数据分析步骤提出问题理解数据清洗数据构建模型数据可视化
1. 提出问题
- 月均消费次数
- 月均消费金额
- 客单价
- 消费趋势
2. 理解数据
- 读取excel数据
path='C:UserszhuoguanqunDesktoppython学习资料第3关:数据分析的基本过程朝阳医院2018年销售数据.xlsx'
excel=pd.ExcelFile(path,dtype='object')
salesdf=excel.parse('Sheet1',dtype='object')2. 打印前11 行:salesdf.head(11)
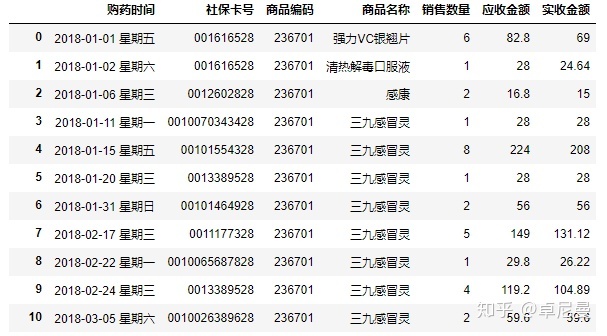
有多少行,多少列:saledf.shape
(6578, 7)
查看列的数据类型:salesdf.dtypes

3. 清洗数据
- 选择子集
#本案例不需要选择子集
salesdf.loc[0:11,'购药时间':'实收金额']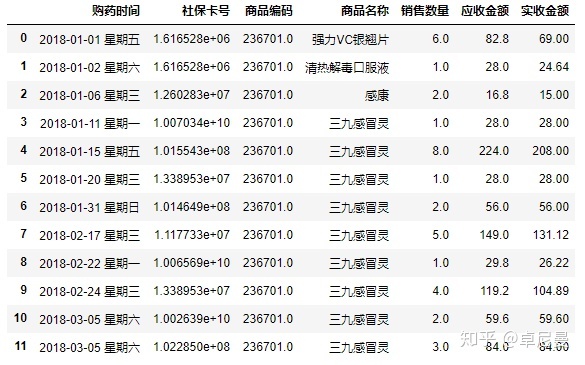
2. 列重命名
#inplace=False,数据框本身不会变,而是创建一个改动后的新的数据框,inplace默认是False,
#inplace=Ture,数据框本身会改动。
colname={'购药时间':'销售时间'}
salesdf.rename(columns=colname,inplace=True)
salesdf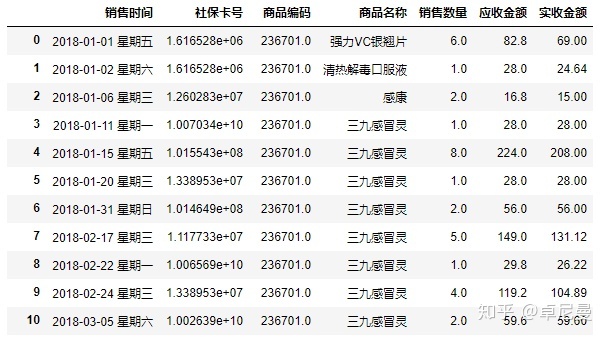
3. 缺失值处理
print('删除前',salesdf.shape)
salesdf=salesdf.dropna(subset=['销售时间','社保卡号'],how='any')
print('删除后',salesdf.shape)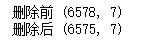
4. 数据类型转换
- 字符串转换为数值(浮点数)
salesdf[['销售数量']]=salesdf[['销售数量']].astype('float')
salesdf[['应收金额']]=salesdf[['应收金额']].astype('float')
salesdf[['实收金额']]=salesdf[['实收金额']].astype('float')
salesdf.dtypes
- 处理日期
#字符串用split分割后为List
def sptime(time):
timelist=[]
for i in time:
time1=i.split(' ')[0]
timelist.append(time1)
timeser=pd.Series(timelist)
return timeser
salesdf['销售时间']=sptime(salesdf['销售时间'])
salesdf.head()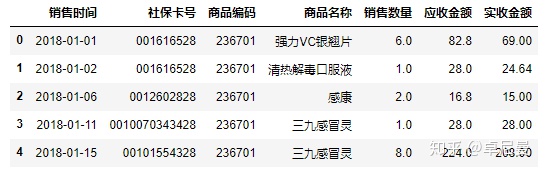
将日期的字符串格式改为日期格式
