hive复杂数据类型有三种,map,array,struct。本文会详细介绍三种类型数据的建表、查询、相关函数以及与其他数据类型的相互转换。
目录
一、简介
map 是一种(key-value)键值对类型;
array 是一种数组类型,array 中存放相同类型的数据;
struct 是一种集合类型。
二、建表语句
createtable demo_class(
name string,
score array<int>,
result map<string,int>,
class struct<id:int, grade:string>)row format delimitedfieldsterminatedby'\t'#列分隔符
collection itemsterminatedby'|'#每个map,struct,array 数据之间的分隔符,三种类型的数据统一用一个
mapkeysterminatedby':'#map 中的key与value的分隔符linesterminatedby'\n'#行分隔符
storedas textfile;查看表结构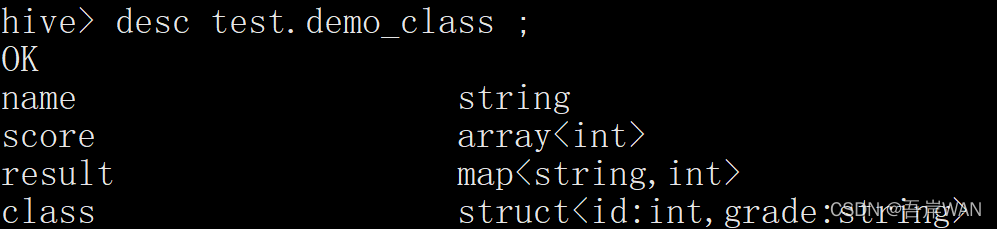
打开文件写入三行数据
vim /root/tmp/demo_class.txt
注意分隔符要与建表语句一致,如此表指定每列字段之间用tab分割,数据之间用“|”分隔,map的key与value之间用冒号“:”分隔,回车换行
a 90|92 math:90|english:92 1|genius
b 80|60 math:80|english:60 2|excellent
c 50|66 math:50|english:66 3|fighting
将数据载入表中
loaddatalocal inpath'/root/tmp/demo_class.txt' overwriteintotable test.demo_class;查看三种数据类型的数据
三、类型构建
array(val1, val2,…)
map(key1, value1, key2, value2,…)
struct(val1, val2, val3,…)
select
array(90,92)as score,
map('math',90,'english',92)as result,
struct(1,'genius')as class[90,92] {“math”:90,“english”:92} {“col1”:1,“col2”:“genius”}
四、查询
array类型
1.数据访问
语法: A[n]
操作类型: A为array类型,n为int类型
说明:返回数组A中的第n个变量值,数组的起始下标为0
select score, score[0], score[1]from demo_class;[90,92] 90 92
[80,60] 80 60
[50,66] 50 66
2.size()函数可以查询数组中元素的个数,下标超过长度返回null 值
[90,92] 2 NULL
[80,60] 2 NULL
[50,66] 2 NULL
select score, size(score), score[3]from demo_class;3.array_contains()函数可以查询数组中是否包含某个元素
array_contains(数组名,值)
返回 true 或 false
select score, array_contains(score,90)from demo_class;[90,92] true
[80,60] false
[50,66] false
map类型
1.数据访问
语法: M[key]
操作类型: M为map类型,key为map中的key值
说明:返回map类型M中key值为指定值的value值
select result, result['math'], result['english']from demo_class;{“math”:90,“english”:92} 90 92
{“math”:80,“english”:60} 80 60
{“math”:50,“english”:66} 50 66
2.获取map中的键、值
map_keys()
map_values()
select map_keys(result), map_values(result)from demo_class;[“math”,“english”] [90,92]
[“math”,“english”] [80,60]
[“math”,“english”] [50,66]
3.size()函数获取map中键值对的个数
select result, size(result)from demo_class;{“math”:90,“english”:92} 2
{“math”:80,“english”:60} 2
{“math”:50,“english”:66} 2
4.查询map中是否包含某个键、值
array_contains(map_keys(字段名), 键名)
array_contains(map_values(字段名), 值名)
