Spark SQL执行的总体流程
我们知道SparkSQL最终会把API和SQL语句转换成Spark Core的RDD代码来执行。那么这个转换过程是怎样的呢?本文介绍可执行代码生成的总体流程。
总体流程
可执行代码的生成过程(也是使用Catalyst对表达式进行创建、优化、转换的过程)主要经历以下几个阶段:
(1) 起始逻辑计划的生成
(2) 使用Catalyst来分析逻辑计划,并解析引用
(3) 优化逻辑计划
(4) 生成一个或多个物理计划
(5) 优化物理执行计划
(6) 生成可执行代码
在物理规划阶段,Catalyst 可能会生成多个计划并根据成本进行比较。 所有其他阶段完全基于规则。 每个阶段使用不同类型的树节点; Catalyst 包括用于表达式、数据类型以及逻辑和物理运算符的节点库。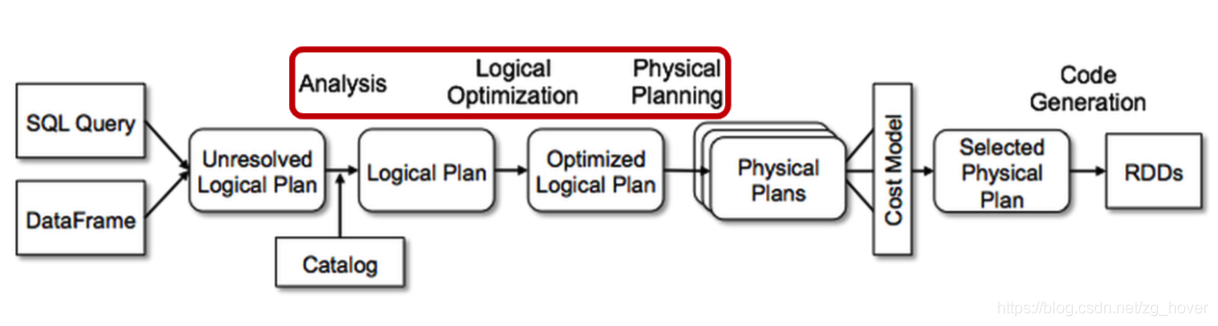
催化剂模块(Catalyst)
早在SparkSQL1.x就引入了催化剂模块(Catalyst),该模块主要是对执行过程中的执行计划进行处理和优化。所以可执行代码的生成,就需要通过Catalyst来进行处理。前面已经提到过,Catalyst主要包括两个部分: (1)表示式:把API/SQL语句的转换成Catalyst的表达式树,表达式是通过树这样的结构来组织和管理的。
(2)优化规则:根据优化规则,对表达式进行优化。
实现概要
总的来说,最终执行代码的生成需要经过以下几个阶段:
(1)逻辑计划的生成
逻辑计划的生成是在解析SQL语句或创建Dataset时完成。此时会创建一个QueryExecution对象,并根据数据源生成读取数据的逻辑计划。若还有对Dataset的其他操作,会继续在已有逻辑计划的基础上添加其他操作的逻辑计划。形成了一棵逻辑计划表达式树。
(2)逻辑计划的分析:
第(1)步生成的逻辑计划中可能包含未解析的属性引用或关系:例如,在 SQL 查询 SELECT col FROM sales 中,col的类型,它是否是有效的列名,直到我们查找表时才知道。我们把不知道类型或未将其与输入表(或别名)匹配的属性称为未解析(unresolved)。
Spark SQL 使用 Catalyst 规则和一个 Catalog对象来跟踪所有数据源中的表来解析这些属性。它首先构建具有未绑定属性和数据类型的“未解析逻辑计划”树,然后通过一系列规则进行分析和处理。
在代码实现层面,逻辑计划的分析是通过Analyzer对象来完成。
(3)逻辑计划的优化:通过Optimizer来完成
逻辑优化阶段将标准的基于规则的优化应用于逻辑计划。 (基于成本的优化是通过使用规则生成多个计划,然后计算它们的成本来执行的。)
这些优化规则包括:
- 常量折叠
- 谓词下推
- 投影修剪
- 空值传播
- 布尔表达式简化
- 其他规则
在代码实现层面,逻辑计划的优化是通过Optimizer对象来完成的。
(4)物理计划的生成
在物理规划阶段,Spark SQL 使用与 Spark 执行引擎匹配的物理运算符,获取一个逻辑计划并生成一个或多个物理计划。然后使用成本模型(Cost Mode)选择计划。
目前,基于成本的优化仅用于选择连接算法:对于已知较小的关系,Spark SQL 使用广播连接,使用 Spark 中可用的点对点广播工具。然而,该框架支持更广泛地使用基于成本的优化,因为可以使用规则递归地估计整棵树的成本。
在代码实现层面 ,物理计划的生成时通过SparkPlanner对象来完成的。
(5)物理计划的优化:
物理计划的优化,主要包括:将投影(projections)或过滤器(filter)流水线转化为一个 Spark的map操作。此外,它还可以将逻辑计划中的操作推送到支持谓词或投影下推的数据源中。
在代码实现层面,物理计划的优化是通过QueryExecution#prepareForExecution来完成的。
(6)执行代码的生成:通过SparkPlan#execute函数来实现
查询优化的最后阶段涉及生成 Java 字节码以在每台机器上运行。由于 Spark SQL 经常在内存数据集上运行,其中处理受 CPU 限制,我们希望支持代码生成以加快执行速度。
尽管如此,代码生成引擎的构建通常很复杂,本质上相当于一个编译器。 Catalyst 依靠 Scala 语言的一个特殊功能 quasiquotes 来简化代码生成。 Quasiquotes 允许在 Scala 语言中以编程方式构建抽象语法树 (AST),然后可以在运行时将其提供给 Scala 编译器以生成字节码。我们使用 Catalyst 将表示 SQL 中表达式的树转换为 AST 以供 Scala 代码评估该表达式,然后编译并运行生成的代码。
小结
通过以上分析,我们基本上掌握了SparkSQL运行的总体脉络,有了方向和路标,这样在大量源码中不会迷失方向。接下来的文章,会对这些步骤的每一步的实现原理进行分析。