最近训练一个BP神经网络做回归,发现拟合效果很烂,甚至我用单样本训练竟然还是欠拟合。然后我昨天晚上发现,这个预测结果,随着我epoch次数的增加,最后所有预测结果会趋同。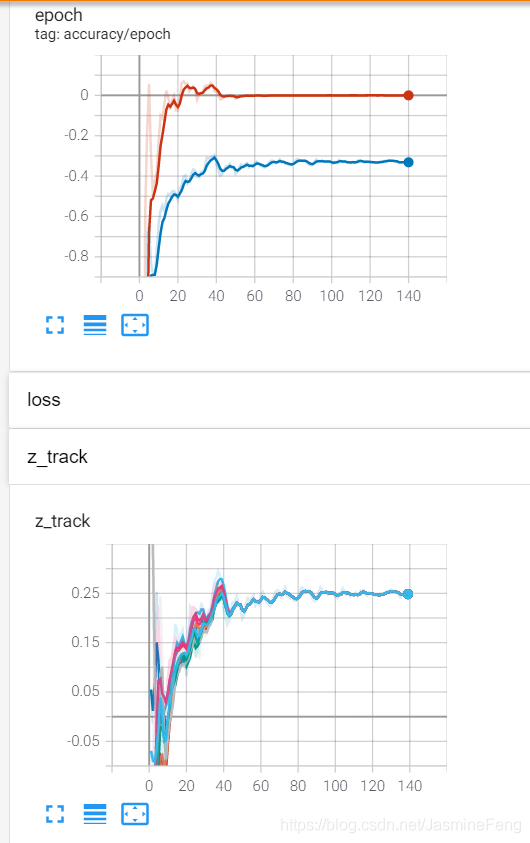
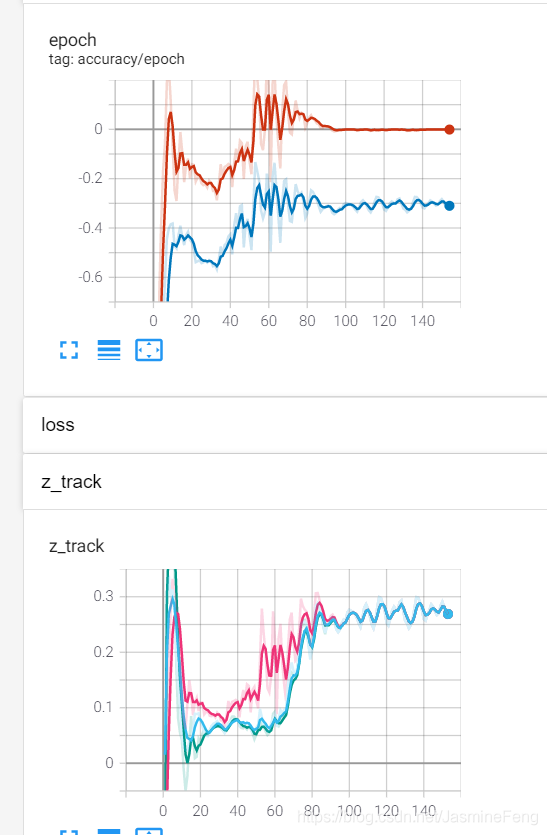
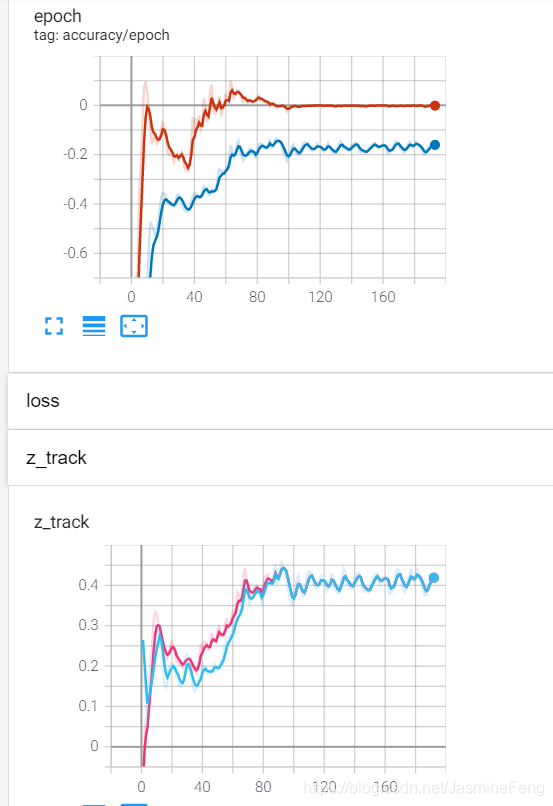
这边一共放了三张大图,每张大图里面有两张小图,上面的小图记录了train accuracy(红)和test accuracy(蓝),评价标准是R square;下面的小图是我追踪的预测结果。三次训练分别是10、3、2个样本。
可以很明显看到,训练集上的R square最后趋近于0,
R
2
=
1
−
R
S
S
T
S
S
R^2=1-\frac{RSS}{TSS}R2=1−TSSRSS
当
R
2
=
0
有
R
S
S
=
T
S
S
当R^2=0 有RSS=TSS当R2=0有RSS=TSS
即
∑
i
(
y
i
−
y
^
)
2
=
∑
i
(
y
i
−
y
ˉ
)
2
即\sum_i (y_i-\hat{y})^2=\sum_i (y_i-\bar{y})^2即i∑(yi−y^)2=i∑(yi−yˉ)2
这也就是说我的预测值跟真实的平均值一模一样了,从下面的三张小图可以看出来确实如此,最后所有预测值合并成一条曲线了。
其实我到现在也没明白为啥会这样,我是用MSE作损失函数的呀,又没拿R平方当损失函数,为啥它最后会趋于零呢???
我的网络结构是这样的:
- Layer1: Linear(7,1) —> BatchNorm —> ReLU —> Dropout
- Layer2: Linear(1,100) —> BatchNorm —> ReLU —> Dropout
- Layer3: Linear(100,150) —> BatchNorm —> ReLU —> Dropout
- Last_layer : Linear(150,1)
按理说这四层应该能拟合绝大部分函数了,但为什么还是会欠拟合呢,而且最后预测值还一毛一样???
我今天早晨又调试了一下,我明白他是怎么预测出全部相同的了。
这玩意儿,每一层学习出来的权重W都是10^-3数量级的,bias好多都是0,这就导致了Layer3在做完Dropout后,想Last_layer输入的x全是0,然后Last_layer轻轻松松就让所有的预测值相同了,通过bias。
我吐了呀,没想到神经网络这么心机。
我还发现梯度好像很小,有梯度消失之嫌。
这个时候我突然想起来以前看过BatchNorm和Dropout同时存在会导致训练更差的推文:“BN和Dropout单独使用都能减少过拟合并加速训练速度,但如果一起使用的话并不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果。”
推文链接
然后我就删掉了Dropout层,同时调大了学习率(抵抗梯度消失)。
然后现在R平方总算能达到0.5了,我好开心。
但是不得不承认神经网络对我真是玄学,希望懂的大佬能给我解释解释为啥R平方原来会趋于零,不胜感激【抱拳】。