位图
这里借用鹅厂一道经典的面试题来开头:
如果给你 40 亿的不重复的无符号乱序排列的整数,再给你一个无符号整数,
如何快速判断这个数是否在这 40 亿个整数中?
首先我们先算一算存储 40 亿个数所需要的空间大小,unsigned 是 4 个字节,
也就是 40 亿 * 4 = 160 亿的字节,2 ^ 30 = 1G, 算下来接近 15G,这个代价未免也太大了,所以我们需要一个更加稳妥的方式去解决它。
这里我们就用到了 hash 位图。
原理
一个字节是 8 个 bit,所以我们可以开足够大小的 bit 来记录每一个数所对应的位置 (将对应的 bit 置 1),查找的话只要对应 bit 为 1 则证明其存在,删除的话 bit 置 0 即可,unsigned 的最大取值为 4294967295,开这么大的 bit 所占用的空间大小 才接近 500M,也就是半个G,空间使用高下立判。
注意点
位图只能用于处理整数,或者能够转换成整数的字符串等,不是整数位图就无能为力了。
代码实现
#include<iostream>#include<vector>#include<string>usingnamespace std;namespace My_Bit_Set{classSet{public:Set(size_t N)//开多大的bit 位{
_bit.resize(N/32+1,0);//多开一个字节的空间,假设存100个数,100/32=3,3个字节最大存储范围是96,要照顾97-100
_nums=0;}voidset(size_t x)//将bit位置1{
size_t index= x/32;//判断映射在哪一个整形空间
size_t pos= x%32;//判断在整形空间中所映射的具体位置
_bit[index]|=(1<< pos);++_nums;}voidreset(size_t x)//将bit位置0{
size_t index= x/32;
size_t pos= x%32;
_bit[index]&=~(1<< pos);--_nums;}boolfind(size_t x)//查找{
size_t index= x/32;
size_t pos= x%32;return _bit[index]&(1<< pos);}private:
vector<int> _bit;
size_t _nums;//记录隐射存储的数据个数};}布隆过滤器
概念
布隆过滤器是一种比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
特点
- 能准确判断该元素在位图中不存在
- 不能准确的判断该元素在位图中存在
- 即判不在准,判在不一定准 (比如 aadd 的ASCII 和 bbcc 的ASCII一致,可能会映射到同一个位置,所以需要使用多个位图和多个映射算法通过层层 “过滤” 来降低 hash 冲突,但是仍然无法彻底避免 hash 冲突)
- 传统的布隆过滤器不支持删除,从 3 知道多个元素可能会映射到同一个位置,因此要是一旦删除可能会影响其他元素,但是名为 Counting Bloom filter 的变种可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除。
实现原理
也就是 hash 映射 + 位图,用多个位图和多个不同的映射算法去将这个元素(字符串或者结构体) 映射到不同位图的不同位置,在根据关系在不同位图的不同位置进行判定,都在即可能存在,一处不在即一定不在。
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
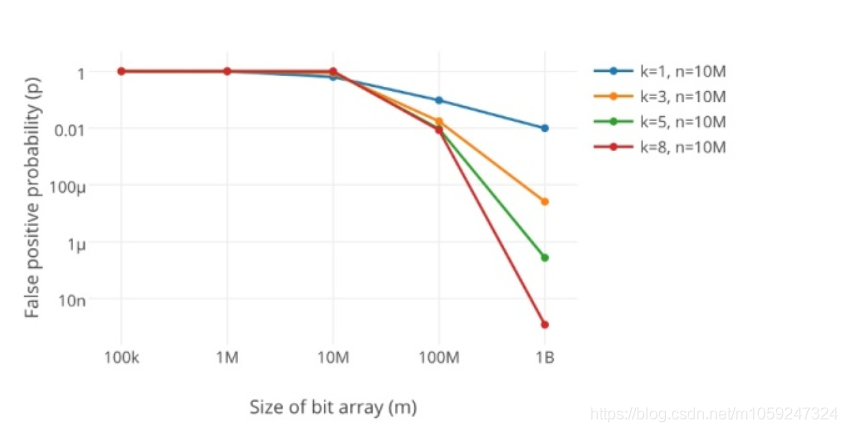
如何选择适合业务的 k 和 m 值呢,这里直接贴一个公式: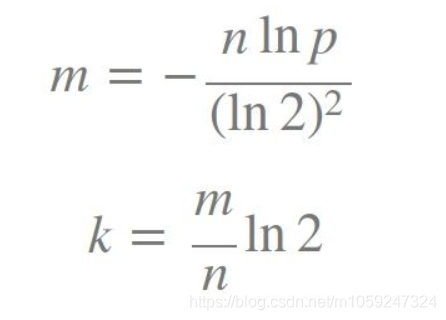
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。计算下来,m = 4.3 * n;也就是4.5 ~5倍。
代码实现
#pragma once#include"Set.h"namespace Bloom{struct HashStrtoI1//仿函数{
size_toperator()(const string& str){
size_t out=0;for(size_t i=0; i< str.size();++i){
out*=131;
out+= str[i];}return out;}};struct HashStrtoI2{
size_toperator()(const string& str){
