- request库基于urllib,比urllib更加方便,是Python更加简单的http库。
- 使用request库的一个例子:
import requests
response = requests.get('http://www.baidu.com')
print(type(response))#返回值的类型
print(response.status_code)#当前网站返回的状态码
print(type(response.text))#网页内容的类型
print(response.text)#网页的具体内容(html代码)
print(response.cookies)#网页的cookie具体解释写在了注释里面,request中输出网页的html代码的方法是response.text方法,它相当于urllib库的response.read方法,只不过不需要进行decode操作。
打印cookie的操作也比urllib简单,只需要使用.cookie方法即可。
执行结果如下:
- 各种请求方式
import requests
requests.post('http://httpbin.org/post')
requests.delete('http://httpbin.org/delete')
requests.put('http://httpbin.org/put')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')这里的请求返回值可以去http://httpbin.org获取,这个网站可以用来进行http请求的测试。
GET请求
- 基本的GET请求
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)这是request中最简单的get请求。
- 带参数的GET请求
import requests
response = requests.get('http://httpbin.org/get?name=germey&age=22')
print(response.text)其中http://httpbin.org/get后面的部分为get方法的基本构成,不清楚的可以去了解一下,以上代码会返回get请求参数。
如果不想构造url,那么requeat库中有一个params参数,可以传入一个字典,他会给你自动拼接到url后面,例子如下:
import requests
data = {
'name':'germey',
'age':'22'
}
response = requests.get('http://httpbin.org/get',params=data)
print(response.text)这样就能构造一个get请求参数,和上面返回的内容相同。
- 解析json
import requests
import json
response = requests.get('http://httpbin.org/get')
print(type(response.text))
print(response.json())
print(json.loads(response.text))
print(response.text)
print(type(response.json()))response.json()与json.loads ()返回的结果完全相同,在使用ajax请求时比较常用。
- 获取二进制数据
在下载图片或者视频时,常用的方法,获取图片或者视频的二进制数据。
import requests
response = requests.get("https://github.com/favicon.ico")
print(type(response.text),type(response.content))
print(response.text)
print(response.content)这里打印出了当前网址图片的二进制数据
也可以用以下方法之间把图片下载下来,保存成图片属性:
import requests
response = requests.get("https://github.com/favicon.ico")
with open('facicon.ico','wb') as f:
f.write(response.content)
f.close()- 添加headers
在写爬虫时,如果不加header参数,当前网站就会把你当成爬虫,然后禁止你访问,加入headers可以有效的避免。
import requests
url = 'https://www.zhihu.com/explore'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Host':'httpbin.org'
}
response = requests.get(url,headers)
print(response.text)User-Agent的参数时浏览器信息,加上headers能让服务器认为你是浏览器访问的而不是爬虫访问的,实现了浏览器的伪装。
POST请求
- 基本的POST请求
import requests
data = {
'name':'germey',
'age':'22'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Host':'httpbin.org'
}
url = 'http://httpbin.org/post'
response = requests.post(url,data,headers)
