文章目录
问题描述
二分类 0与1(阴性与阳性)
训练集和验证集训练分布
| 训练集数据 | 验证集数据 | |
|---|---|---|
| 阳性(1) | 2130 | 238 |
| 阴性(0) | 894 | 108 |
| 总计 | 3024 | 346 |
训练方法
损失函数:BCELoss
优化器:Adam
训练结果
在训练的同时进行验证, 发现训练集和验证集的准确率保持不变
训练集准确率=0.704365 验证集准确率=0.687861
训练集和验证集全部被预测为阳性
解决办法
1. 修改学习率
初始采用的优化器是Adam, 学习率是0.001
尝试将学习率修改为0.0001, 发现训练集的准确率仍然保持不变, 而验证集的准确率有所提高, 提高至0.731213
启示
将学习率由大到小调试, 如果准确率有所变化,则在训练时,如果验证集的损失在几个epoch 内没有下降,可以减少学习率
关键代码
# 更新LR 和 早停for epochin tqdm(range(0,64)):......# best_epoch 和 best_loss 分别指验证集上最好的损失和对应的epochif(epoch- best_epoch)>3:if val_loss> best_loss:print("decay loss from "+str(LR)+" to "+str(LR/2)+" as not seeing improvement in val loss")
LR= LR/2print("created new optimizer with LR "+str(LR))if(epoch- best_epoch)>10:print("no improvement in 10 epochs, break")break如何寻找最优的初始学习率
理论详解
关键代码
train_data_path='train.csv'
cropped_images_floder='cropped_images'
train_df= pd.read_csv(train_data_path)
train_size=len(train_df)
train_dataset= ImageData(cropped_images_floder=cropped_images_floder, df=train_df, channel_copy=True,
transform=None)
train_loader= DataLoader(dataset=train_dataset, batch_size=4, shuffle=True,
num_workers=1)
device= torch.device("cuda:1"if torch.cuda.is_available()else"cpu")
criterion= nn.BCELoss(reduction='mean').to(device)
model= get_model(modelType='resnet50', pretrained=True, num_labels=1, hidden_dropout=0.2)
model= model.to(device)
optimizer= torch.optim.Adam(params=filter(lambda p: p.requires_grad, model.parameters()), lr=1e-5,
betas=(0.9,0.99))deffind_lr(init_value=1e-8, final_value=10., beta=0.98):# 755
num=len(train_loader)-1# (10**9)**(1/755)
mult=(final_value/ init_value)**(1/ num)
lr= init_value
optimizer.param_groups[0]['lr']= lr
avg_loss=0.
best_loss=0.
batch_num=0
losses=[]
log_lrs=[]for i, datainenumerate(train_loader,0):
batch_num+=1# As before, get the loss for this mini-batch of inputs/outputs
imgs, labels, _= data
imgs, labels= imgs.to(device), labels.to(device)
optimizer.zero_grad()
outputs= model(imgs)
loss= criterion(outputs, labels)# Compute the smoothed loss
avg_loss= beta* avg_loss+(1- beta)* loss.item()
smoothed_loss= avg_loss/(1- beta** batch_num)# Stop if the loss is explodingif batch_num>1and smoothed_loss>4* best_loss:return log_lrs, losses# Record the best lossif smoothed_loss< best_lossor batch_num==1:
best_loss= smoothed_loss# Store the values
losses.append(smoothed_loss)
log_lrs.append(math.log10(lr))# Do the SGD step
loss.backward()
optimizer.step()# Update the lr for the next step
lr*= mult
optimizer.param_groups[0]['lr']= lrreturn log_lrs, losses
logs, losses= find_lr()
plt.plot(logs[10:-5],losses[10:-5])
plt.savefig('search_best_lr.png')2. 查看各类样本的分布,使用采样的方法WeightedRandomSampler
训练模型时,需要保证训练集和验证集中阳性和阴性数据之比尽可能1:1。
阴性样本很少从而导致模型倾向于总体样本全预测为阳性。
pytorch 中 WeightedRandomSampler 用于平衡数据集的样本类别不平衡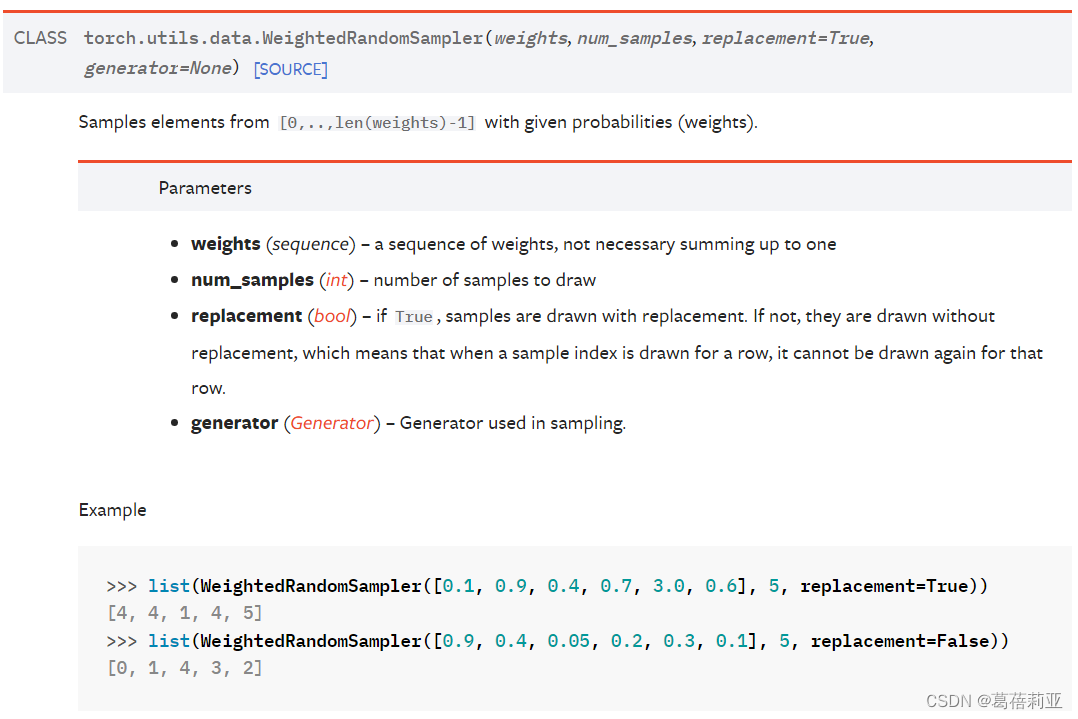
参数和返回值介绍
- weights = [ ] 是指数据集中每个样本的权重, len(weights) = 数据集的样本总数
