同步容器与并发容器
一、同步容器
在Java的集合框架中,主要有四大类别:List、Set、Queue、Map(它们全部都是接口)。
Collection和Map是一个顶层接口,而List、Set、Queue则继承了Collection接口,分别代表数组、集合和队列这三大类容器。
对于List、Set、Queue、Map来说,它们的实现类有的并不是线程安全的。比如ArrayList、LinkedList、HashMap等容器, 如果有多个线程并发地访问这些容器时,就会出现问题,所以,Java提供了同步容器供用户使用。
在Java中,同步容器主要包括2类:
1)Vector、Stack、HashTable
2)Collections类中提供的静态工厂方法创建的类
Vector实现了List接口,Vector实际上就是一个数组,和ArrayList类似,但是Vector中的方法都是synchronized方法,即进行了同步措施。
Stack也是一个同步容器,它的方法也用synchronized进行了同步,它实际上是继承于Vector类。
HashTable实现了Map接口,它和HashMap很相似,但是HashTable进行了同步处理,而HashMap没有。
Collections类是一个工具提供类,注意,它和Collection不同,Collection是一个顶层的接口。
在Collections类中提供了大量的方法,比如对集合或者容器进行排序、查找等操作。最重要的是,JDK1.2 提供了Collections.synchronizedXxx等工程方法,将普通的容器继续包装。对每个共有方法都进行同步。
Collection类中提供了多个synchronizedXxx方法,该方法返回指定集合对象对应的同步对象。synchronizedXxx方法本质是对相应容器的包装。
Collections. syhchronizedXXX(List、set、Map)我们下面演示一下同步容器的使用:
同步容器Vector
import com.google.common.collect.Lists;import lombok.extern.slf4j.Slf4j;import java.util.Collections;import java.util.List;import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Semaphore;@Slf4jpublicclassCollectionsExample1{// 请求总数publicstaticint clientTotal=5000;// 同时并发执行的线程数publicstaticint threadTotal=200;privatestatic List<Integer> list= Collections.synchronizedList(Lists.newArrayList());publicstaticvoidmain(String[] args)throws Exception{
ExecutorService executorService= Executors.newCachedThreadPool();final Semaphore semaphore=newSemaphore(threadTotal);final CountDownLatch countDownLatch=newCountDownLatch(clientTotal);for(int i=0; i< clientTotal; i++){finalint count= i;
executorService.execute(()->{try{
semaphore.acquire();update(count);
semaphore.release();}catch(Exception e){
log.error("exception", e);}
countDownLatch.countDown();});}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", list.size());}privatestaticvoidupdate(int i){
list.add(i);}}
同步容器HashTable
import lombok.extern.slf4j.Slf4j;import java.util.HashMap;import java.util.Hashtable;import java.util.Map;import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Semaphore;@Slf4jpublicclassHashTableExample{// 请求总数publicstaticint clientTotal=5000;// 同时并发执行的线程数publicstaticint threadTotal=200;privatestatic Map<Integer, Integer> map=newHashtable<>();publicstaticvoidmain(String[] args)throws Exception{
ExecutorService executorService= Executors.newCachedThreadPool();final Semaphore semaphore=newSemaphore(threadTotal);final CountDownLatch countDownLatch=newCountDownLatch(clientTotal);for(int i=0; i< clientTotal; i++){finalint count= i;
executorService.execute(()->{try{
semaphore.acquire();update(count);
semaphore.release();}catch(Exception e){
log.error("exception", e);}
countDownLatch.countDown();});}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", map.size());}privatestaticvoidupdate(int i){
map.put(i, i);}}
值得注意的是同步容器使用不当会出事情,比如下面的演示