print(response.json())POST请求和GET请求的区别就是,需要穿入一个form表单,使用request库可以将表单构造成字典类型,之后传入。
- 其他的POST方法个GET方法相同,只需要将request.get换成request.post即可
响应
- response属性
import requests
response = requests.get('http://www.jianshu.com')
print(type(response.status_code), response.status_code)
print(type(response.headers), response.headers)
print(type(response.cookies), response.cookies)
print(type(response.url), response.url)
print(type(response.history), response.history)这些是常用的response返回结果。
- 状态码的判断
import requests
response = requests.get('http://www.jianshu.com')
exit()if not response.status_code ==requests.codes.ok else print('成功访问')这里使用requests.codes.ok可以用名字调用相应的状态码。
这里还有其他状态码对应的名字: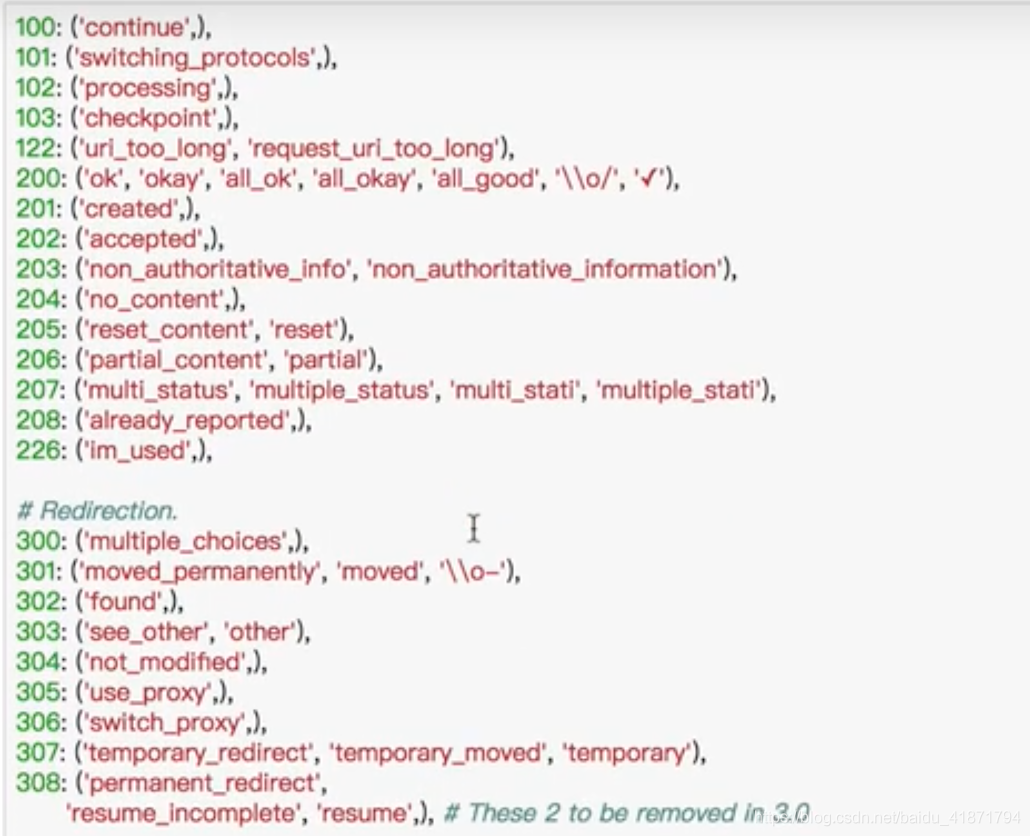


高级操作
- 文件上传
import requests
file = {
'file':open('文件名称','rb')
}
response = requests.post("网址",file)
print(response.text)在文件名称处写入要穿入文件的目录。
- 获取cooike
import requests
response = requests.get('https://www.baidu.com')
print(response.cookies)
for key,value in response.cookies.items():
print(key+"="+value)可以将cookie使用key value的形式打印出来
- 会话维持
获取到cookie后,就可以进行模拟登陆操作了
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
response = s.get('http://httpbin.org/cookies')
print(response.text)输出结果为: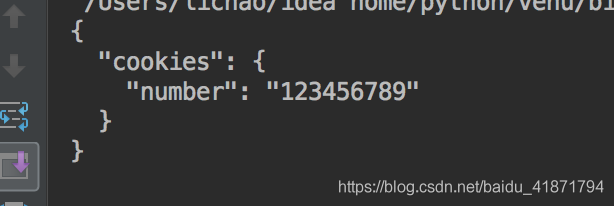
这里我们使用session保存了当前的cookie,让服务器认为是一台浏览器发起的请求,就可以成功打印出cookie。
- 如果要模型登录验证时,就可以使用requests.Session()来发起请求,他可以模拟浏览器对服务器进行请求,维持了登录会话
- 证书验证
如果访问用request请求访问https协议的网站时,他会首先检测证书是否合法,如果检测不合法,就会抛出错误。
如果想要避免错误,只需要把request中的verify设置为false,就可以了。
import requests
response = requests.get('https://www.12306.cn',verify = False)
print(response.status_code)会返回200,表示正常连接。
- 代理设置
import requests
proxys = ({
'http':'http://127.0.0.1',
'https':'https://127.0.0.1'
})
response = requests.get('http://www.baidu.com',proxys)
print(response.status_code)注意:proxys中的参数是你自己代理的ip地址,需要修改
- 超时设置
import requests
response = requests.get('http://www.baidu.com',timeout =1)
print(response.status_code)使用timeout参数设置超时时间,如果访问网站时超过这个时间,则会报错。
我们可以加一个try -except来捕获异常
import requests
from requests.exceptions import ReadTimeout
try:
response = requests.get('http://www.baidu.com',timeout =1)
print(response.status_code)
except ReadTimeout:
print('Timeout')- 认证设置
有些网站登录时需要验证用户名和密码,比如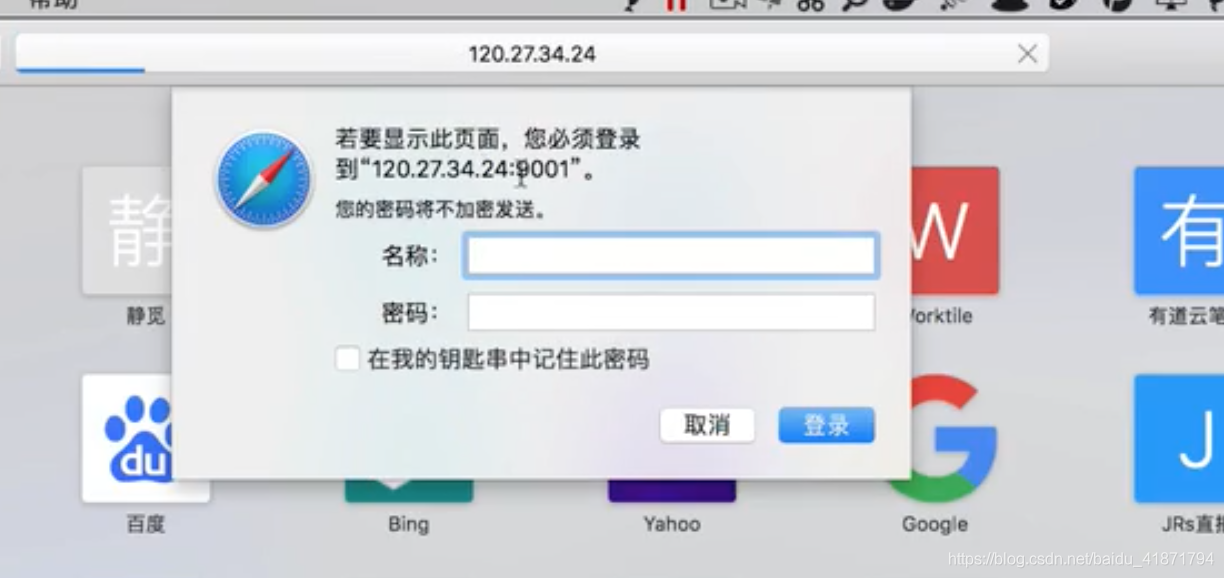
如果遇到这种网站,则可以使用如下方法完成正常请求:
import requests
from requests.auth import HTTPBasicAuth
response = requests.get('需要访问的网址',auth = HTTPBasicAuth('用户名','密码'))
print(response.status_code)Python3的request库比起urllib库更加方便好用,在写爬虫时会经常用到