size_t out=0;for(size_t i=0; i< str.size();++i){
out*=63689;
out+= str[i];}return out;}};struct HashStrtoI3{
size_toperator()(const string& str){
size_t out=0;for(size_t i=0; i< str.size();++i){
out*=65599;
out+= str[i];}return out;}};//K是整形 //T是字符串 后面的是几个字符串hash的映射函数template<classK,classT= string,classHash1= HashStrtoI1,classHash2= HashStrtoI2,classHash3= HashStrtoI3>classBloomFilter{public://这里的 5 是根据上面的公式计算出来的BloomFilter(size_t nums):_Bit(5* nums),_nums(5* nums){}voidBloomSet(const T& x){
size_t index1=Hash1()(x)% _nums;
size_t index2=Hash2()(x)% _nums;
size_t index3=Hash3()(x)% _nums;
_Bit.set(index1);
_Bit.set(index2);
_Bit.set(index3);}voidBloomSet(const K& key){
_Bit.set(key);}boolBloomFind(const T& x)//这里只是映射了3个位图,又仍然可能存在不同但是映射位置相同的字符串{
size_t index1=Hash1()(x)% _nums;if(_Bit.find(index1)==false)returnfalse;
size_t index2=Hash2()(x)% _nums;if(_Bit.find(index2)==false)returnfalse;
size_t index3=Hash3()(x)% _nums;if(_Bit.find(index3)==false)returnfalse;returntrue;}boolBloomFind(const K& key){return _Bit.find(key);}private:
My_Bit_Set::Set _Bit;
size_t _nums;};};几个位图和布隆过滤器常见的面试题
1.给定 100 亿个整数,设计算法找出只出现一次的整数
- 首先 100 亿个整数需要占用 40G 的空间,所以我们可以使用位图来标记每一个元素所出现的次数.
- 思路1,设置两个位图,当发现 1 号位图对应位置已经为 1 时就将 2 号位图的对应 bit 位置1(都为 1 则不管),这样只需要查找 1 号 bit 位为 1, 2 号bit 位不为 1 的即可.
- 思路2: 只用一个位图,但是用两个 bit 位标记一位整数, 出现 0 次的为 00,出现 1 次的为 01, 出现 2 次及其以上的用 11;
2.给两个文件,分别有 40 亿整数,而内存只有 1G,如何找到这两个文件的交集
- 思路1: 先将其中一个文件的数映射到一个位图中,在读取另一个文件中的数字去判断是否在第一个文件中,在的就是交集,消耗 500M 内存.
- 思路2 : 先将文件 1 映射到位图 1, 在把文件 2 映射到位图 2,二者在按位 &,消耗 1G 内存.
3.给两个文件,分别有 100 亿个 query ,只有 1G 内存,如何找到两个文件的交集 ? 给出精确算法和近似算法.
- query 是 sql 查询语句或者网络请求的 url 等,一般是一个字符串,假设平均一个 query 30-60 字节, 100 亿个需要 300G - 600G.
-思路1: 先将其中一个文件的 query 映射到一个位图中,在读取另一个文件中的 query 去判断是否在第一个文件中; 缺陷: 求出来的交集不准确,因为只有一个位图,难免会有不同的 query 映射到相同的位置,这就不能保证准确性. - 思路2: hash 切分, 将 300G - 600G的大文件切分 1000 份,就会变成 300M - 600M的小文件,在将这些小文件加载到内存中去, i = hashstr(query) % 1000; i 是多少,就分别进入 Ai 和 Bi 多对应的小文件中去,这样就能保证 A和B 文件中相同的 query 一定会进入相同下标的对应 A 或 B 小文件中去,再将 Ai 中的 query 放入 set 中,读取对应 Bi 小文件中的 query,看是否存在于 Ai 中,即所求的交集.