select result, array_contains(map_keys(result),'math')from demo_class;select result, array_contains(map_values(result),90)from demo_class;结果分别为
{“math”:90,“english”:92} true
{“math”:80,“english”:60} true
{“math”:50,“english”:66} true
{“math”:90,“english”:92} true
{“math”:80,“english”:60} false
{“math”:50,“english”:66} false
可以当做where 过滤条件,如选取所有result 值为90的数据
select*from demo_classwhere array_contains(map_values(result),90);struct类型
语法: S.x
操作类型: S为struct类型
说明:返回集合S中的x字段
select class, class.id, class.gradefrom demo_class;{“id”:1,“grade”:“genius”} 1 genius
{“id”:2,“grade”:“excellent”} 2 excellent
{“id”:3,“grade”:“fighting”} 3 fighting
五、与其他数据类型转换
将array和map转化为基本数据类型(行转列)
explode()
函数将一列array 或者map 结构拆分成多行
select explode(score)from demo_class;数据
[90,92]
[80,60]
[50,66]
变为
90
92
80
60
50
66
每一个数据单独成行
select explode(result)from demo_class;数据由
{“math”:90,“english”:92}
{“math”:80,“english”:60}
{“math”:50,“english”:66}
变为
math 90
english 92
math 80
english 60
math 50
english 66
key值和value值被分成两列,每一个键值对单独成行
explode 函数如果要和其他字段一起查询,则需借助lateral view 语句。lateral view首先为原始表的每行调用函数,函数会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表
lateral view udtf(expression) tableAlias AS columnAlias
select name, score, score_efrom demo_class
lateralview explode(score) vas score_e;
select name, result, result_key, result_valuefrom demo_class
lateralview explode(result) vas result_key, result_value;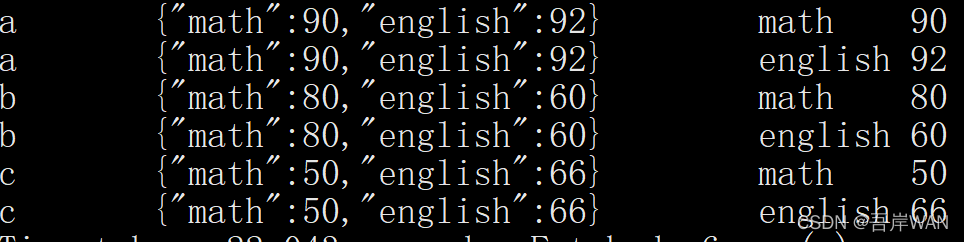
基本数据类型转化为array、map(列转行)
1.转为array
collect_set()
函数接受基本数据类型,将某字段的值进行去重汇总,产生array类型的字段。一般需要配合group by一起使用,聚合非分组字段
collect_list() 函数作用同上,但是不去重
如将int 类型的字段score 转化为array 类型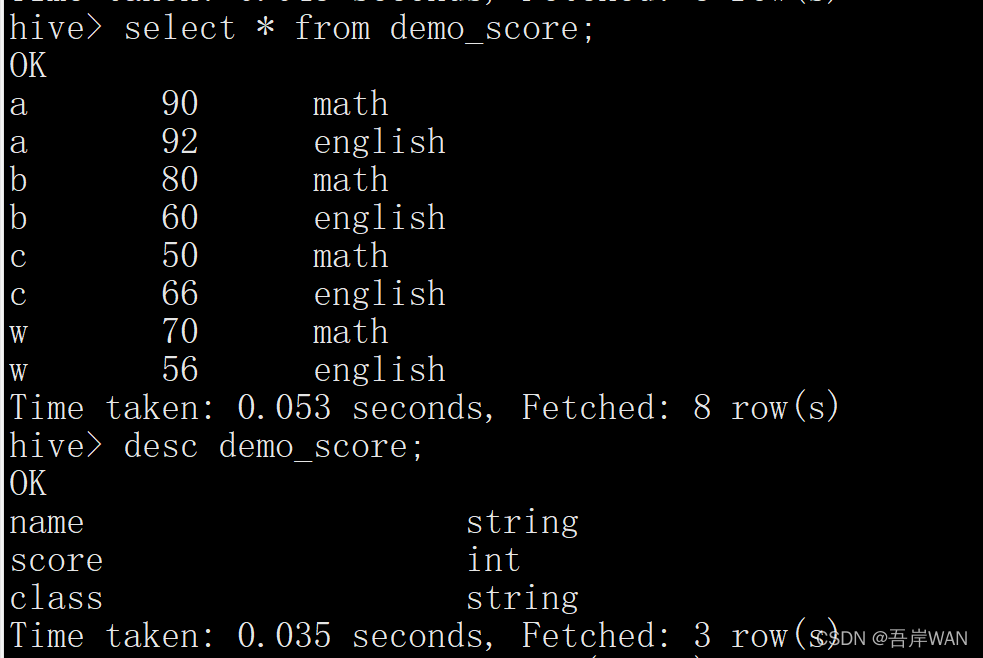
select name, collect_set(score)from demo_scoregroupby name;a [90,92]
b [80,60]
c [50,66]
w [70,56]
collect_set() 常与concat_ws() 连用,用于列转行,可以改变连接符号,但返回值是字符串string 类型
concat_ws(separator, [string | array(string)]+)
函数只接受字符串和数组类型,将字段和分隔符拼接为数组
select name, concat_ws('-', collect_set(class))from demo_scoregroupby name;a math-english
b math-english
c math-english
w math-english
2.转为map
str_to_map() 函数将字符类型数据,转化成map格式的数据
str_to_map(text, delimiter1, delimiter2)
delimiter1 将文本分隔为键值对,delimiter2 用来分隔key 和value。如果没有指定分隔符,默认 delimiter1 为’,’ ,delimiter2 为’=’。
select str_to_map("math:90-english:92","-",":");{“english”:“92”,“math”:“90”}