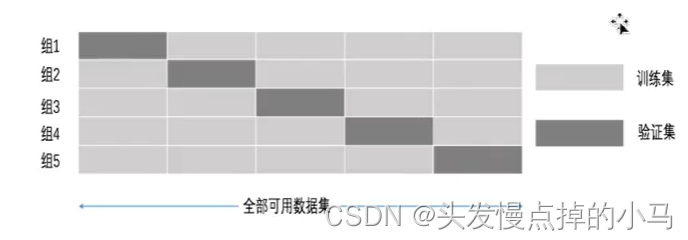
网格搜索:
调参数 KNN(比如K值 称为超参数)每组超参数都是采用交叉验证来进行评估
这里的K值可以进行3,5,10的选择,每组K值都有cv个结果,对所有结果取平均,选择最好的结果作为最优的参数
# 进行网格搜索优化调参
knn=KNeighborsClassifier()
param={"n-neighbors":[3,5,10]}
gc=GridSearchCV(knn,param_grid=param,cv=2) # cv是几折交叉验证
gc.fit(x_train,y_train)
print("在测试集上的准确率:",gc.score(x_test,x_test))
print("在交叉验证中最好的结果:",gc.best_score_)
print("选择最好的模型是:",gc.best_estimator_)
print("每个超参数每次交叉验证的结果是:",gc.cv_results_)
| K=3 | K=5 | K=10 | k值 |
|---|---|---|---|
| 0.66897856 | 0.6740227 | 0.65447667 | 第一次交叉验证 |
| 0.67559899 | 0.67291929 | 0.65668348 | 第二次交叉验证 |
| 0.67228878 | 0.673471 | 0.65558008 | 平均 |
①KNN
算法概要:
k-近邻算法:通过与需判断对象的相近的k个样本所属类别进行判断。
主要是通过距离来判断是否相近:
KNN所用的距离为欧式距离:
样本1(a1,a2,a3)样本2(b1,b2,b3)
两者之间的欧式距离为:
$$
\sqrt[2]{(b1-a1)^2+(b2-a2)^2+(b3-a3)^2}
$$
为了防止某个特征对结果产生较大的影响,需要对特征先进行一个标准化处理
预测入住地址案例:
主要是对数据进行预处理比较多
特征值:xy坐标、定位准确性、时间
目标值:入住位置的id
def knncls():
data=pd.read_csv("D:/study/postgraduate/data/facebook-v-predicting-check-ins/train.csv")
# print(data.head(10))
# print("over")
# 数据处理
# 缩小数据
data=data.query("x>1.0 & x<1.25 & y>2.5 & y<2.75")
# 将时间戳转成时分秒格式
time_value=pd.to_datetime(data['time'],unit='s')
# 将时间转成字典格式
time_value=pd.DatetimeIndex(time_value)
data['day']=time_value.day
data['hour']=time_value.hour
# data['weekday']=time_value.weekday
data=data.drop(['time'],axis=1)
print(data)
# 将签到数量少于n个目标位置删除
place_count=data.groupby('place_id').count()
# tf保存的是place_id数量超过3的数据
tf=place_count[place_count.row_id>3].reset_index()
data=data[data['place_id'].isin(tf.place_id)]
# 取出数据中的特征值x(删除目标值)和目标值y
y =data['place_id']
x=data.drop(['place_id'],axis=1)
x=data.drop(['row_id'],axis=1)
# 进行数据的分割训练集测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
# 特征工程:对测试集和训练集的特征值进行标准化
std=StandardScaler()
x_train=std.fit_transform(x_train)
x_test=std.transform(x_test)
# 进行算法流程
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
# 得出预测结果
y_predict=knn.predict(x_test)
print("预测的目标签到位置为:",y_predict)
# 得出准确率
print("准确率:",knn.score(x_test,y_test))KNN总结:
KNN主要是受K值影响较大
k值取很小:容易受异常点影响
k值取很大:容易受k值数量(类别)波动
性能:
时间复杂度比较高(每个训练样本都需要计算距离)
KNN的可用性不高,主要是性能不太好
②朴素贝叶斯
算法概要:
一些概率知识:
联合概率:包含多个条件,且所有条件同时成立的概率P(A,B)=P(A)*P(B)
条件概率:在A条件下B发生的概率P(B|A)
朴素贝叶斯:最好特征独立(朴素:独立)
e.g:判断一个文档所属类别实际上就是求概率:
P(科技|文档)的值、P(娱乐|文档)的值,哪个值大就属于哪个类别
文档实际上就是一个一个词:词1、词2、词3
P(科技|文档)=P(科技|词1,词2,词3) 实际上这些词就是特征1,特征2,特征3
朴素贝叶斯公式:
$$
P(C|W)=\frac{P(W|C)P(C)}{P(W)}
$$
公式可以理解为:
$$
P(C|F1,F2,F3....)=\frac{P(F1,F2,F3...|C)P(C)}{P(F1,F2,F3....)}
$$
$$
P(F1,F2,F3...|C)=P(F1|C)P(F2|C)P(F3|C)....
