CNN分类时,通常需要考虑输入样本的局部性、平移不变性、缩小不变性,旋转不变性等,以提高分类的准确度。这些不变性的本质就是图像处理的经典方法,即图像的裁剪、平移、缩放、旋转,而这些方法实际上就是对图像进行空间坐标变换,我们所熟悉的一种空间变换就是仿射变换,图像的仿射变换公式可以表示如下:
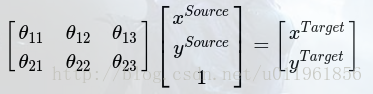
式中,(xSource,ySource)表示原图像像素点,(xTarget,yTarget)表示仿射变换后的图像像素点。系数矩阵θ即为仿射变换系数,可以通过调整系数矩阵θ,实现图像的放大、缩小、平移、旋转等。
那么,神经网络是否有办法,用一种统一的结构,自适应实现这些变换呢?本文提出了一种叫做空间变换网络(Spatial Transform Networks, STN)的网络模型,该网络不需要关键点的标定,能够根据分类或者其它任务自适应地将数据进行空间变换和对齐(包括平移、缩放、旋转以及其它几何变换等)。在输入数据空间差异较大的情况下,这个网络可以加在现有的卷积网络中,提高分类的准确性。
本文所提的空间变换网络的主要作用在于:
1.可以将输入变换为网络的下一层期望的形式;
2.可以在训练的过程中自动选择感兴趣的区域特征;
3.可以实现对各种形变的数据进行空间变换;

例如对于上图中输入手写字体,我们感兴趣的是黄色框中的包含数字的区域,那么在训练的过程中,学习到的空间变换网络会自动提取黄色框中的局部数据特征,并对框内的数据进行空间变换,得到输出output。
2. 空间变换网络原理详解
所谓空间变换网络,实际上是在神经网络的某两层之间引入一个空间变换网络,该空间变换网络包括两个部分,网络结构如下图所示:
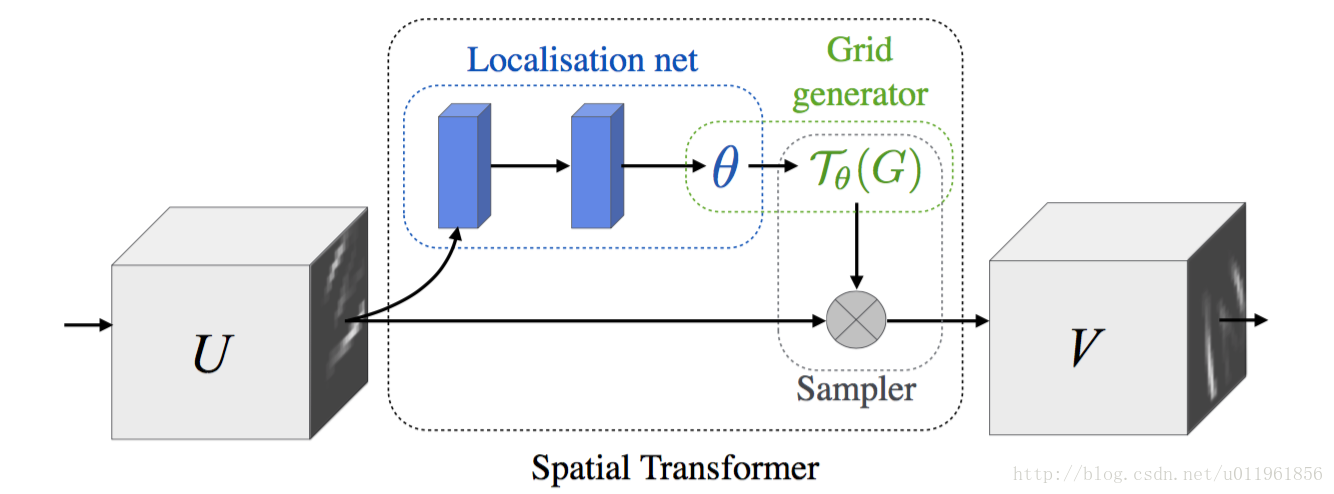
第一部分为为”localization net”,其用于生成仿射变换系络结构进行设计,”localization net”网络中的参数则为空间变换网络需要训练的参数;第二部分就是空间变换即仿射变换。通过该局部网络产生仿射变换系数θ(也可以是其他类型的空间变换,可以根据需要设计局部网络得到对应的空间变换系数θ,本文只以仿射变换为例进行讲解),得到仿射变换系数θ后我们就可以对上一层的输入进行仿射变换,并将仿射变换结果输入到下一层。例如上图中, U是输入图像或CNN某一层的feature map, V是仿射变换后的feature map,U与V中间夹着的就是“空间变换网络”,如上所说该空间变换网络中,”localization net”为用于生成仿射变换系数θ,”localization net”可以是全连接层或卷积层,具体的网络设计需要根据实际需要设置。”localization net”得到仿射变换系数θ后,我们就可以对输入U进行仿射变换了得到V了。对于”localization net”网路的设计,我们最后会以代码为例进行讲解,接下来首先讲一下得到仿射变换系数θ后对U进行仿射变换的原理。
