MLP多层感知机解决了非线性问题!
结束了!就是这样!
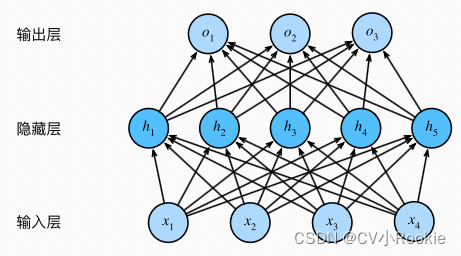
一个简单的两层MLP(关于MLP的层数,除去输入层剩下的都算作层数)的实现。
import torch
from d2l import torch as d2l
from torch import nn
batch_size, lr, num_epochs = 256, 0.1, 10
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)就这样吧,毕竟现在谁不知道神经网络!下面讲点别的。
非线性
之前讲过线性回归的向量表达长这样:,很明显这是一个线性的式子。但是生活中大多数问题是非线性的,那怎么才能实现非线性呢?
大家都知道深度学习学的是什么,其实就是拟合一个真实的函数,比如分类问题,当我们传入一张图片时,其实就是相当于给这个函数进行自变量的输入,那我们的输出就是我们最后想要的类别。如果想分类更加准确更加丰富,那这个函数就会更加的复杂,可是一个神经元只能提供下图所示的一个蓝色折线。所以就回到刚才那句话,本质就是为了用简单的函数去拟合复杂的函数!
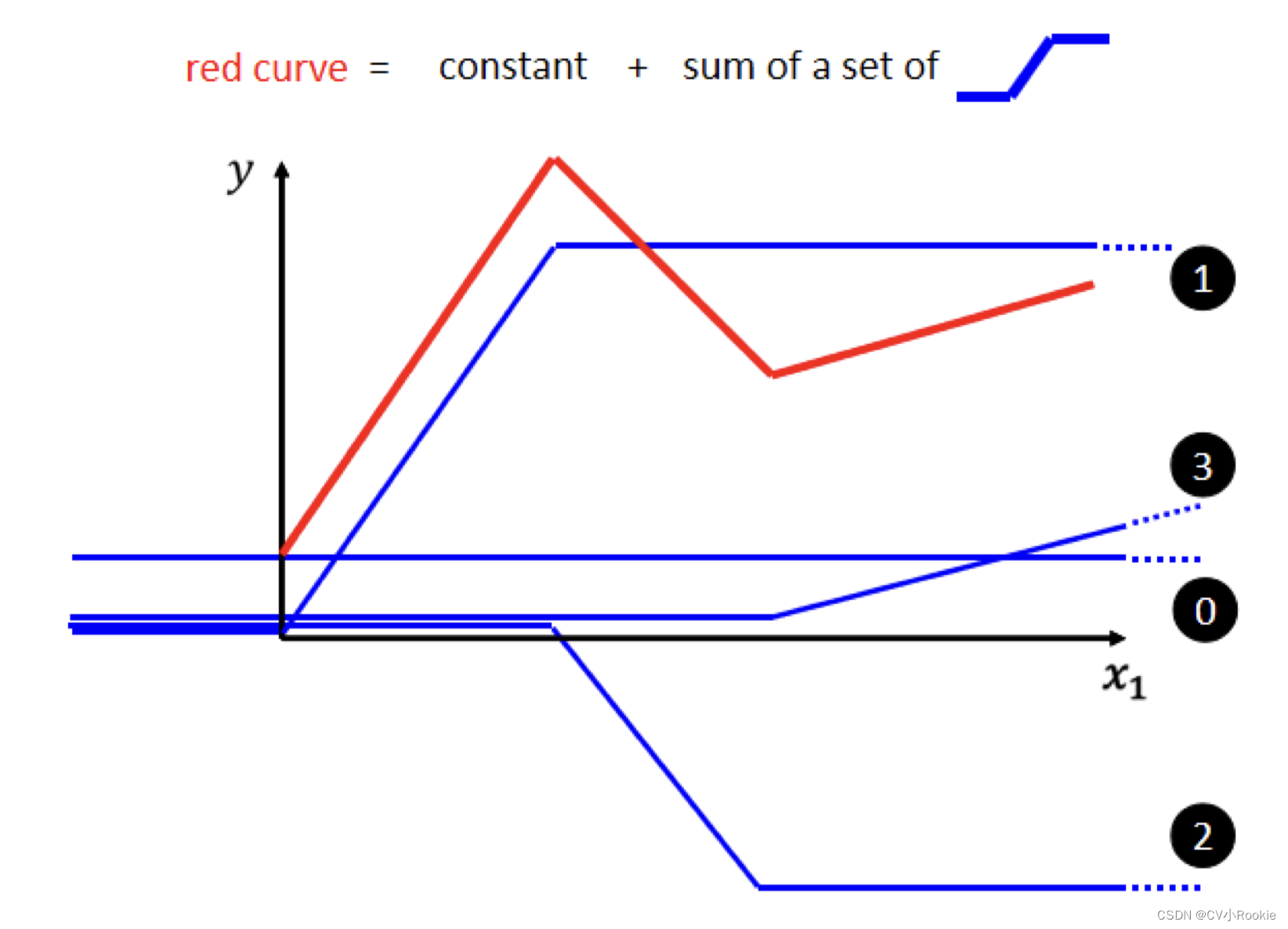
deep learning ?fat learning ?
那这里就会涉及到一个问题:那为啥要增加层数,而不是改变宽度?为啥叫 deep learning 而不是 fat learning?
可能大家都喜欢瘦一些吧(bushi)
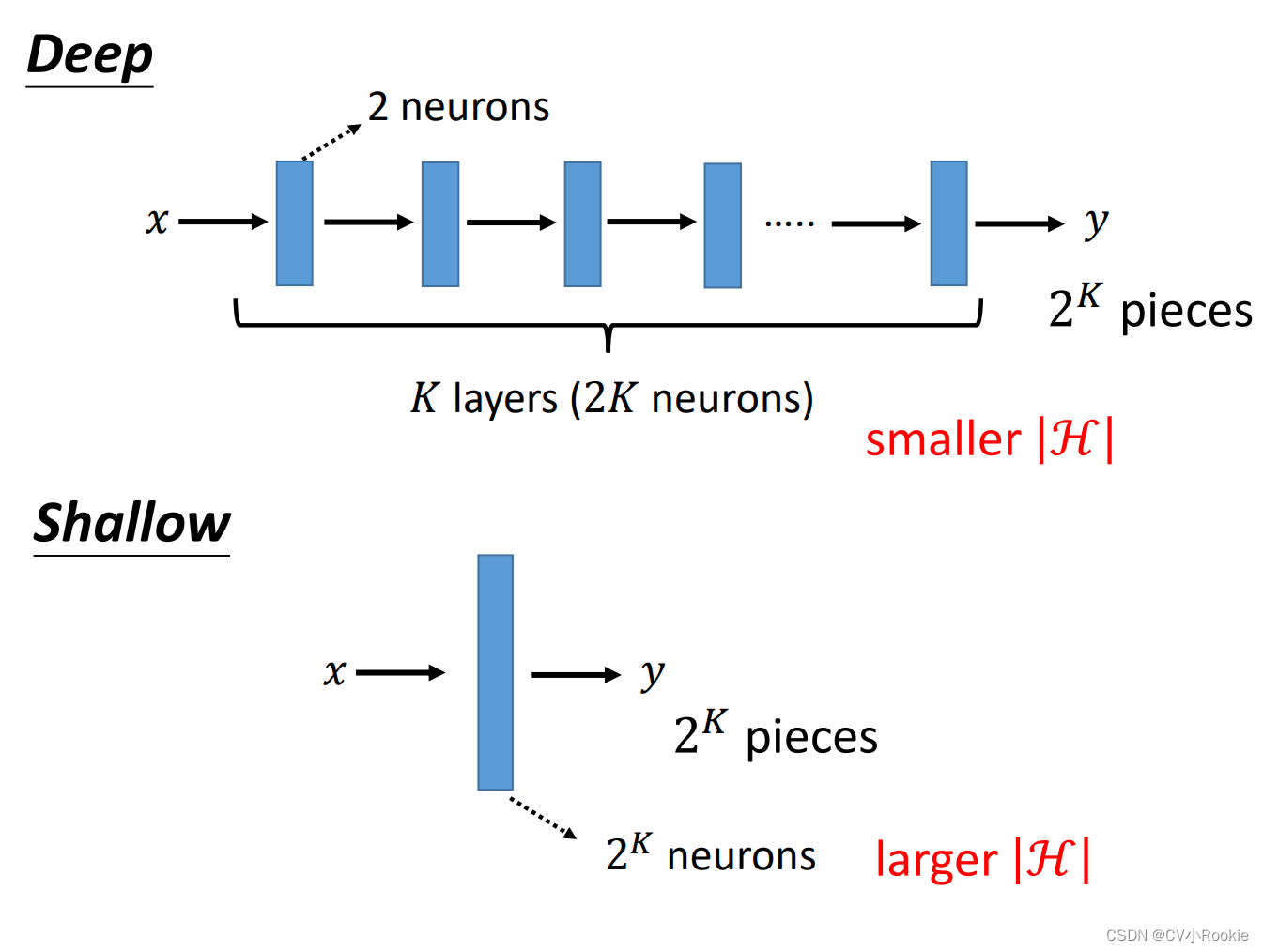
其实图上说的很清楚了,同样拟合一个函数,deep需要 2K 个neurons,而 fat需要2^k个。而且deep在实际情况中也更容易训练。
激活函数
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。
话不多说,直接公式 + 图,无须多言应该就很清晰了。
