
模型保存
在 Pytorch 中一种模型保存和加载的方式如下:
# save
torch.save(model.state_dict(), PATH)
# load
model = MyModel(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()可以看到模型保存的是model.state_dict() 的返回对象。model.state_dict() 的返回对象是一个OrderDict ,它以键值对的形式包含模型中需要保存下来的参数,例如:
class MyModule(nn.Module):
def __init__(self, input_size, output_size):
super(MyModule, self).__init__()
self.lin = nn.Linear(input_size, output_size)
def forward(self, x):
return self.lin(x)
module = MyModule(4, 2)
print(module.state_dict())输出结果:

模型中的参数就是线性层的 weight 和 bias.
Parameter 和 buffer
If you have parameters in your model, which should be saved and restored in the state_dict, but not trained by the optimizer, you should register them as buffers.Buffers won’t be returned in model.parameters(), so that the optimizer won’t have a change to update them.
模型中需要保存下来的参数包括两种:
- 一种是反向传播需要被optimizer更新的,称之为 parameter
- 一种是反向传播不需要被optimizer更新,称之为 buffer
第一种参数我们可以通过model.parameters() 返回;第二种参数我们可以通过model.buffers() 返回。因为我们的模型保存的是state_dict 返回的OrderDict,所以这两种参数不仅要满足是否需要被更新的要求,还需要被保存到OrderDict。
那么现在的问题是这两种参数如何创建呢,创建好了如何保存到OrderDict呢?
第一种参数有两种方式:
- 我们可以直接将模型的成员变量(http://self.xxx) 通过
nn.Parameter()创建,会自动注册到parameters中,可以通过model.parameters() 返回,并且这样创建的参数会自动保存到OrderDict中去; - 通过
nn.Parameter()创建普通Parameter对象,不作为模型的成员变量,然后将Parameter对象通过register_parameter()进行注册,可以通model.parameters()返回,注册后的参数也会自动保存到OrderDict中去;
第二种参数我们需要创建tensor, 然后将tensor通过register_buffer()进行注册,可以通model.buffers() 返回,注册完后参数也会自动保存到OrderDict中去。
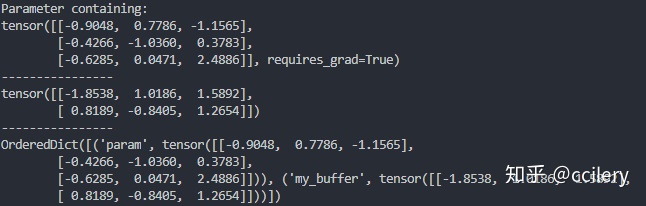
分析一个例子:
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
buffer = torch.randn(2, 3) # tensor
self.register_buffer('my_buffer', buffer)
self.param = nn.Parameter(torch.randn(3, 3)) # 模型的成员变量
def forward(self, x):
# 可以通过 self.param 和 self.my_buffer 访问
pass
model = MyModel()
for param in model.parameters():
print(param)
print("----------------")
for buffer in model.buffers():
print(buffer)
print("----------------")
print(model.state_dict())输出结果:
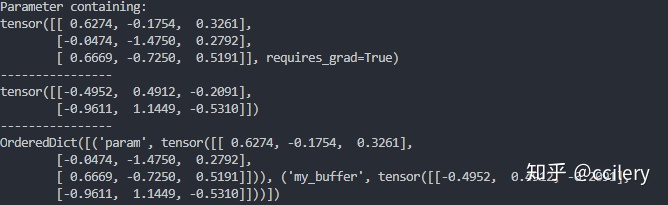
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
buffer = torch.randn(2, 3) # tensor
param = nn.Parameter(torch.randn(3, 3)) # 普通 Parameter 对象
self.register_buffer('my_buffer', buffer)
self.register_parameter("param", param)
def forward(self, x):
# 可以通过 self.param 和 self.my_buffer 访问
pass
model = MyModel()
for param in model.parameters():
print(param)
print("----------------")
for buffer in model.buffers():
print(buffer)
print("----------------")
print(model.state_dict())输出:
register_buffer的函数原型:
register_buffer(name, tensor) name: string tensor: Tensor
register_parameter的函数原型:
register_parameter(name, param) name: string param: Parameter
创建第一种参数Parameter 的这两种方式有什么区别呢?
Both approaches work the same regarding training etc.There are some differences in the function calls however. Using register_parameter you have to pass the name as a string, which can make the creation of a range of parameters convenient. Besides that I think it's just coding style which one you prefer.
到这里我有两个疑问:
疑问1:为什么不把参数都设置为nn.Parameter类型,只是把不需要更新参数的设置 requires_grad=False?
