在社科研究中的问卷调查,或者需要进行问卷答题的场景中,需要用纸质问卷采集答案,然后将问卷的答案输入电脑。这是一般的问卷采集答案的方法,如果问卷数量并不是很多能很快速的将问卷的结果输入到电脑中,但是如果有很多张相同的问卷的情况下,工作效率就会减慢(一张一张的录入)。采用电脑识别的方式能很快的将纸质答案转换为电脑可识别的数据。
采用python+opencv的方式,在识别每一张问卷唯一性上,可以在每一张问卷上张贴二维码,用以区别问卷的唯一。
思路:
1,将答题卡扫描,进行灰度转变、高斯模糊、cv2.Canny边缘转化等操作,把图片转换。
2,扫描答题卡,确定左边和上边的黑块基点,进而根据黑块的基础位置和大小推算确定每一个答题选项的位置。
3,确定每一个答题选项后,由于是每一行扫描,所以每4个确定的坐标分为一组,每组的顺序就是题目答案的顺序。
4,对分组的一组中的4个区域计算cv2.countNonZero像素值,像素值越小的就表示涂得最多,进而确定填涂的选项。空选项的情况,将4个选项的像素值进行比较最大值减去最小值的差值若小于某一个值,则认为此选项没有填涂。
代码如下:
import cv2
import numpy as np
from imutils.perspective import four_point_transform
from pyzbar import pyzbar
img000 = cv2.imread('\\example01\\33334.jpg')
#答题卡左边的黑块数量、答题卡题目总量
leftji = 16
allji = 32
res=cv2.resize(img000,(1043,int(img000.shape[0]*1043/img000.shape[1])),interpolation=cv2.INTER_CUBIC)
img = res
openw = 0
openh = 0
#转化成灰度图片
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gaussian_bulr = cv2.GaussianBlur(gray, (5, 5), 0) # 高斯模糊
edged=cv2.Canny(gaussian_bulr,75,1) # 边缘检测,灰度值小于2参这个值的会被丢弃,大于3参这个值会被当成边缘,在中间的部分,自动检测
toushi = ''
toushiq = ''
# 寻找轮廓
cts, hierarchy = cv2.findContours( edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
list=sorted(cts,key=cv2.contourArea,reverse=True)
jidian = []
for c in list:
peri=0.01*cv2.arcLength(c,True)
approx=cv2.approxPolyDP(c,peri,True)
# 打印定点个数
# print("顶点个数:",len(approx))
if peri >= 10 and len(approx) == 4:
ox_sheet = four_point_transform(img, approx.reshape(4, 2))
tx_sheet = four_point_transform(gray, approx.reshape(4, 2))
toushiq = four_point_transform(edged, approx.reshape(4, 2))
toushi = ox_sheet
ret, thresh2 = cv2.threshold(tx_sheet, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
# cv2.imshow("ostu", thresh2)
r_cnt, r_hierarchy = cv2.findContours(thresh2.copy(), 1, 2)
for ii in r_cnt:
peris = 0.01 * cv2.arcLength(ii, True)
approxa = cv2.approxPolyDP(ii, peris, True)
x, y, w, h = cv2.boundingRect(approxa)
if w >= 40 and (x < 100 or y < 100) and len(approxa) == 4 and peris < 10:
cv2.rectangle(ox_sheet, (x, y), (x + w, y + h), (0, 0, 255), 2)
jidian.append([x, y])
openw = w
openh = h
data = np.array(jidian)
idex=np.lexsort([data[:,1], data[:,0]])
sorted_data = data[idex, :]
hang = sorted_data[0:leftji]
lie = sorted_data[leftji:allji]
aswgroup = []
for b in hang:
for n in lie:
cv2.rectangle(toushi, (n[0], b[1]), (n[0] + openw, b[1] + openh), (0, 0, 255), 2)
aswgroup.append([n[0], b[1]])
def list_split(items, n):
return [items[i:i+n] for i in range(0, len(items), n)]
list2 = list_split(aswgroup, 4)
totals = []
for lll in list2:
a = []
b = []
for ll in lll:
cropImg = toushiq[ll[1]:ll[1] + openh, ll[0]:ll[0] + openw]
total = cv2.countNonZero(cropImg)
a.append([total,ll])
b.append(total)
if max(b)-min(b) < 120:
bindex = 4
else :
bindex = b.index(min(b))
totals.append([bindex,(max(b)-min(b)),a])
i = 1
w = ['A','B','C','D','NULL']
for llwwww in totals:
print(i,w[llwwww[0]],llwwww)
i = i+1
# 识别二维码
barcodes = pyzbar.decode(img)
for barcode in barcodes:
barcodeData = barcode.data.decode("utf-8")
print(barcodeData)
cv2.imshow("hongse",toushi)
cv2.waitKey(0)运行结果的图片:

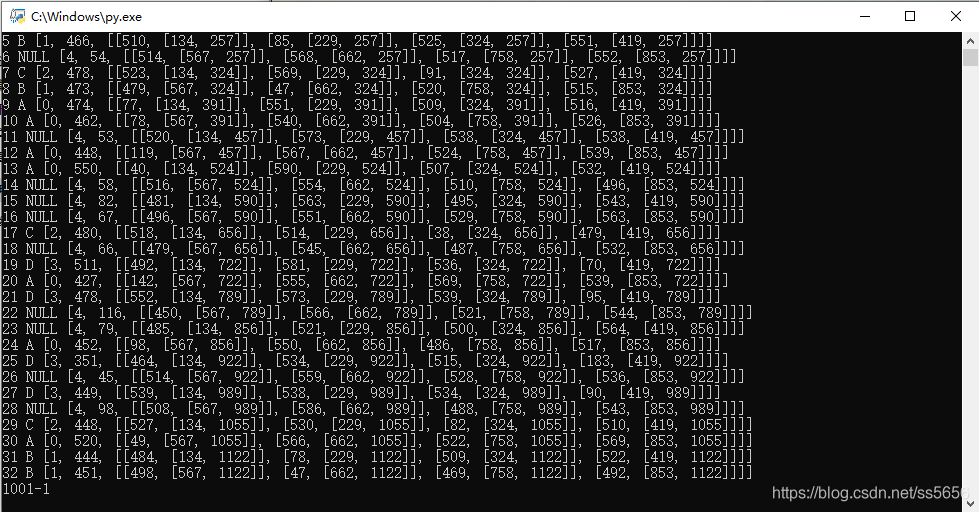
一行的输出释义:题号、答案4个坐标中最小像素值的位置、最大像素值减最小像素值的差值、4个坐标的值。有多少个题目就输出多少行。其中随后一个输出值是答题卡二维码识别的值。
答题卡原图:
