温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
在前面的文章Fayson介绍了《Hive创建外部表CSV数据中列含有逗号问题处理》。本篇文章Fayson主要介绍在Hive中使用Map类型存储数据。
内容概述
1.环境准备
2.创建Hive表及测试
3.总结
- 测试环境
1.CM和CDH版本为5.15
2.环境准备
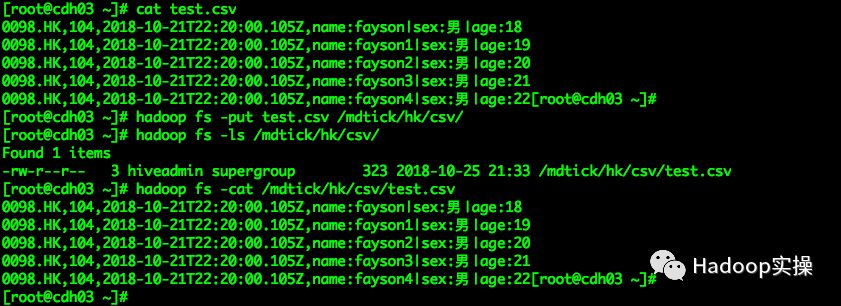
准备测试数据,文本数据内容如下:
0098.HK,104,2018-10-21T22:20:00.105Z,name:fayson|sex:男|age:180098.HK,104,2018-10-21T22:20:00.105Z,name:fayson1|sex:男|age:190098.HK,104,2018-10-21T22:20:00.105Z,name:fayson2|sex:男|age:200098.HK,104,2018-10-21T22:20:00.105Z,name:fayson3|sex:男|age:210098.HK,104,2018-10-21T22:20:00.105Z,name:fayson4|sex:男|age:22将准备好的测试数据保存到test.csv文件中,并上传至HDFS的/mdtick/hk/csv目录下。
[root@cdh03~]# cat test.csv[root@cdh03~]# hadoop fs-put test.csv/mdtick/hk/csv/[root@cdh03~]# hadoop fs-ls/mdtick/hk/csv/[root@cdh03~]# hadoop fs-cat/mdtick/hk/csv/test.csv(可左右滑动)
3.创建Hive表
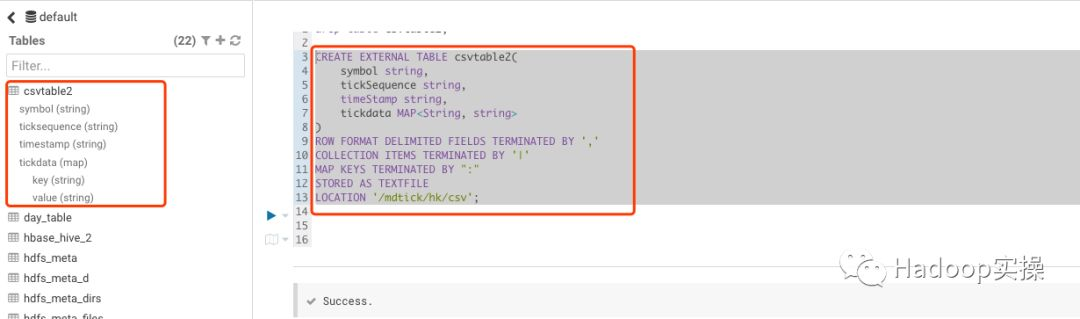
1.使用如下SQL语句创建一个包含Map类型的表
CREATEEXTERNALTABLEcsvtable2(
symbol string,
tickSequence string,
timeStamp string,
tickdataMAP<String, string>)ROWFORMATDELIMITEDFIELDSTERMINATEDBY','COLLECTIONITEMSTERMINATEDBY'|'MAPKEYSTERMINATEDBY":"STOREDASTEXTFILELOCATION'/mdtick/hk/csv';(可左右滑动)
如上SQL建表语句中需要注意的是,Map类型里面定义了Key和Value的数据类型。Map类型中定义的字段与示例数据中的“name:fayson|sex:男|age:18”,该数据以k-v方式存储。Collection items terminated by “|”,表示Map中每个kv直接以”|”分割,MAP KEYS TERMINATED BY “:”,表示kv之间数据以“:”分割。
2.使用Hue在Hive中创建测试表
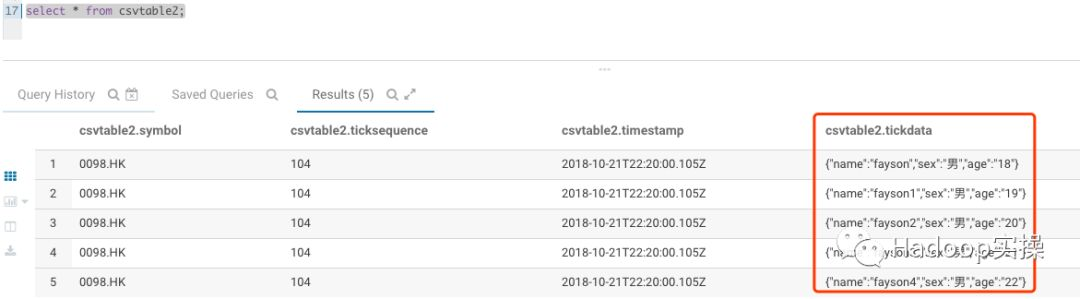
3.使用SQL命令查看csvtable2表数据
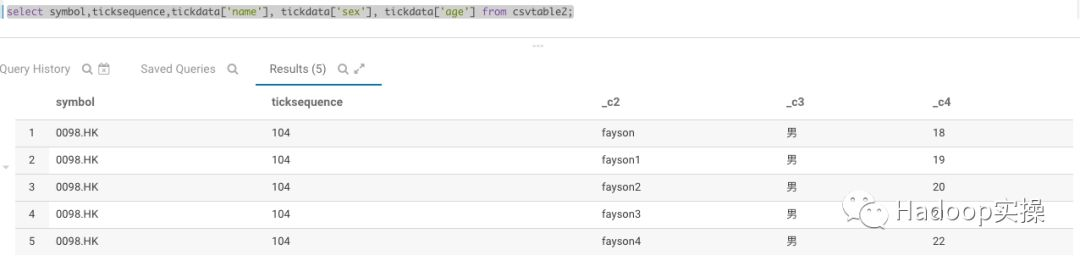
4.使用SQL语句查看Map中数据
select symbol,ticksequence,tickdata['name'], tickdata['sex'], tickdata['age']from csvtable2;(可左右滑动)
4.总结
1.在Hive表中定义Map类型数据,Map只能以K-V的方式定义一批数据的数据类型,与Struct相比对每个字段的类型定义没有那么灵活。
2.使用SQL语句查询Map中数据时需要指定查询字段的key。
3.同样Map也是支持嵌套数据格式Map<String,>等。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。