对于仿射变换,如果直接由仿射变换系数θ对输入(xSource,ySource)求解得到输出坐标点(xTarget,yTarget)是非整数的,因此需要对考虑逆向仿射变换。所谓逆向仿射变换就是首先根据仿射变换输出的大小,生成输出的坐标网格点,即上图中的“Grid generator”,例如V的大小为10×10时,我们便可以得到一个10×10大小的坐标位置点矩阵,接下来就是要对该坐标位置点进行仿射变换,仿射变换公式及示意图如下:
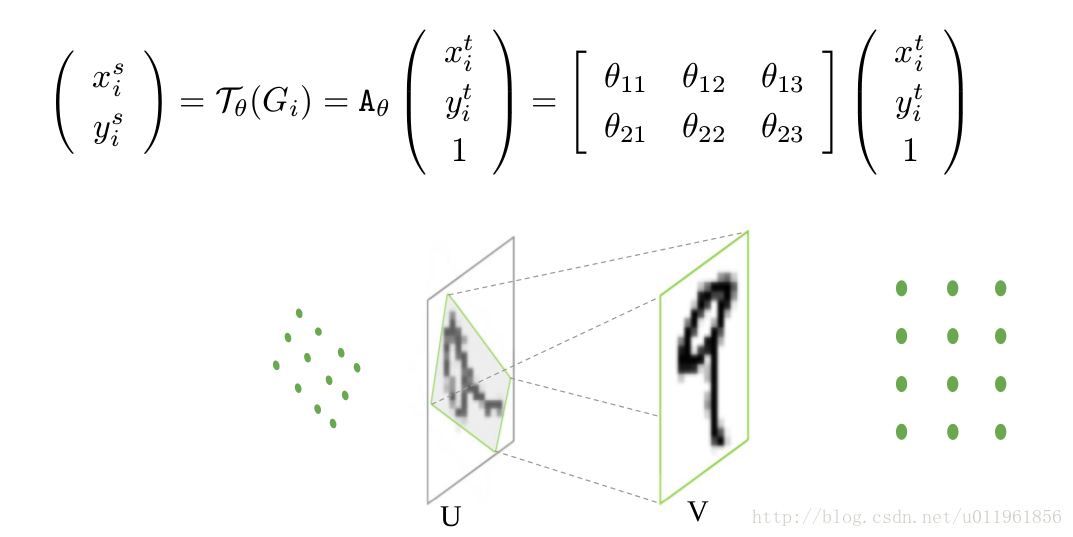
需要注意的是,这时候的仿射系数为θ的逆矩阵,经过仿射变换后可以得到V中的位置坐标点在U中对应的位置。但是,这时候求得的U中的坐标点仍然可能为非整数,因此通常需要进行插值得到对应的坐标点。得到U中的坐标点后,则可以将其复制到V中,从而得到仿射变换结果V。具体仿射变换过程,也可以结合下图进行理解:
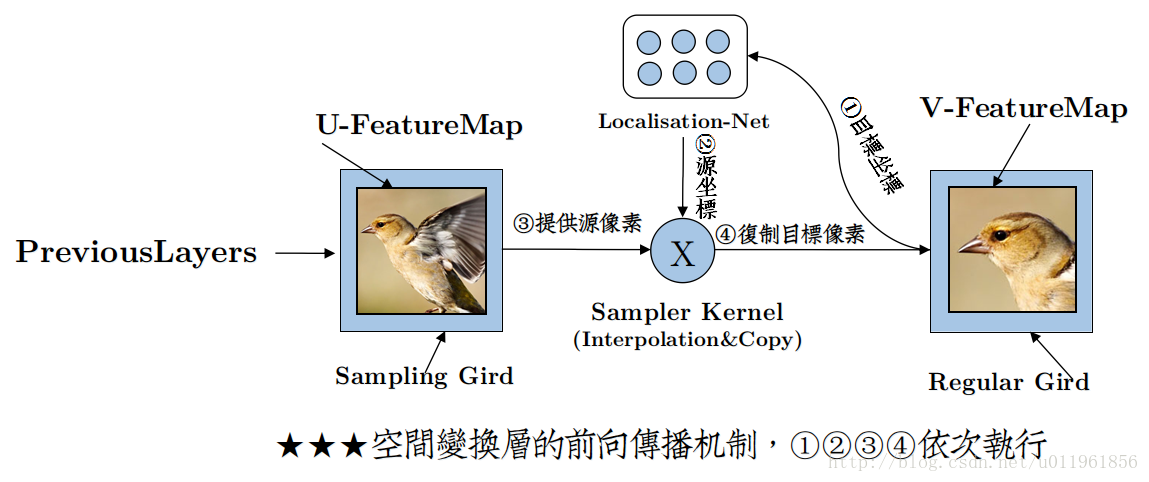
上图中由Localisation Net生成仿射变换系数θ后,仿射变换的过程是依次执行步骤1,2,3,4。
3. 空间变换网络的实际应用
以上讲解的是空间变换网络的理解,那么在实际应用中,我们该如何添加空间变换网络到我们自己的网络中呢?接下来重点讲解空间变换网络的应用。
3.1.空间变换网络作为网络的第一层
空间变换网络可以直接作为网络的第一层,即Localisation Net的输入为input,从而直接对输入进行仿射变换,对于Localisation Net的设计,可以根据输入input的大小设计Localisation Net为全连接层或卷积层,例如对于手写字体,输入图片大小为40x40,即input=[batch_size,1600],那么我们可以设计Localisation Net包含两个全连接层,第一个全连接层w1=[1600,20],b1=[20],第一个全连接层w2=[20,6],b2=[6],则第二个全连接层的输出为[batch_size,6],即为仿射变换系数。若输入Localisation Net的input尺寸较大,则需要在Localisation Net中添加卷积和池化层,最后再输入到全连接层,得到仿射变换系数;关于全连接层和卷积层的设计详见参考代码4.1,4.2。
3.2.空间变换网络插入CNN的中间层
空间变换网络还可以添加在CNN的中间层,可以直接将空间变换网络插入conv或者max-pooling层的前面或者后面。此外,还可以在CNN的同一层插入多个空间变换网络,下面给出空间变换网络插入CNN的手写字体网络结构图:
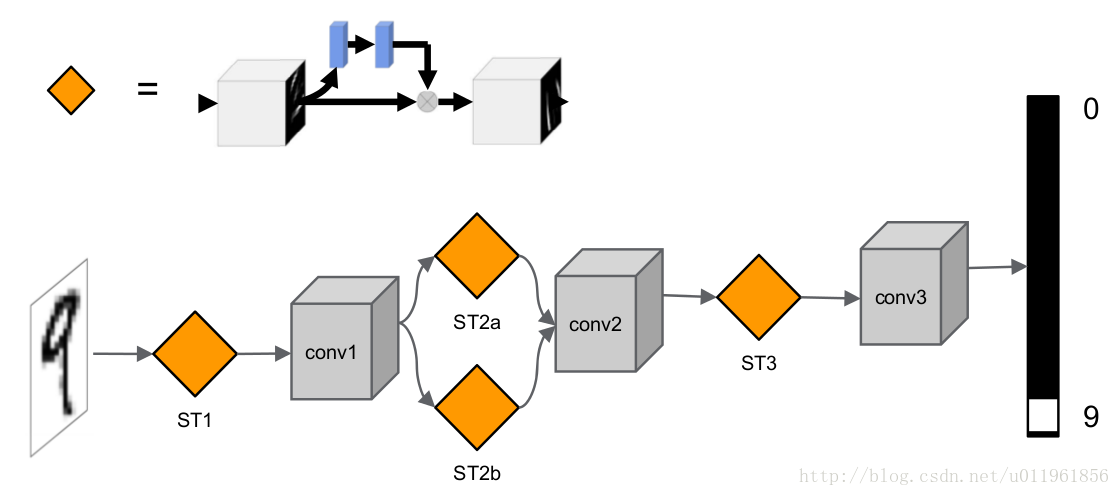
