一. 混淆矩阵
| Confusion Matrix | Predict | ||
| True | False | ||
| Real | True | True Positive | False Positive |
| False | False Negative | True Negative | |
准确率 (Accuracy) a c c = T P + T N T P + Y N + F P + F N acc =\frac{TP+TN}{TP+YN+FP+FN}acc=TP+YN+FP+FNTP+TN
精确率 (Precision): 也叫查准率 P = T P T P + F P P = \frac{TP}{TP+FP}P=TP+FPTP
召回率 (Recall):也叫查全率,值与TPR相同,后面会介绍 R = T P R = T P T P + F N R = TPR = \frac{TP}{TP+FN}R=TPR=TP+FNTP
下图为P-R曲线图,直观地显示出分类器在样本总体上的分类效果,两个变量值都是越接近1越好。若遇到交叉曲线,可判断平衡点,即 y = x y=xy=x 与其交点,可以看出 A 优于 B。后又出现新的判别方式 F1 度量,即 F-Score。
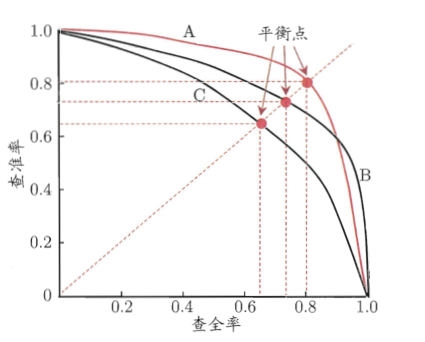
- F-Score (F1度量): 一般形式为(2)式 F 1 = 2 ⋅ P ⋅ R P + R = 2 ⋅ T P 样 例 总 数 + T P + F N ( 1 ) F1 = \frac{2 \cdot P \cdot R}{P+R}= \frac{2 \cdot TP}{样例总数+TP+FN} \qquad (1)F1=P+R2⋅P⋅R=样例总数+TP+FN2⋅TP(1) F β = ( 1 + β 2 ) ⋅ P ⋅ R β 2 ⋅ P + R ( 2 ) F_{\beta} = \frac{(1+ \beta^2) \cdot P \cdot R}{\beta^2 \cdot P+R} \qquad \qquad \qquad \qquad \qquad(2)Fβ=β2⋅P+R(1+β2)⋅P⋅R(2)
β > 0 β>0β>0 度量了查全率对查准率的相对重要性, β = 1 β=1β=1 时退化为标准的 F1; β > 1 β>1β>1 时查全率有影响更大; β < 1 β<1β<1 时查准率影响更大,F-Score 值越大越理想。
python 绘出混淆矩阵 更详细的请参考Creating annotated heatmaps
heat= np.array([[1,10],[8,3]])
fig, ax= plt.subplots()
tick_y=["Real_true","Real_false"]
tick_x=["Predict_true","Predict_false"]
ax.set_xticks(np.arange(len(tick_x)))
ax.set_yticks(np.arange(len(tick_y)))
ax.set_xticklabels(tick_x)
ax.set_yticklabels(tick_y)for iinrange(len(tick_x)):for jinrange(len(tick_y)):
text= ax.text(j, i, heat[i, j],
ha="center", va="center", color="r")
ax.set_title("Confusion Matrix")
im= ax.imshow(heat)
fig.tight_layout()
plt.show()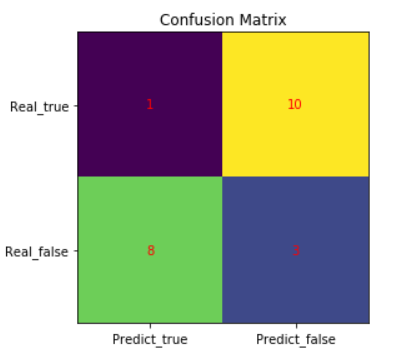
python中调用各项指标:之前的数据集都没有放入,只是表明一下调用方式
from sklearn.metricsimport precision_score, recall_score, roc_auc_score, roc_curveprint(f'Train ROC AUC Score: {roc_auc_score(train_labels, train_probs)}')print(f'Test ROC AUC Score: {roc_auc_score(test_labels, probs)}')Train ROC AUC Score: 1.0
Test ROC AUC Score: 0.6639844451938421
这段代码直接传参可以调用,在做项目时能省很多时间
import matplotlib.pyplotas pltimport numpyas npimport itertools'''
绘制混淆矩阵,传入
测试集y_test,预测值y_pred
'''defplot_confusion_matrix(cm, classes, title='Confusion matrix',
cmap=plt.cm.Blues):
plt.imshow(cm,interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks= np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh= cm.max()/2for i,jin itertools.product(range(cm.shape[0],range(cm.shape[1]))):
plt.text(j,1,cm[i, j], horizontalalignment="center",
color="white"if cm[i,j]> threshelse"black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')二. ROC与AUC曲线
ROC (Receiver Operating Characteristic)