ReLU
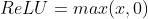
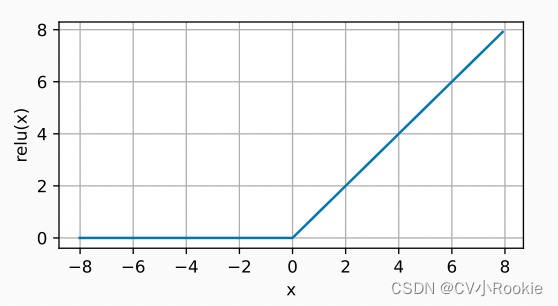
使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题
Sigmoid
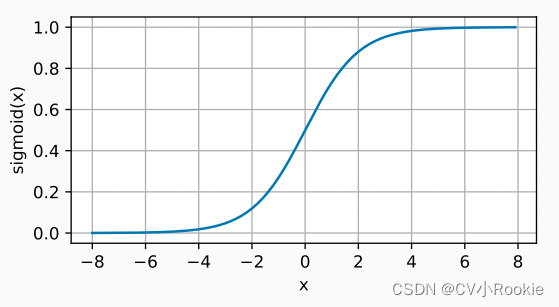
sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。 当我们想要将输出视作二元分类问题的概率时, sigmoid仍然被广泛用作输出单元上的激活函数 (你可以将sigmoid视为softmax的特例)。 然而,sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代。
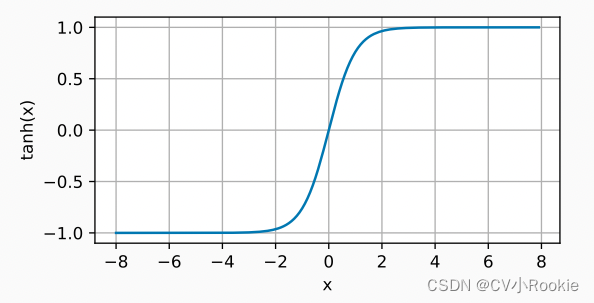
tanh