上图中第一个空间变换网络ST1作用于输入图像,直接对输入图像进行空间变换,第二、三个空间变换网络ST2a,ST2b作用于conv1,用于对第一层的卷积特征进行空间变换,而ST3用于对更深层的卷积特征进行空间变换。
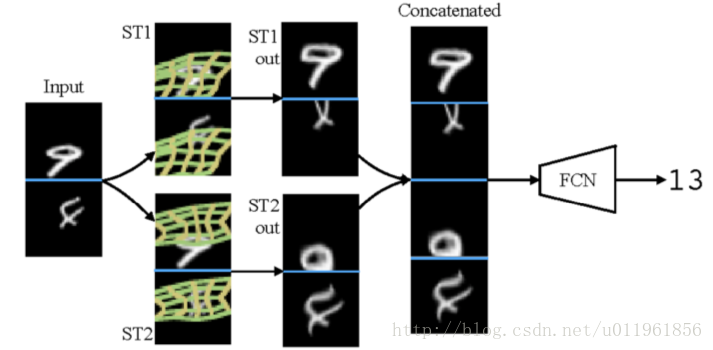
由于空间变换网络能够自动提取局部区域特征,因此在网络的同一层插入父哦个空间变换网络可以提取多个局部区域特征,从而可以结合多个局部区域特征进行分类,如下如的网络是实现两张输入的图片中的手写字体相加,在网络的第一层插入两层空间变换网络ST1,ST2,并将其直接作用语输入图像。图中第三列为空间变换结果,有图可知,网络ST1,ST2分别提取了输入手写字体的不同区域的特征。
4. 代码分析
首先看一仿射变换的代码实现,代码的实现如上所述,首先由函数_meshgrid生成输出V的坐标位置点grid,在通过仿射变换系数theta对grid进行仿射变换得到U中对于位置坐标点T_g,之后对T_g进行双线性插值,并复制插值后的U中的坐标点的像素值到V中,得到输出V。具体代码实现如下:
deftransform(theta, input_dim, out_size):with tf.variable_scope('_transform'):
num_batch = tf.shape(input_dim)[0]
height = tf.shape(input_dim)[1]
width = tf.shape(input_dim)[2]
num_channels = tf.shape(input_dim)[3]
theta = tf.reshape(theta, (-1,2,3))
theta = tf.cast(theta,'float32')# grid of (x_t, y_t, 1), eq (1) in ref [1]
height_f = tf.cast(height,'float32')
width_f = tf.cast(width,'float32')
out_height = out_size[0]
out_width = out_size[1]
grid = _meshgrid(out_height, out_width)
grid = tf.expand_dims(grid,0)
grid = tf.reshape(grid, [-1])
grid = tf.tile(grid, tf.pack([num_batch]))
grid = tf.reshape(grid, tf.pack([num_batch,3, -1]))#得到输出坐标位置点# Transform A x (x_t, y_t, 1)^T -> (x_s, y_s)