首先介绍一下 TPR 和 FPR
- TPR、FPR: TPR (True Positive Rate) 表示预测正样本占所有正例的比值,FPR (False Positive Rate) 表示被错误预测为负样本的正样本数量占所有负样本的比值。
T P R = T P T P + F N F P R = F P F P + T N TPR =\frac{TP}{TP+FN} \qquad FPR =\frac{FP}{FP+TN}TPR=TP+FNTPFPR=FP+TNFP

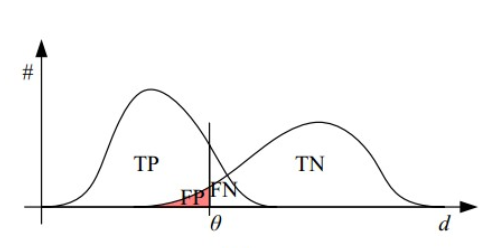
左图: 横坐标就是假正例率 (FPR),纵坐标是真正例率 (TPR),(1,0) 点表示最差的分类器,(0,1) 点表示最完美的分类器,(0,0) 表示该分类器预测的样本都是负样本,(1,1) 表示预测所有的样本都是正样本。所以越接近 (0,1) 越好,即理想情况下
T
P
R
=
1
,
F
P
R
=
0
\ TPR=1, FPR = 0TPR=1,FPR=0。图中虚线为Random Guess,即采用随机猜测策略的分类器,预测结果一般为正样本,一半为负样本。
右图: 直观看出都是有交叉部分,其中 θ 为阈值,随着 θ 增加,TP 和 FP 都减小,TPR 和 FPR 也减小,ROC 的点向左下移动
AUC (Area Under Curve)
被定义为ROC曲线下的面积,取值范围为一般 (0.5, 1),否则分类器太差了,不如去猜 。由上图可知,取不同的 θ 得出不同的 TPR 和 FPR,因此测试样例越多,得到的ROC曲线越平滑。AUC评价标准,曲线面积越大,分类器更好。
defevaluate_model(predictions, probs, train_predictions, train_probs):"""Compare machine learning model to baseline performance.
Computes statistics and shows ROC curve."""
baseline={}
baseline['recall']= recall_score(test_labels,[1for _inrange(len(test_labels))])
baseline['precision']= precision_score(test_labels,[1for _inrange(len(test_labels))])
baseline['roc']=0.5
results={}
results['recall']= recall_score(test_labels, predictions)
results['precision']= precision_score(test_labels, predictions)
results['roc']= roc_auc_score(test_labels, probs)
train_results={}
train_results['recall']= recall_score(train_labels, train_predictions)
train_results['precision']= precision_score(train_labels, train_predictions)
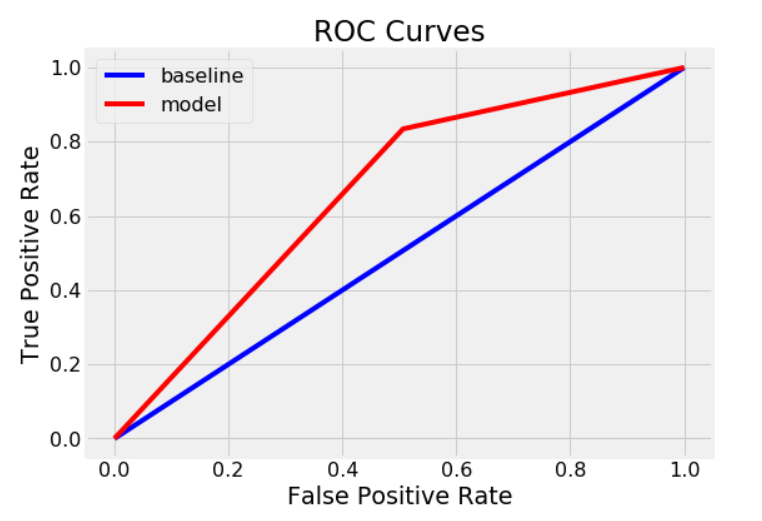
train_results['roc']= roc_auc_score(train_labels, train_probs)for metricin['recall','precision','roc']:print(f'{metric.capitalize()} Baseline: {round(baseline[metric], 2)} Test: {round(results[metric], 2)} Train: {round(train_results[metric], 2)}')# Calculate false positive rates and true positive rates
base_fpr, base_tpr, _= roc_curve(test_labels,[1for _inrange(len(test_labels))])
model_fpr, model_tpr, _= roc_curve(test_labels, probs)
plt.figure(figsize=(8,6))
plt.rcParams['font.size']=16# Plot both curves
plt.plot(base_fpr, base_tpr,'b', label='baseline')
plt.plot(model_fpr, model_tpr,'r', label='model')
plt.legend();
plt.xlabel('False Positive Rate'); plt.ylabel('True Positive Rate'); plt.title('ROC Curves');
evaluate_model(predictions, probs, train_predictions, train_probs)Recall Baseline: 1.0 Test: 0.83 Train: 1.0
Precision Baseline: 0.81 Test: 0.88 Train: 1.0
Roc Baseline: 0.5 Test: 0.66 Train: 1.0
三. 参考文献及链接
[1]ROC、Precision、Recall、TPR、FPR理解
[2] 《机器学习》 周志华
[3] 图片来源于网络
[4] 最后的代码是在kaggle上下载的,是一个大佬的 Random Forest 做的项目,具体链接找不到了…