$$
为了防止计算所属类别的概率为0,引入拉普拉斯平滑系数进行概率的计算
$$
P(F1|C)=\frac{Ni+\alpha}{N+\alpha*m}
$$
$$
\alpha一般为1,m为特征词的数量
$$
利用算法进行文本分类:
def naviebayes():
news=fetch_20newsgroups(subset='all')
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25)
tf=TfidfVectorizer()
x_train=tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test=tf.transform(x_test)
mlt=MultinomialNB(alpha=1.0)
print(x_train)
mlt.fit(x_train,y_train)
y_predict=mlt.predict(x_test)
print("预测的文章类别为:",y_predict)
print("准确率:",mlt.score(x_test,y_test))算法总结:
无法进行调优:里面没有参数可以进行优化
算法准确度与数据集关系较大,训练集不准确效果会不好
分类比较准确,对缺失数据不敏感
特征之间需要独立
③决策树
算法概要:
主要是一种选择if-then结构(树结构)
划分决策树依据:
信息增益:
决策树划分的依据之一,当得知一个特征条件之后,减少的信息上的大小(就是选取特征之后,可以减少选择信息的数量)
选择信息增益最大的特征作为最优特征(树的根)
基尼系数
sklearn中默认用这个划分
利用决策树预测titan的人员生存情况:
def decision():
titan=pd.read_csv("D:/study/postgraduate/data/tataini/train.csv")
# 处理数据 找出目标值和特征值
x=titan[['Pclass','Age','Sex']]
y=titan['Survived']
print(x)
x['Age'].fillna(x['Age'].mean(),inplace=True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行特征处理(输入的数据是String类型,将其转化为one-hot编码)
dict=DictVectorizer(sparse=False)
x_train=dict.fit_transform(x_train.to_dict(orient='records')) # to_dict()表示将数据中的一行转成一个字典
# print(dict.get_feature_names_out())
x_test=dict.transform(x_test.to_dict(orient='records'))
# print(x_train)
dec = DecisionTreeClassifier()
dec.fit(x_train,y_train)
print("准确率为:",dec.score(x_test,y_test))决策树总结:
优点:
比较简单易于理解,直接是树型结构
需要比较少的数据准备,其他算法通常需要对数据进行归一化处理
缺点:
数据最好不能太复杂,否则决策树会过大
改进:
剪枝cart算法(对叶子结点进行剪枝,当叶子结点的样本少于某个阈值时就将该叶子结点减掉)
随机森林
④随机森林
算法概要:
集成学习方法:生成多个分类器/模型,各自独立学习和作出预测,这些预测结合成最终的结果形成单个预测
随机森林就是多个决策树形成的分类器,输出的类别是由个别树输出的类别的众数而定
随机森林建立多个决策树的过程:(N个样本 M个特征)
单个树建立过程:(随机有放回的抽样)
随机从N个样本中选择一个样本,重复N次
随机从M个特征中选出m个特征
生成多个树形成森林
超参数:
生成的单个树的数目
树的深度(选择的特征数量)
算法代码及调优
# 利用随机森林进行预测
rf = RandomForestClassifier()
param={"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}
gc=GridSearchCV(rf,param_grid=param,cv=2)
gc.fit(x_train,y_train)
print("准确率:",gc.score(x_test,y_test))
print("查看选择的参数模型:",gc.best_params_)总结:
优点:
比较好的准确率
能够有效的运行在大数据上
能够处理高维特征的输入样本,而且不需要降维
能够评估各个特征在分类问题上的重要性