T_g = tf.batch_matmul(theta, grid)#仿射变换
x_s = tf.slice(T_g, [0,0,0], [-1,1, -1])#
y_s = tf.slice(T_g, [0,1,0], [-1,1, -1])
x_s_flat = tf.reshape(x_s, [-1])
y_s_flat = tf.reshape(y_s, [-1])
input_transformed = _interpolate(
input_dim, x_s_flat, y_s_flat,
out_size)#插值,并得到输出
output = tf.reshape(
input_transformed, tf.pack([num_batch, out_height, out_width, num_channels]))return output接下来结合两个具体的实例分别讲解”localization net”的为全连接层和卷积层的设计。
(4.1)”localization net”的为全连接层的实例:
该示例中,空间变换网络用于对输入图像进行变换处理,”localization net”包括两个全连接层,具体网络设计如下:
x = tf.placeholder(tf.float32, [None,1600])#输入
y = tf.placeholder(tf.float32, [None,10])
x_tensor = tf.reshape(x, [-1,40,40,1])
W_fc_loc1 = weight_variable([1600,20])#第一个全连接层
b_fc_loc1 = bias_variable([20])
W_fc_loc2 = weight_variable([20,6])#第二个全连接层
initial = np.array([[1.,0,0], [0,1.,0]])
initial = initial.astype('float32')
initial = initial.flatten()
b_fc_loc2 = tf.Variable(initial_value=initial, name='b_fc_loc2')
h_fc_loc1 = tf.nn.tanh(tf.matmul(x, W_fc_loc1) + b_fc_loc1)
keep_prob = tf.placeholder(tf.float32)
h_fc_loc1_drop = tf.nn.dropout(h_fc_loc1, keep_prob)
h_fc_loc2 = tf.nn.tanh(tf.matmul(h_fc_loc1_drop, W_fc_loc2) + b_fc_loc2)#仿射变换系数theta,大小为bath_size*6
out_size = (40,40)
h_trans = transformer(x_tensor, h_fc_loc2, out_size)该代码所示,该空间变换网络部分需要训练的参数即为”localization net”包括两个全连接层的参数W_fc_loc1, b_fc_loc1,W_fc_loc2, b_fc_loc2。完整代码链接如下:
https:\/\/github.com\/tensorflow\/models\/blob\/master\/transformer\/cluttered_mnist.py
(4.2)”localization net”的为卷积层的实例:
如以下代码所示,该”localization net”层包括两个卷积层,并包括两个全连接层,得到仿射变换系数theta。
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
#localization net,得到仿射变换系数theta
locnet = Sequential()
locnet.add(MaxPooling2D(pool_size=(2,2), input_shape=input_shape))#
locnet.add(Convolution2D(20,5,5))
locnet.add(MaxPooling2D(pool_size=(2,2)))
locnet.add(Convolution2D(20,5,5))
locnet.add(Flatten())
locnet.add(Dense(50))
locnet.add(Activation('relu'))
locnet.add(Dense(6, weights=weights))#输出仿射变换系数theta#locnet.add(Activation('sigmoid'))
#build the model
model = Sequential()
model.add(SpatialTransformer(localization_net=locnet,
downsample_factor=3, input_shape=input_shape))#仿射变换
model.add(Convolution2D(32,3,3, border_mode='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(32,3,3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')该#localization net部分需要训练的部分为locnet部分的每一层的系数,完整代码链接如下:
(https://github.com/EderSantana/seya/blob/master/examples/Spatial%20Transformer%20Networks.ipynb)