# format是原始数据中的格式,error='coerce'如果数据格式不符合,转换后为NaT
salesdf['销售时间']=pd.to_datetime(salesdf['销售时间'],format='%Y-%m-%d',errors='coerce')
salesdf.dtypes
修改为日期格式后有可能会出现缺失值
print('删除前',salesdf.shape)
salesdf=salesdf.dropna(subset=['销售时间'],how='any')
print('删除后',salesdf.shape)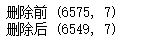
5. 数据排序
#排序,ascending为True是为升序,为False时为降序,by按哪几列排序,str或list
salesdf=salesdf.sort_values(by='销售时间',ascending='True')
salesdf.head()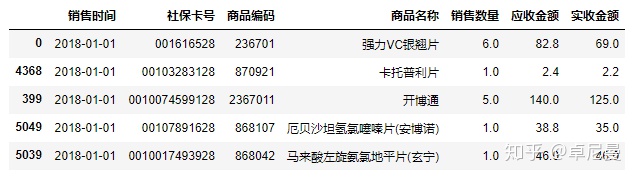
重命名行号(index)
#drop=True: 把原来的索引index列去掉,丢掉。
#drop=False:保留原来的索引(以前的可能是乱的)
salesdf.reset_index(drop=True)
salesdf.head()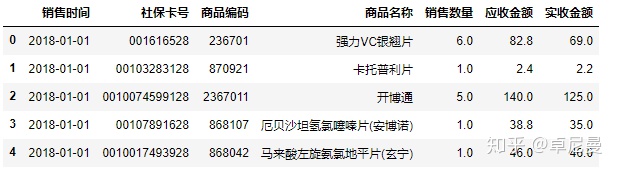
6. 异常值处理
#每一列的描述统计信息
salesdf.describe()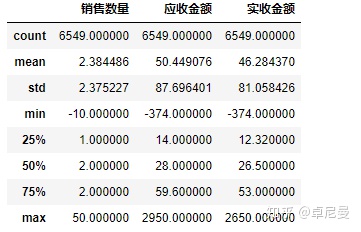
通过条件筛选判断
print('删除前',salesdf.shape)
salesdf=salesdf[salesdf.loc[:,'销售数量']>0]
print('删除后',salesdf.shape)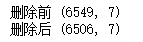
4. 构建模型
- 月均消费次数=总消费次数/月份数、
同一天内,同一个人发生的所有消费算作一次消费
#删除重复数据,获得总消费次数
salesdf=salesdf.drop_duplicates(subset=['销售时间','社保卡号'])
salesdf.shape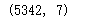
总消费次数=5342
startdate=salesdf.loc[0,'销售时间']
enddate=salesdf.loc[endline-1,'销售时间']
days=(enddate-startdate).days
monthes=days//30
print('月份数',monthes)
#月均消费次数
print('月均消费次数=',total//monthes)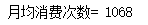
- 月均消费金额=总消费金额/月份数
money=salesdf.loc[:,'实收金额'].sum()
monthmoney=money/monthes
print('月均消费金额='+ str(monthmoney))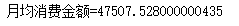
- 客单件=总金额/总消费次数
#客单价
print('客单价='+str(money/total))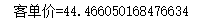
- 消费趋势
看每月的销售额
#提取月份
salesdf['月份']=salesdf['销售时间'].dt.month
salesdf.head()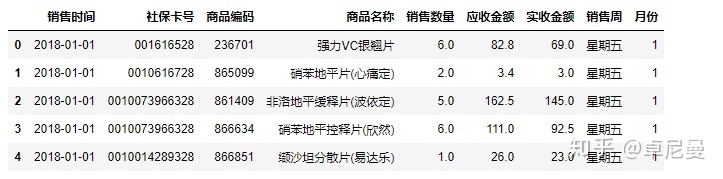
#获取每月的销量、应收金额和实收金额的和
#因为七月份的不全,所以去掉该月份的数据
month=salesdf.groupby('月份').agg('sum')
month=month.reset_index(drop=False)
month=month.drop(axis=1,index=6)
month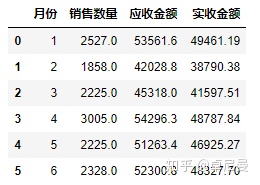
5. 数据可视化
5.1 消费趋势
根据每月的销售数量、应收金额和实收金额。
ax1=month.plot(x='月份',y='实收金额',marker='o',linewidth=3)
month.plot('月份','应收金额',ax=ax1,marker='o',linewidth=3)
plt.title('1-6月销售金额趋势')
plt.grid(True)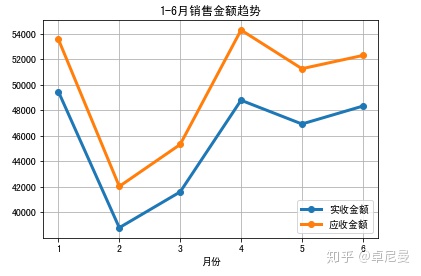
month.plot('月份','销售数量',marker='o',linewidth=3)
plt.title('1-6月份销售数量趋势变化')
plt.grid(True)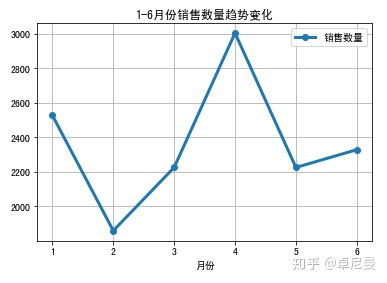
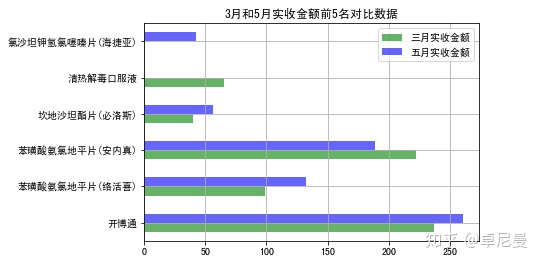
结论:二月份销售额和销售数量都很低,因为数据原因,不进一步探索。三月份销量和五月份销量基本一致,销售额差距较大。通过对比3月和5月前五实收金额可以看到只有苯磺酸氨氯地平片(络活喜)是高于5月,其他4种均低于5月。
5.2 一周中每天的实收金额和应收金额
ax1=sum.plot('销售周','实收金额',marker='o')
sum.plot('销售周','应收金额',ax=ax1,marker='o')
plt.grid(True)
# X坐标轴值显示
x=range(7)
plt.xticks(x,sum['销售周'])
plt.xlabel(' ')
plt.show()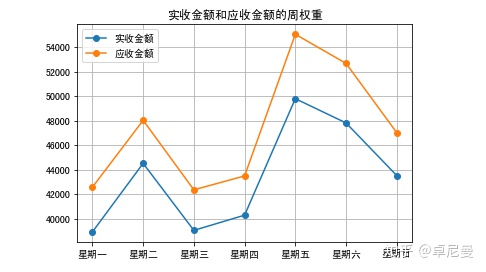
结论:一周中周一、周三和周四销售额最低,适合调整陈列,部署送货。周五周六是销售高峰。