import java.util.Vector;publicclassVectorExample2{privatestatic Vector<Integer> vector=newVector<>();publicstaticvoidmain(String[] args){while(true){for(int i=0; i<10; i++){
vector.add(i);}
Thread thread1=newThread(){publicvoidrun(){for(int i=0; i< vector.size(); i++){
vector.remove(i);}}};
Thread thread2=newThread(){publicvoidrun(){for(int i=0; i< vector.size(); i++){
vector.get(i);}}};
thread1.start();
thread2.start();}}}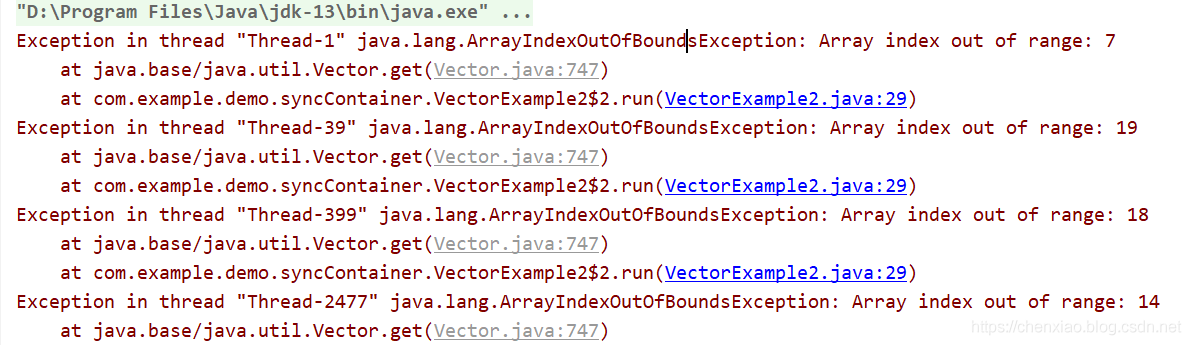
get越界肯定是remove引起的
当某个线程执行get()时候,有remove的执行 导致越界,需要做额外的措施。
这个也揭示了同步容器(如Vector)并不是所有操作都线程安全,这个可是面试常常考察的一个点,好好看一下吧:
虽然同步容器中的所有自带方法都是线程安全的(因为方法都使用synchronized关键字标注),但是,对这些集合类的复合操作无法保证其线程安全性。需要客户端通过主动加锁来保证。
像Vector这样的同步容器的所有共有方法全都是synchronized的,也就是说,我们可以在多线程场景中放心的使用单独这些方法,因为这些方法本身的确是线程安全的,但是复合操作无法保证线程安全。
以上面的例子为例,我们一边遍历元素,一边删除元素。
对于删除元素,执行的代码如下:
publicsynchronized Eremove(int index){
modCount++;if(index>= elementCount)thrownewArrayIndexOutOfBoundsException(index);
E oldValue=elementData(index);int numMoved= elementCount- index-1;if(numMoved>0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--elementCount]= null;// Let gc do its workreturn oldValue;}从上面代码中可以看出,当index >= elementCount时,会抛出ArrayIndexOutOfBoundsException。
为了避免出现类似问题,可以将遍历与删除封装在一个类中(静态内部类,或者类中静态方法),进行加锁处理即可。
关于Collections工具类中提供的synchronizedXxx方法,这里不再演示了,因为我之前写过:
参考【Java并发编程】线程不安全类 (含解决) 第三部分
二、并发容器
再说并发容器之前,要先谈谈同步容器与并发容器之间的关系:
同步容器可以简单地理解为通过synchronized来实现同步的容器。同步容器会导致多个线程中对容器方法调用的串行执行,降低并发性,因为它们都是以容器自身对象为锁,所以在需要支持并发的环境中,可以考虑使用并发容器来替代。
并发容器是针对多个线程并发访问而设计的,在jdk5.0引入了concurrent包,其中提供了很多并发容器,如ConcurrentHashMap、CopyOnWriteArrayList等。
同步容器与并发容器都为多线程并发访问提供了合适的线程安全,不过并发容器的可扩展性更高。例如,在ConcurrentHashMap中采用了一种粒度更细的加锁机制,可以称为分段锁,在这种锁机制下,允许任意数量的读线程并发地访问map,并且执行读操作的线程和写操作的线程也可以并发的访问map,同时允许一定数量的写操作线程并发地修改map,所以它可以在并发环境下实现更高的吞吐量,另外,并发容器提供了一些在使用同步容器时需要自己实现的复合操作,但是由于并发容器不能通过加锁来独占访问,所以我们无法通过加锁来实现其他复合操作了。
下面我们看一下并发容器
CopyOnWriteArrayList(CopyOnWrite写时复制一份新的,在新的上面修改,然后把引用指向新的。只能实现数据的最终一致性,非实时一致的;代替List,适用于读操作为主的情况,整个操作下都是在锁的保证下)
缺点是:
- 由于写操作的时候要进行copy,会消耗内存。
- 虽然最终能满足最终一致性,但是不能用于实时读。
设计思想如下
- 读写分离
- 最终一致性
- 使用的时候另外开辟空间
演示:
import lombok.extern.slf4j.Slf4j;import java.util.ArrayList;import java.util.List;import java.util.concurrent.CopyOnWriteArrayList;//JUCimport java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Semaphore;@Slf4jpublicclassCopyOnWriteArrayListExample{// 请求总数publicstaticint clientTotal=5000;// 同时并发执行的线程数publicstaticint threadTotal=200;privatestatic List<Integer> list=newCopyOnWriteArrayList<>();publicstaticvoidmain(String[] args)throws Exception{
ExecutorService executorService= Executors.newCachedThreadPool();final Semaphore semaphore=newSemaphore(threadTotal);final CountDownLatch countDownLatch=newCountDownLatch(clientTotal);for(int i=0; i< clientTotal; i++){finalint count= i;
executorService.execute(()->{try{
semaphore.acquire();update(count);
semaphore.release();}catch(Exception e){
log.error("exception", e);}
countDownLatch.countDown();});}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", list.size());}privatestaticvoidupdate(int i){
list.add(i);}}
CopyonArraySet (对应的是 HashSet),底层实现是数组,设计思想与CopyOnWriteArrayList相似
ConcurrentskipListSet(对应的是TreeSet),支持自然排序,并且在构造的时候能够自己定义比较器,和其他Set一样,底层基于Map集合,在多线程环境下,想addAll()等多批操作并不能保证以原子性执行,因为底层还是调用单操作的方法比如add()。要想实现批操作,可以手动加锁。
演示:
import lombok.extern.slf4j.Slf4j;import java.util.Set;import java.util.concurrent.CopyOnWriteArraySet;import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Semaphore;@Slf4jpublicclassCopyOnWriteArraySetExample{// 请求总数publicstaticint clientTotal=5000;// 同时并发执行的线程数publicstaticint threadTotal=200;privatestatic Set<Integer> set=newCopyOnWriteArraySet<>();publicstaticvoidmain(String[] args)throws Exception{
ExecutorService executorService= Executors.newCachedThreadPool();final Semaphore semaphore=newSemaphore(threadTotal);final CountDownLatch countDownLatch=newCountDownLatch(clientTotal);for(int i=0; i< clientTotal; i++){finalint count= i;
executorService.execute(()->{try{
semaphore.acquire();update(count);
semaphore.release();}catch(Exception e){
log.error("exception", e);}
countDownLatch.countDown();});}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", set.size());}privatestaticvoidupdate(int i){
set.add(i);}}
演示二:
import lombok.extern.slf4j.Slf4j;import java.util.Set;import java.util.concurrent.ConcurrentSkipListSet;import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Semaphore;@Slf4jpublicclassConcurrentSkipListSetExample{// 请求总数publicstaticint clientTotal=5000;// 同时并发执行的线程数publicstaticint threadTotal=200;privatestatic Set<Integer> set=newConcurrentSkipListSet<>();publicstaticvoidmain(String[] args)throws Exception{
ExecutorService executorService= Executors.newCachedThreadPool();final Semaphore semaphore=newSemaphore(threadTotal);final CountDownLatch countDownLatch=newCountDownLatch(clientTotal);for(int i=0; i< clientTotal; i++){finalint count= i;
executorService.execute(()->{try{
semaphore.acquire();update(count);
semaphore.release();}catch(Exception e){
log.error("exception", e);}
countDownLatch.countDown();});}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", set.size());}privatestaticvoidupdate(int i){
set.add(i);}}
ConcurrentskipListSet 有很多的学问在里面
ConcurrentHashMap(对应的是 HashMap),它不允许空值,在真正使用的时候除了少数的插入操作和删除操作更多的是读取操作,在读操作ConcurrentHashMap做了大量的优化 ,在高并发下具有非常优秀的表现,这个与HashMap放在一起是面试的重点,决定单独列一个章节好好介绍一番。
ConcurrentskipListMap(对应的是 TreeMap),内部的数据结构是跳表,相比ConcurrentHashMap,key是有序的,支持更高的并发,存取时间方面和线程数几乎没有关系。
import lombok.extern.slf4j.Slf4j;import java.util.Map;import java.util.concurrent.ConcurrentHashMap;import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Semaphore;@Slf4jpublicclassConcurrentHashMapExample{// 请求总数publicstaticint clientTotal=5000;// 同时并发执行的线程数publicstaticint threadTotal=200;privatestatic Map<Integer, Integer> map=newConcurrentHashMap<>();public