
点击关注我哦

欢迎关注 “小白玩转Python”,发现更多 “有趣”
“A little learning is a dangerous thing; drink deep or taste not Pierian Spring” (Alexander Pope)
在昨天的文章中,我们已经构建了一个非常简单和“幼稚”的神经网络,它不知道将输入映射到输出的函数。为了使网络更加智能化,我们将以“真实数据”为例对网络进行训练,然后调整网络参数(权重和偏差)。简而言之,我们通过迭代一个训练数据集,同时调整模型的参数(权重和偏差)来提高准确性。
为了找到这些参数,我们需要知道我们的网络对真实输出的预测有多差。为此,我们将计算cost,也称为loss function。
Cost
cost或loss function是我们预测误差的度量。通过最小化网络参数方面的loss,我们可以找到loss最小的状态,使得网络能够高精度地预测正确的标签。我们通过一个叫做Gradient Descent(梯度下降法)的过程找到loss的最小值。
Gradient Descent
梯度下降法需要一个 cost 函数。我们需要这个 cost 函数,因为我们需要最小化这个以获得高的预测精度。GD 的全部意义在于使 cost 函数最小化。该算法的目标是获得最低 error value 的过程。为了得到 cost 函数中的最低 error value (相对于一个权重) ,我们需要调整模型的参数。那么,我们需要调整多少参数呢?我们可以用微积分 calculus 进行计算。利用 calculus,我们可以知道函数的斜率 slope 是函数对值的导数。梯度是损失函数的斜率,指向变化最快的方向。
Backpropagation
对于单层网络,梯度下降算法的实现比较简单,而对于多层网络,则更为复杂和深入。训练多层网络是通过反向传播完成的,反向传播实际上是微积分链式规则的一个应用。如果我们把一个两层的网络转换成一个图形表示,这是最容易理解的。
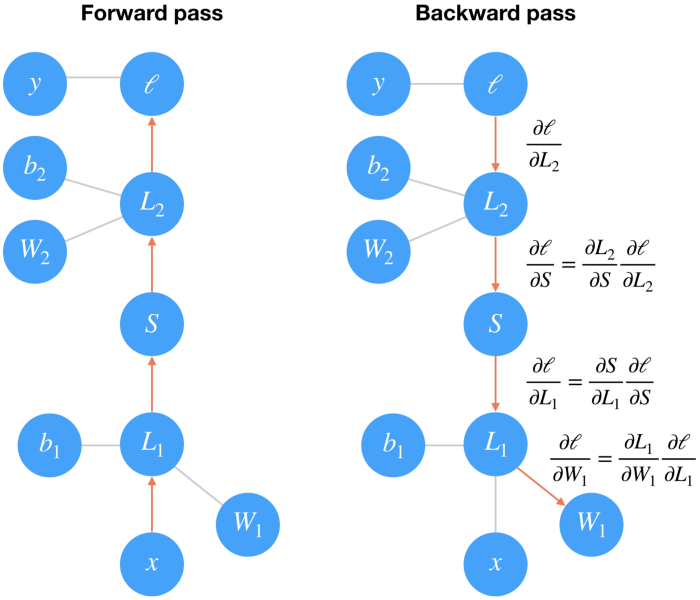
forward pass 前向传播
在前向传播中,数据和操作从底部到顶部。
步骤1: 我们将输入 x 输入一个带权重 W1和偏差 b 1的线性映射 L1中;
步骤2: 将步骤1中的输出经过 Sigmod 函数和另一个线性映射 L2 中;
步骤3:最后我们计算损失 l。
我们可以用损失来衡量网络的预测结果有多糟糕。因此,我们的目标是调整权重和偏差,以最大限度地减少损失。
Backward 向后传播
为了用梯度下降法来训练权重,我们通过网络向后传播计算梯度损失。
每个操作在输入和输出之间都有一定的梯度。
当我们向后传递梯度时,我们将输入的梯度与操作的梯度相乘。
数学上,这实际上只是使用链式法则,计算损失相对于权重的梯度。
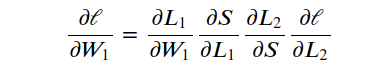
我们可以调整梯度下降过程中的学习率 α 来更新我们的权重。
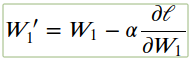
学习速率 α 的设置使得权重更新步骤足够小,以至于迭代法最小化。
PyTorch 的损失
PyTorch 提供了很多损失函数,例如交叉熵损失函数 nn.CrossEntropyLoss。对于类似 MNIST 这样的分类问题,我们使用Softmax 函数模型来预测类别概率。
为了计算损失,我们首先定义criterion ,然后传入我们的网络输出和正确的标签。
CrossEntropyLoss 标准将 nn. LogSoftmax ()和 nn.NLLLoss ()组合在一个类中。
输入应该包含每个类的得分。
Autograd
Torch 提供了一个名为 autograd 的模块来自动计算张量的梯度。这是一种计算导数的引擎。在设置计算梯度可用时,它是一个可以记录张量上所有操作的图,并创建一个称为动态计算图的无向图。这个图的叶子是输入张量,根是输出张量。
Autograd 的工作原理是跟踪张量上执行的操作,然后通过这些操作向后传播,沿着这条“路”计算梯度。
为了确保 PyTorch 跟踪一个张量的操作并计算我们需要设置requires_ grad = True。我们也可以在计算过程中使用torch.no_grad()关闭梯度计算。
训练网络
最后,我们将需要一个优化器,以使用梯度来更新权重。我们从 PyTorch 的optim库中得到这些。例如,我们可以在 optim.SGD 中使用随机梯度下降。
训练神经网络的过程:
通过网络向前传递
使用网络输出来计算损失
使用loss.backward()在网络中执行向后传播来计算梯度
与优化器一起执行更新权重的步骤
我们将为训练准备数据:
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import datasets, transforms
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
])
# Download and load the training data
trainset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)使用真实数据进行训练:
在某些术语中,遍历整个数据集的过程称为 epoch。所以在这里我们将通过 trainloader 循环获得我们的训练批次。对于每一批数据,我们将做一个训练传递,计算损失,做一个向后传递,并更新权重。
model = nn.Sequential(nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1))
# Define the loss
criterion = nn.NLLLoss()
# Optimizers require the parameters to optimize and a learning rate
optimizer = optim.SGD(model.parameters(), lr=0.003)
epochs = 5
for e in range(epochs):
running_loss = 0
for images, labels in trainloader:
# Flatten MNIST images into a 784 long vector
images = images.view(images.shape[0], -1)
# Training pass
optimizer.zero_grad()
output = model(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
else:
print(f"Training loss: {running_loss/len(trainloader)}")注意: optimizer.zero _ grad () : 当我们使用相同的参数进行多次向后传递时,梯度是累积的。这意味着我们需要在每次训练通过时将梯度归零,否则我们将保留之前训练批次的梯度。
通过训练网络,我们可以检查它的预测。
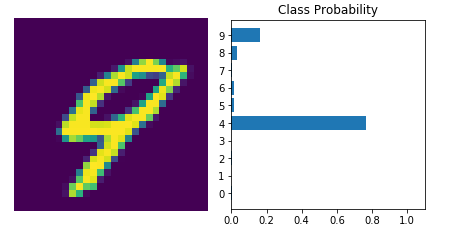
现在我们的网络是辉煌的! 它可以准确地预测我们的图像中的数字。