Hive SerDe
SerDe是Serializer/Deserializer的缩写。序列化是对象转换成字节序列的过程。反序列化是字节序列转换成对象的过程。
对象的序列化主要有两种用途:
- 对象的持久化,即把对象转换成字节序列后保存到文件。
- 对象数据的网络传输。
Hive使用SerDe接口完成IO操作也就是数据的读取和写入,hive本身并不存储数据,它用的是hdfs上存储的文件,在与hdfs的文件交互读取和写入的时候需要用到序列化和反序列化。
Hive Serde用来做序列化和反序列化,构建在数据存储和执行引擎之间,对两者实现解耦。 org.apache.hadoop.hive.serde 已经被淘汰了,现在主要使用 org.apache.hadoop.hive.serde2 ,SerDe允许Hive从表中读入数据,然后以任何自定义格式将数据写回HDFS。任何人都可以为自己的数据格式编写自己的SerDe。
所以序列化(serialize)是将导入的数据转成hadoop的Writable格式,反序列化就是将HDFS 上的数据导入到内存中形成row object,每个SQL都会有这个操作explain select count(1) from ods_user_log group byid;
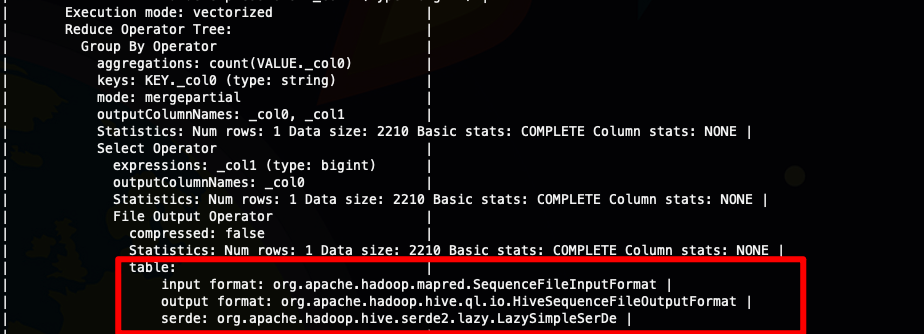
Hive 的读写流程
其实SerDe就是Hive 的序列化和反序列化的组件,主要用在读写数据上,下面就是Hive 读