计算方式:数据集样本总数 / 单个样本所属类别的数量 - num_samples : 需要采样的数量,可以根据自己需要的训练集样本数量设置
- replacement: 采样方式 True: 有放回采样;False: 无放回采样
- 返回值:从[0, len(weights) -1]中取出num_samples个数, list中的每个数可以作为index供DataLoader取用
关键代码
# dataset类添加get_classes_for_all_images()函数,用于返回训练集中每个样本的标签classImageData(Dataset):def__init__(self, cropped_images_floder, df, channel_copy=True, transform=None):
self.cropped_images_floder= cropped_images_floder
self.transform= transform
self.df= df
self.channel_copy= channel_copy
self.random_number_generator= np.random.RandomState(0)def__getitem__(self, idx):...defget_classes_for_all_images(self):return self.df['label'].tolist()def__len__(self):return self.df.shape[0]# 由于训练集样本分布不均匀,给每个样本分配权重进行重采样# class_counts: 数据集中,每一类的数目,这里是二分类,只有0和1
cropped_images_floder='/home/user1/data/cropped_images'
train_data_df= pd.read_csv('/home/user1/data/train.csv')
class_counts=[train_data_df['label'].value_counts()[0], train_data_df['label'].value_counts()[1]]print(class_counts)# [894, 2130]# 每个类别的权重
weights=1./ torch.tensor(class_counts, dtype=torch.float)print(weights)# tensor([0.0011, 0.0005])# train_targets: 训练集中每个样本的标签
train_dataset= ImageData(cropped_images_floder=cropped_images_floder, df=train_data_df, channel_copy=True,
transform=None)
train_targets= train_dataset.get_classes_for_all_images()print(train_targets,len(train_targets))# [0, 1, 0, ..., 1, 1, 1] 3024# sample_weights: tensor每个样本的权重=训练集总数/该样本所属类别的数量, 所以长度为训练集的样本数
samples_weights= weights[train_targets]*len(train_data_df)print(samples_weights,len(samples_weights))# tensor([3.3826, 1.4197, 3.3826, ..., 1.4197, 1.4197, 1.4197]) 3024# num_samples: 表示需要采样的个数,可按照自己的需要设置, replacement:True为有放回地采样,False为无放回地采样# 返回的sampler 是[0,..,len(weights)-1]之间的任意数。
sampler= WeightedRandomSampler(weights=samples_weights, num_samples=len(samples_weights), replacement=True)print(list(sampler),len(list(sampler)))# [137, 127, 1247, 646, 3010, 1543, 1098, 1367, ...] 3024# shuffle 一定要设置为False, 因为上一步获得sampler时是随机采样,采样的顺序是乱的
train_loader= torch.utils.data.DataLoader(dataset=train_dataset, batch_size=4, shuffle=False,
sampler=sampler, num_workers=1)测试代码
true_labels=[]for i, datainenumerate(train_loader,0):
images, labels, path= datafor itemin labels.cpu().data.numpy():for jin item:
true_labels.append(int(j))print(pd.value_counts(true_labels)# 0 1541# 1 1483# dtype: int64问题
使用这种方法, 可能会导致丢失原始数据, 即并不是所有的原始数据都有被采样到和被模型训练
3. 在计算损失时对不同标签的样本赋予不同大小的权重 Focal_Loss()
classFocal_Loss(torch.nn.Module):"""
二分类Focal Loss
"""def__init__(self, alpha=0.25, gamma=2):super(Focal_Loss, self).__init__()
self.alpha= alpha
self.gamma= gammadefforward(self, preds, labels):"""
preds:sigmoid的输出结果
labels:标签
"""
eps=1e-7
loss_1=-1* self.alpha* torch.pow((1- preds), self.gamma)* torch.log(preds+ eps)* labels
loss_0=-1*(1- self.alpha)* torch.pow(preds, self.gamma)* torch.log(1- preds+ eps)*(1- labels)
loss= loss_0+ loss_1return torch.mean(loss)4. 在训练集进行随机采样
将小类别的全部样本送进训练,并且在每个epoch 都从大类别样本中随机采样,采样与小类别样本相同数量的样本送进训练