疑问2:为什么不直接将不需要进行参数修改的变量作为模型类的成员变量就好了,还要进行注册?
对于疑问1我没找到答案,疑问2有两个原因:
- 不进行注册,参数不能保存到
OrderDict,也就无法进行保存 - 模型进行参数在CPU和GPU移动时, 执行
model.to(device),注册后的参数也会自动进行设备移动
看一个例子:
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.my_tensor = torch.randn(1) # 参数直接作为模型类成员变量
self.register_buffer('my_buffer', torch.randn(1)) # 参数注册为 buffer
self.my_param = nn.Parameter(torch.randn(1))
def forward(self, x):
return x
model = MyModel()
print(model.state_dict())
model.cuda()
print(model.my_tensor)
print(model.my_buffer)输出结果:

可以看到模型类的成员变量不在OrderDict中,不能进行保存;模型在进行设备移动时,模型类的成员变量没有进行移动。
实际应用
以 transformer 中 的embedding layer 作为例子进行展示,在 "Attention is all you need" 论文中,作者对position embedding使用了固定设置:
class Embeddings(nn.Module):
def __init__(self, vocab_size, d_model, dropout=0.1, max_len=5000):
"""
Args:
vocab_size: 词典大小
d_model: 词向量维度
dropout: dropout比例
max_len: 输入序列的最大长度
"""
super(Embeddings, self).__init__()
self.embs = nn.Embedding(vocab_size, d_model) # word embedding, 反向传播需要更新
self.d_model = d_model
self.dropout = nn.Dropout(dropout)
# pe shape: (0, max_len, d_model)
pe = self._build_position_encoding(max_len, d_model)
self.register_buffer("pe", pe) # position encoding,反向传播不需要更新
def forward(self, x):
"""
Args:
x: (batch_size, seq_len)
Returns:
embed: (batch_size, seq_len, d_model)
"""
# word embedding + position encoding
embed = self.embs(x) * math.sqrt(self.d_model) + self.pe[:, :x.size(1)]
embed = self.dropout(embed)
return embed
def _build_position_encoding(self, max_len, d_model):
pe = torch.zeros(max_len, d_model)
position = torch.arange(max_len, dtype=torch.float).unsqueeze(1) # shape: (max_len, 1)
div_term = torch.exp(-torch.arange(0, d_model, 2, dtype=torch.float) * math.log(10000) / d_model) # shape: (1, ceil(d_model/2))
pe[:, 0::2] = torch.sin(position * div_term)
# d_model为偶数, 则sin 和 cos 列数相同
# d_model为奇数, 则cos 比 sin 少一列
pe[:, 1::2] = torch.cos(position * div_term) if d_model % 2 == 0 else torch.cos(position * div_term[:-1])
pe = pe.unsqueeze(0)
return pe
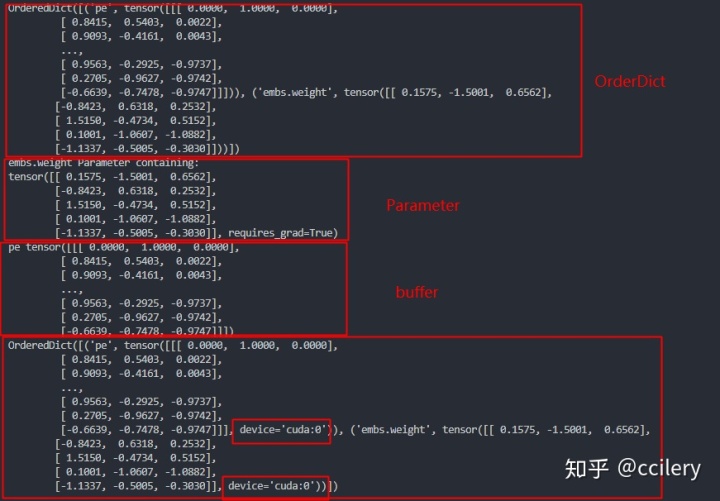
model = Embeddings(5, 3)
print(model.state_dict())
for name, para in model.named_parameters():
print(name, para)
for name, buffer in model.named_buffers():
print(name, buffer)
model.cuda()
print(model.state_dict())输出结果:
总结
- 模型中需要进行更新的参数注册为Parameter,不需要进行更新的参数注册为buffer
- 模型保存的参数是
model.state_dict()返回的OrderDict - 模型进行设备移动时,模型中注册的参数(Parameter和buffer)会同时进行移动
参考:
- https://discuss.pytorch.org/t/what-is-the-difference-between-register-buffer-and-register-parameter-of-nn-module/32723
- https://blog.csdn.net/Hungryof/article/details/82017595